在Fresco源码赏析 之基本流程中把setImageUrl()方法调用后是如何自动完成剩下的事情的步骤的流程理了一遍,基本可以知道了大体的整个流程,看这个点这里:
点击打开链接
在Fresco源码赏析 之图片显示流程 把获取数据后是如何完成ui的刷新、Fresco封装的控件是如何封装管理drawable简单了说清楚了,看这个文点击这里:
点击打开链接
本文主要是最后的一篇分析了,主要是再具体看看Fresco启动后台获取数据的流程,在Fresco源码赏析 之基本流程中并没有讲的很清楚,源码还是比较复杂的,可能分析得不到位,欢迎交流学习。
根据前面两文,知道了一点是,Fresco获取数据的过程分成了不同的producer进行不同的任务,他们之间通过consumer进行数据传递,这个有的类似与职责链模式,不同的producer有不同的职责,它复杂找缓存、它负责编码、它负责获取网络数据、、等等。我简单画了个图:
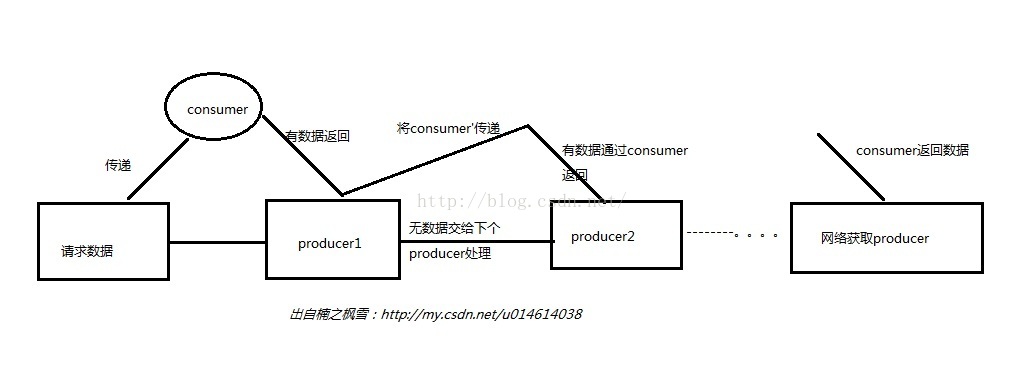
这个是简单大概的图,可以概括说明了Fresco获取数据的整个流程思路,事实上会比这个复杂多,如图示,每个producer其实就是复杂一个职责的工作,有些是获取缓存数据,也有些进行编码、进行缓存、进行网络获取等等,一开始请求数据后应该是去缓存获取producer1那里请求数据,有就直接返回不会进行下面的操作,没有缓存获取producer1会交给下一个producer处理,以此类推下去,最终不得已只好去获取网络数据,这期间包含一系列的producer,形成一条职责链,完成了整个获取数据的过程。
我们看看请求数据的入口:
@Override
protected DataSource<CloseableReference<CloseableImage>> getDataSourceForRequest(
ImageRequest imageRequest,
Object callerContext,
boolean bitmapCacheOnly) {
if (bitmapCacheOnly) {
return mImagePipeline.fetchImageFromBitmapCache(imageRequest, callerContext);
} else {
return mImagePipeline.fetchDecodedImage(imageRequest, callerContext);
}
}我们略过跳的获取网络数据的那个方法里,具体请看在Fresco源码赏析 之基本流程:
/**
* swallow result if prefetch -> bitmap cache get -> wait if scrolling ->
* background thread hand-off -> multiplex -> bitmap cache -> decode -> multiplex ->
* encoded cache -> disk cache -> (webp transcode) -> network fetch.
*/
private synchronized Producer<CloseableReference<CloseableImage>> getNetworkFetchSequence() {
if (mNetworkFetchSequence == null) {
mNetworkFetchSequence =
newBitmapCacheGetToDecodeSequence(getCommonNetworkFetchToEncodedMemorySequence());
}
return mNetworkFetchSequence;
}
这里返回的是一个网络获取的producer,事实上是多个producer的链,这里返回的只是链头而已,最终从链头走到链为,这个过程可能中断也可能完全走完,但是从代码上看的画,这个链肯定是完整 ,newBitmapCacheGetToDecodeSequence返回的是一个producer,它的下个pruducer是getCommonNetworkFetchToEncodedMemorySequence()返回的pruducer,我们具体看看这两个方法:
先看前一个:
/**
* Same as {@code newBitmapCacheGetToBitmapCacheSequence} but with an extra DecodeProducer.
* @param nextProducer next producer in the sequence after decode
* @return bitmap cache get to decode sequence
*/
private Producer<CloseableReference<CloseableImage>> newBitmapCacheGetToDecodeSequence(
Producer<CloseableReference<PooledByteBuffer>> nextProducer) {
DecodeProducer decodeProducer = mProducerFactory.newDecodeProducer(nextProducer);//这个是对图片数据进行编码,并用一些比较复杂的算法进行扫描处理
return newBitmapCacheGetToBitmapCacheSequence(decodeProducer);
}/**
* Bitmap cache get -> wait if scrolling -> thread hand off -> multiplex -> bitmap cache
* @param nextProducer next producer in the sequence after bitmap cache
* @return bitmap cache get to bitmap cache sequence
*/
private Producer<CloseableReference<CloseableImage>> newBitmapCacheGetToBitmapCacheSequence(
Producer<CloseableReference<CloseableImage>> nextProducer) {
BitmapMemoryCacheProducer bitmapMemoryCacheProducer =
mProducerFactory.newBitmapMemoryCacheProducer(nextProducer);//这个是去bitmap缓存找有没有缓存,并且如果需要缓存的话将数据缓存并复制一份数据,将复制的数据返回
BitmapMemoryCacheKeyMultiplexProducer bitmapKeyMultiplexProducer =
mProducerFactory.newBitmapMemoryCacheKeyMultiplexProducer(bitmapMemoryCacheProducer);//这个是合并请求,如何多个请求获取的是同一张图片的画将请求合并成一个,为了只保存一份数据
ThreadHandoffProducer<CloseableReference<CloseableImage>> threadHandoffProducer =
mProducerFactory.newBackgroundThreadHandoffProducer(bitmapKeyMultiplexProducer);//这个是启动线程,让接下来的pruducer全都在线程中执行
return mProducerFactory.newBitmapMemoryCacheGetProducer(threadHandoffProducer);//这个是单纯去bitmap缓存找有没有数据
}看到方法传入的参数没有,nextProducer,就是说传入的producer是下一个职责负责的producer,就是当前producer完成后如果有必要就交给下个producer处理,比如找了发现没有缓存数据,那么就交给图片数据编码的producer处理,它就不管了。同理mProducerFactory传入的参数名也叫nextproducer,就是它创建的那个producer的下一个producer就是传入的那个,这样下来就形成了一个完整的链了。
看后一个方法:
/**
* multiplex -> encoded cache -> disk cache -> (webp transcode) -> network fetch.
*/
private synchronized Producer<CloseableReference<PooledByteBuffer>>
getCommonNetworkFetchToEncodedMemorySequence() {
if (mCommonNetworkFetchToEncodedMemorySequence == null) {
mCommonNetworkFetchToEncodedMemorySequence =
newEncodedCacheMultiplexToTranscodeSequence(mNetworkFetchProducer, /* isLocal */false);
if (mResizeAndRotateEnabledForNetwork) {
mCommonNetworkFetchToEncodedMemorySequence =
newResizeAndRotateImagesSequence(mCommonNetworkFetchToEncodedMemorySequence);
}
}
return mCommonNetworkFetchToEncodedMemorySequence;
}
其实这个mNetworkFetchProducer才是最后发起网络请求进行数据获取的producer,这样标志一下。
/**
* encoded cache multiplex -> encoded cache -> (disk cache) -> (webp transcode)
* @param nextProducer next producer in the sequence
* @param isLocal whether the image source is local or not
* @return encoded cache multiplex to webp transcode sequence
*/
private Producer<CloseableReference<PooledByteBuffer>>
newEncodedCacheMultiplexToTranscodeSequence(
Producer<CloseableReference<PooledByteBuffer>> nextProducer,
boolean isLocal) {
if (Build.VERSION.SDK_INT < Build.VERSION_CODES.JELLY_BEAN_MR2) {
nextProducer = mProducerFactory.newWebpTranscodeProducer(nextProducer);//将获取到的图片转码
}
if (!isLocal) {
nextProducer = mProducerFactory.newDiskCacheProducer(nextProducer);//将获取到的数据缓存到硬盘
}
EncodedMemoryCacheProducer encodedMemoryCacheProducer =
mProducerFactory.newEncodedMemoryCacheProducer(nextProducer);//根据编码后的缓存路径寻找有没有编码后的缓存,有就返回没有就进行下一步
return mProducerFactory.newEncodedCacheKeyMultiplexProducer(encodedMemoryCacheProducer);//根据编码后的缓存的图片请求路径,对于同一个图片路径的不同缓存的不同请求合并成一个
}根据上面的两个方法,我简单整理了一下整个职责链:
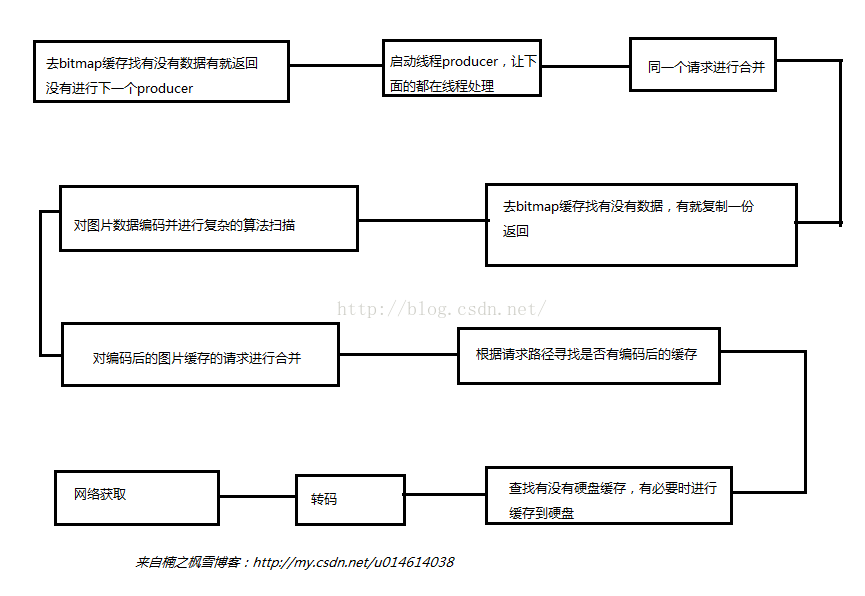
是不是感觉有的怪,事实上有些producer不是在上一个producer传递下来时执行的,它是在数据返回时执行的比如编码、转码之类的,这个实现就是通过consumer实现的,consumer说是传递在整个链里面,实现它在必要的producer中会重新创建一个进行对数据返回时的拦截并进行相应的处理,如缓存producer,没有缓存的时候应该是去获取网络数据,进行这步有什么意义?其实它在这里做的缓存处理只是在consumer数据回调时对数据进行缓存,它的做法就是创建一个新的consumer,将新的consumer传递到下一个producer,最终数据通过这个新的consumer返回回来,它获取到数据后进行缓存处理,处理完通过就的consumer返回回去。我个人觉得这样的设计非常巧妙,让所有的producer衔接起来。
下面是缓存producer在上个producer传递下来执行的操作:
@Override
public void produceResults(final Consumer<CloseableReference<T>> consumer, final ProducerContext producerContext) {
final ProducerListener listener = producerContext.getListener();
final String requestId = producerContext.getId();
listener.onProducerStart(requestId, getProducerName());
final K cacheKey = getCacheKey(producerContext.getImageRequest());
CloseableReference<T> cachedReference = mMemoryCache.get(cacheKey, null);
if (cachedReference != null) {// 不为空说明拿到的内存的缓存数据
boolean shouldStartNextProducer = shouldStartNextProducer(cachedReference);
if (!shouldStartNextProducer) {// 是否进行下一个produder操作,不需要就将结果返回当前的producer
listener.onProducerFinishWithSuccess(requestId, getProducerName(),
listener.requiresExtraMap(requestId) ? ImmutableMap.of(CACHED_VALUE_FOUND, "true") : null);
}
consumer.onNewResult(cachedReference, !shouldStartNextProducer);
cachedReference.close();
if (!shouldStartNextProducer) {
return;
}
}
// 当内存缓存没有数据说明内存数据清掉了,进行下个操作
Consumer<CloseableReference<T>> consumerOfNextProducer;// 下一个生存者的消费者,生存者主要是用来进行获取数据的操作,消费者主要是用于处理数据的操作
if (!shouldCacheReturnedValues()) {//如果当前生存者的消费者不需要进行数据处理,就将当前消费者指定为下个生存者的消费者,否则进行数据处理
consumerOfNextProducer = consumer;
} else {
//必要的时候创建了一个新的consumer传递下去,这样对就可以对数据进行拦截
consumerOfNextProducer = new BaseConsumer<CloseableReference<T>>() {
@Override
public void onNewResultImpl(CloseableReference<T> newResult, boolean isLast) {
CloseableReference<T> cachedResult = null;//newResult这个结果是下面的生存者传递回来的数据,然后将数据返回给前一个消费者
if (newResult != null && shouldCacheResult(newResult, cacheKey, isLast)) {
cachedResult = mMemoryCache.cache(cacheKey, newResult);
}
if (cachedResult != null) {//缓存操作后通过旧的consumer将数据返回回去
consumer.onNewResult(cachedResult, isLast);
cachedResult.close();
} else {
consumer.onNewResult(newResult, isLast);
}
}
@Override
public void onFailureImpl(Throwable t) {
consumer.onFailure(t);
}
@Override
protected void onCancellationImpl() {
consumer.onCancellation();
}
};
}
listener.onProducerFinishWithSuccess(requestId, getProducerName(),
listener.requiresExtraMap(requestId) ? ImmutableMap.of(CACHED_VALUE_FOUND, "false") : null);
mNextProducer.produceResults(consumerOfNextProducer, producerContext);//这里进行跳转到下个生存者
}所以去实际上本身的职责工作是在数据返回时才进行,其他有些producer也是类似的做法。
好啦,producer的流程大概说明白了,其每个producer具体实现就不说了,毕竟太多了,根据这个思路去看很容易就看明白了。
转载请注明出处:http://blog.csdn.net/u014614038/article/details/51507236
最后
以上就是玩命自行车最近收集整理的关于Fresco源码赏析之后台获取流程的全部内容,更多相关Fresco源码赏析之后台获取流程内容请搜索靠谱客的其他文章。








发表评论 取消回复