本机环境为
java:jdk-8u251-linux-x64.tar jdk下载链接
ubuntu:ubuntu-18.04.4-desktop-amd64
hadoop:hadoop-3.2.0.tar hadoop
mysql:5.7.30 ubuntu安装
JDBC:mysql-connector-java-5.1.47.tar JDBC
hive:apache-hive-3.1.2-bin.tar hive下载 快速下载地址
一、准备工作
创建Hadoop用户
sudo useradd -m hadoop -s /bin/bash #创建hadoop用户,并使用/bin/bash作为shell
sudo passwd hadoop #为hadoop用户设置密码
sudo adduser hadoop sudo #为hadoop用户增加管理员权限
su - hadoop #切换当前用户为用户hadoop
sudo apt-get update #更新hadoop用户安装SSH
sudo apt-get install openssh-server #安装SSH server
ssh localhost #登陆SSH,第一次登陆输入yes
exit #退出登录的ssh localhost
cd ~/.ssh/ #如果没法进入该目录,执行一次ssh localhost
ssh-keygen -t rsa第一次回车是让KEY存于默认位置,以方便后续的命令输入。
第二次和第三次是确定passphrase。
cat ./id_rsa.pub >> ./authorized_keys #加入授权
ssh localhost #此时已不需密码即可登录localhost,并可见下图。如果失败则可以搜索SSH免密码登录来寻求答案二、安装JDK
sudo tar zxvf jdk*** -C /opt/ #/解压到/usr/lib/jvm目录下
sudo mv /opt/jdk* java #重命名为java
sudo vim ~/.bashrc #给JDK配置用户环境变量
or
sudo vim /etc/profile #给JDK配置系统环境变量#Java Environment
export JAVA_HOME=/opt/java
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATHsource ~/.bashrc
or
source /etc /profile
java -version #检测是否安装成功,查看java版本三、安装Hadoop
sudo tar -zxvf hadoop-3.2.0.tar.gz -C /opt/ #解压到/usr/local目录下
sudo mv /opt/hadoop-3.2.0 hadoop #重命名为hadoop
sudo chown -R hadoop ./hadoop #修改文件权限#Hadoop Environment
export HADOOP_HOME=/opt/hadoop
export CLASSPATH=$($HADOOP_HOME/bin/hadoop classpath):$CLASSPATH
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin四、伪分布式配置
Hadoop 可以在单节点上以伪分布式的方式运行,Hadoop 进程以分离的 Java 进程来运行,节点既作为 NameNode 也作为 DataNode。
同时,读取的是 HDFS 中的文件。Hadoop 的配置文件位于 /usr/local/hadoop/etc/hadoop/ 中,伪分布式需要修改2个配置文件core-site.xml和hdfs-site.xml以及一个路径变量hadoop-env.sh
vim hadoop-env.sh
export JAVA_HOME=/opt/javavim core-site.xml
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>vim hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/hadoop/tmp/dfs/data</value>
</property>
<property>
<name>dfs.http.address</name>
<value>0.0.0.0:50070</value>
</property>
</configuration>Hadoop 的运行方式是由配置文件决定的(运行 Hadoop 时会读取配置文件),因此如果需要从伪分布式模式切换回非分布式模式,需要删除 core-site.xml 中的配置项。
此外,伪分布式虽然只需要配置fs.defaultfs和dfs.replication就可以运行(可参考官方教程),不过若没有配置hadoop.tmp.dir参数,则默认使用的临时目录为/tmp/hadoop,而这个目录在重启时有可能被系统清理掉,导致必须重新执行format才行。所以我们进行了设置,同时也指定dfs.namenode.name.dir和dfs.datanode.data.dir,否则在接下来的步骤中可能会出错。
执行 NameNode 的格式化
./bin/hdfs namenode -format启动namenode和datanode进程,并查看启动结果
$ ./sbin/start-dfs.sh
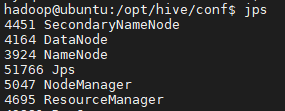
$ jps启动完成后,可以通过命令 jps 来判断是否成功启动,若成功启动则会列出如下进程: “NameNode”、”DataNode” 和 “SecondaryNameNode”
此时也有可能出现要求输入localhost密码的情况 ,如果此时明明输入的是正确的密码却仍无法登入,其原因是由于如果不输入用户名的时候默认的是root用户,但是安全期间ssh服务默认没有开root用户的ssh权限.
$vim /etc/ssh/sshd_config检查PermitRootLogin 后面是否为yes,如果不是,则将该行代码 中PermitRootLogin 后面的内容删除,改为yes,保存。之后输入下列代码重启SSH服务
$ /etc/init.d/sshd restart五、安装mysql
ubuntu 18下默认的mysql是5.7
apt-cache search mysql | grep mysql-serve
sudo apt-get install mysql-server给账号权限
可以直接用root账户
sudo mysql -u root
GRANT ALL PRIVILEGES ON *.* TO root@'%' IDENTIFIED BY "hive";
select user, plugin from mysql.user;
update mysql.user set authentication_string=PASSWORD('hive'), plugin='mysql_native_password' where user='root';
flush privileges;
sudo service mysql restart也可以创建一个hive账户
mysql -u root -p
create database hive;
use hive;
create table user(Host char(20),User char(10),Password char(20));
insert into user(Host,User,Password) values("localhost","hive","hive");
GRANT ALL PRIVILEGES ON *.* TO 'hive'@'localhost' IDENTIFIED BY 'hive';
flush privileges;
sudo service mysql restart六、安装Hive
$ sudo tar zxf apache-hive-3.1.2-bin.tar.gz -C /opt/
$ sudo mv /opt/apache-hive-3.1.2-bin /opt/hivevim ~/.bashrc
vim /etc/profile
#Hive Enviroment
export HIVE_HOME=/opt/hive
export PATH=$PATH:$HIVE_HOME/bin
source ~/.bashrc
source /etc/profile
所有Hive的配置是在/opt/hive/conf目录下,进入这个目录,我们需要先基于模板新建hive-env.sh文件:
cp hive-env.sh.template hive-env.sh
sudo chmod 777 hive-env.sh
vim hive-env.shHADOOP_HOME=/opt/hadoopcp hive-default.xml.template hive-site.xml
sudo chmod 777 hive-site.xml
vim hive-site.xml可用vim下/或者?关键字,进行搜索
修改连接配置:
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true&useSSL=false</value>
<description>JDBC connect string for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
<description>Driver class name for a JDBC metastore</description>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root or hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
<description>password to use against metastore database</description>
</property>
修改临时文件夹的路径,改为自己设置路径:
<property>
<name>hive.exec.local.scratchdir</name>
<value>/home/hadoop/hdp</value>
<description>Local scratch space for Hive jobs</description>
</property>
<property>
<name>hive.downloaded.resources.dir</name>
<value>/home/hadoop/hdp</value>
<description>Temporary local directory for added resources in the remote file system.</description>
</property>
mkdir -p /home/hadoop/hdp
chmod -R 775 /home/hadoop/hdp 异常处理 将 换成 #8
sudo chmod 777 /opt/hive/bin/hive-config.sh
vim /opt/hive/bin/hive-config.sh
export JAVA_HOME=opt/java
export HADOOP_HOME=/opt/hadoop
export HIVE_HOME=/opt/hive接下来将JDBC驱动移动到master服务器上
tar -zxvf mysql-connector-java-5.1.47.tar.gz
cp mysql-connector-java-5.1.47/mysql-connector-java-5.1.40-bin.jar /opt/hive/lib/启动Hadoop,在Hadoop中创建Hive需要用到的目录并设置好权限:
hadoop fs -mkdir /tmp
hadoop fs -chmod g+w /tmp 初始化meta数据库
$ cd /opt/hive/bin
$ ./schematool -dbType mysql -initSchema
$ ./schematool -dbType mysql -info
$ hive开启hive三步骤:
#开启hadoop
cd /opt/hadoop/
./sbin/start-all.sh
#开启hive
hive参考文章:
https://zhuanlan.zhihu.com/p/107497771
https://zhuanlan.zhihu.com/p/27882223
https://zhuanlan.zhihu.com/p/146432186
最后
以上就是敏感小天鹅最近收集整理的关于ubuntu搭建hadoop、mysql、hive环境本机环境为的全部内容,更多相关ubuntu搭建hadoop、mysql、hive环境本机环境为内容请搜索靠谱客的其他文章。








发表评论 取消回复