1、背景
由于多表join场景下和旅行商问题场景非常相似,故可以用DP来解决。
目前Spark CBO中的JoinReorders只会用DP处理默认深度<=12的join场景,而在[SPARK-27714]中提出了可以用类似于Postgre SQL的GEQO来实现深度较深场景下的JoinReorder(非本文重点,会在后续文章中分析实现)。
2、Code
CostBasedJoinReorder入口,只匹配inner join,然后reorder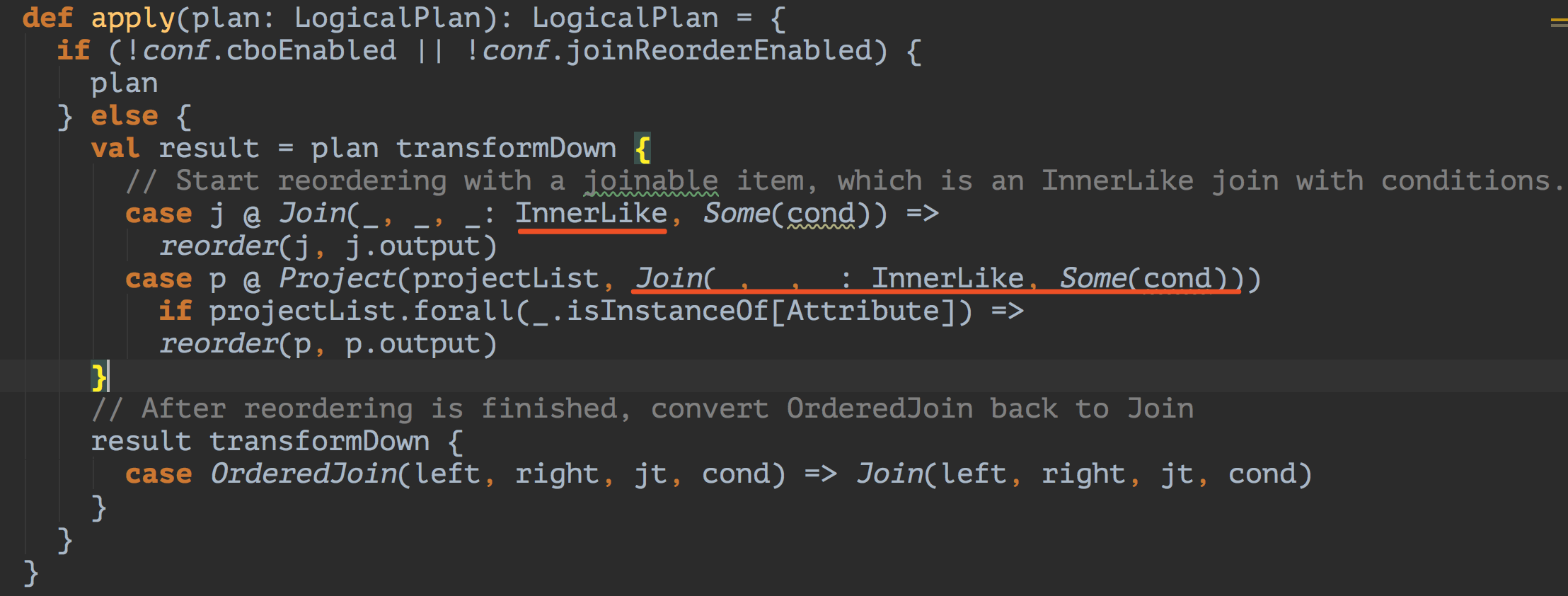
reorder中树的深度在(2,`spark.sql.cbo.joinReorder.dp.threshold`]范围内,才会进入dp,否则直接返回(说好的决策树呢??)
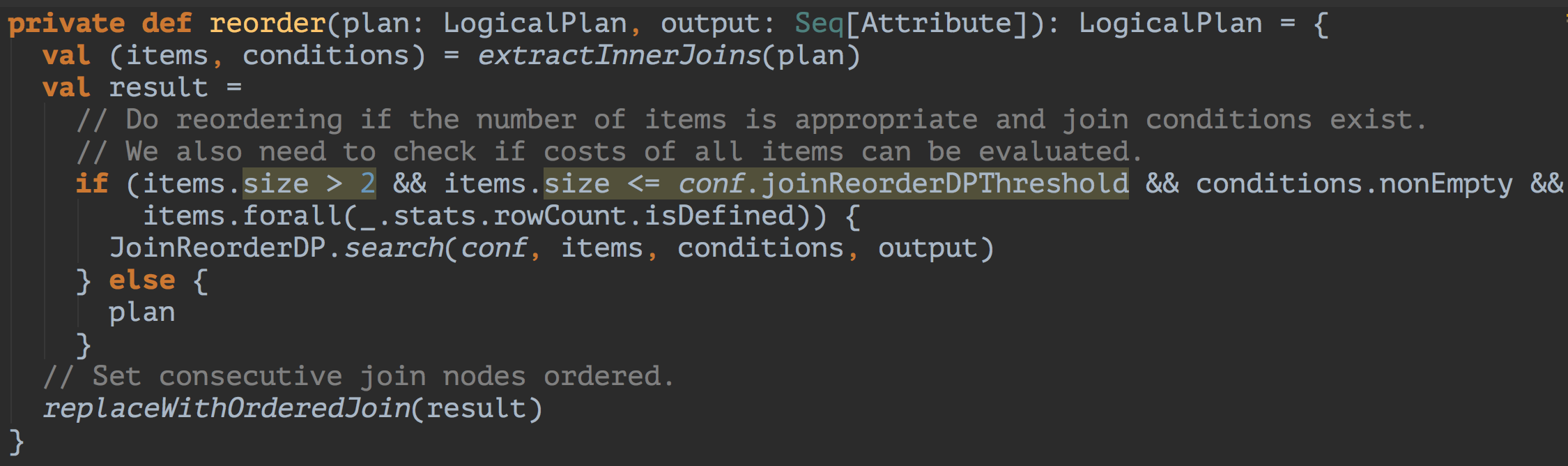
dp核心思想参考了论文http://www.inf.ed.ac.uk/teaching/courses/adbs/AccessPath.pdf
在multi-way join中,由低level到高level逐步推算并保证Cost最小。
def search(
conf: SQLConf,
items: Seq[LogicalPlan],
conditions: Set[Expression],
output: Seq[Attribute]): LogicalPlan = {
val startTime = System.nanoTime()
// Level i maintains all found plans for i + 1 items.
// Create the initial plans: each plan is a single item with zero cost.
val itemIndex = items.zipWithIndex
val foundPlans = mutable.Buffer[JoinPlanMap](itemIndex.map {
case (item, id) => Set(id) -> JoinPlan(Set(id), item, Set.empty, Cost(0, 0))
}.toMap)
// Build filters from the join graph to be used by the search algorithm.
val filters = JoinReorderDPFilters.buildJoinGraphInfo(conf, items, conditions, itemIndex)
// Build plans for next levels until the last level has only one plan. This plan contains
// all items that can be joined, so there's no need to continue.
val topOutputSet = AttributeSet(output)
while (foundPlans.size < items.length) {
// Build plans for the next level.
foundPlans += searchLevel(foundPlans, conf, conditions, topOutputSet, filters)
}
val durationInMs = (System.nanoTime() - startTime) / (1000 * 1000)
logDebug(s"Join reordering finished. Duration: $durationInMs ms, number of items: " +
s"${items.length}, number of plans in memo: ${foundPlans.map(_.size).sum}")
// The last level must have one and only one plan, because all items are joinable.
assert(foundPlans.size == items.length && foundPlans.last.size == 1)
foundPlans.last.head._2.plan match {
case p @ Project(projectList, j: Join) if projectList != output =>
assert(topOutputSet == p.outputSet)
// Keep the same order of final output attributes.
p.copy(projectList = output)
case finalPlan =>
finalPlan
}
}
注释中有一个例子:

继续看其核心方法searchLevel->buildJoin
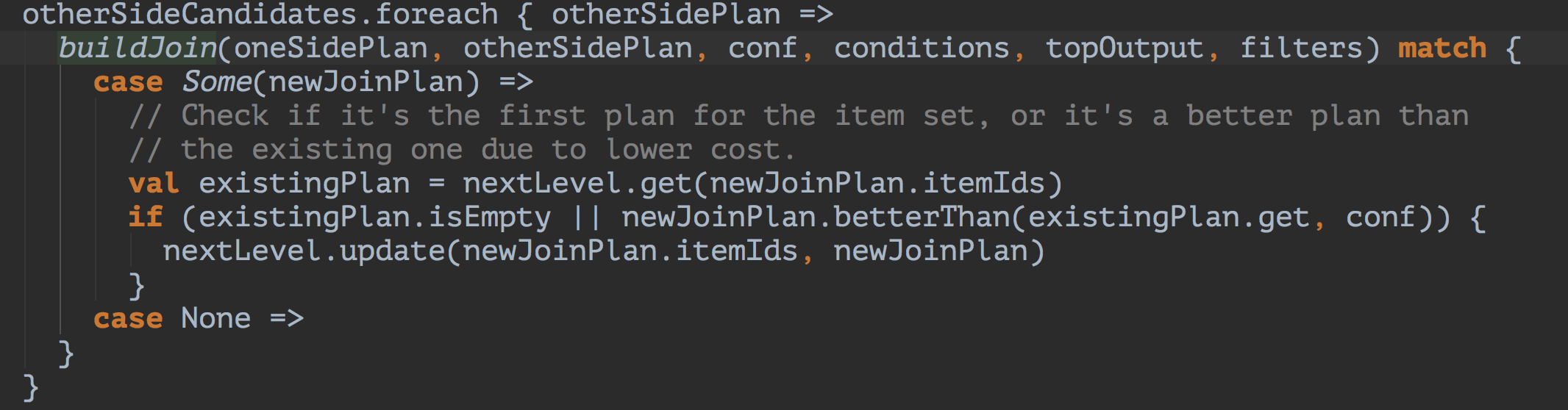
star-join优化:
if star-join filter is enabled, allow the following combinations:
1) (oneJoinPlan U otherJoinPlan) is a subset of star-join
2) star-join is a subset of (oneJoinPlan U otherJoinPlan)
3) (oneJoinPlan U otherJoinPlan) is a subset of non star-join
最后
以上就是开朗汉堡最近收集整理的关于Spark CBO CostBasedJoinReorder源码解析1、背景2、Code的全部内容,更多相关Spark内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复