文章目录
- 简介及类图
- TupleDesc.java
- Tuple.java
- Catalog.java
- BufferPool.java
- SeqSacn.java
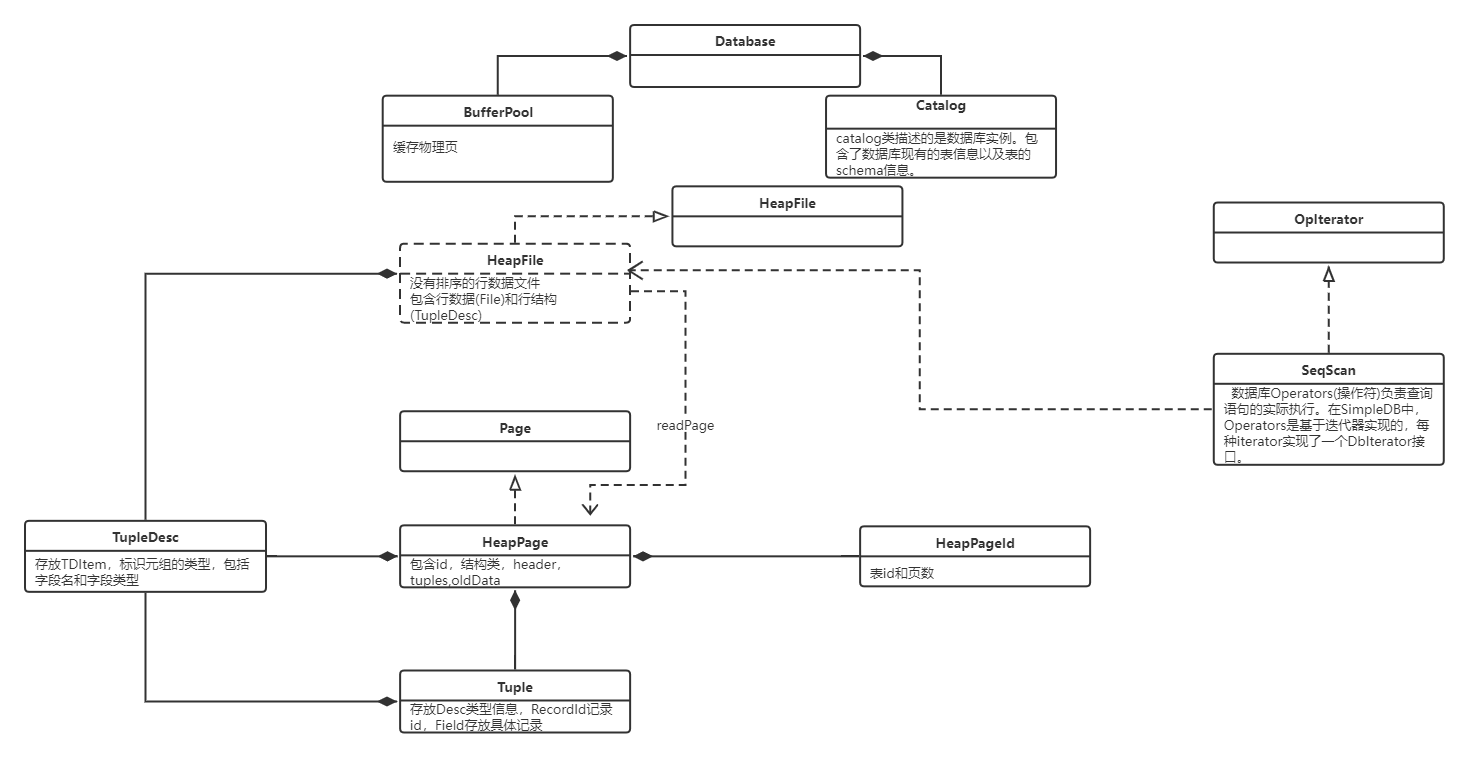
简介及类图
第一个lab主要是熟悉一下项目结构,完善一下几个简单的基础类,除了SeqScan需要自己写Iterator之外难度不大
TupleDesc.java
package simpledb.storage;
import simpledb.common.Type;
import java.io.Serializable;
import java.util.*;
/**
* TupleDesc describes the schema of a tuple.
*/
public class TupleDesc implements Serializable {
private final TDItem[] tdItems;
/**
* A help class to facilitate organizing the information of each field
* */
public static class TDItem implements Serializable {
private static final long serialVersionUID = 1L;
/**
* The type of the field
* */
public final Type fieldType;
/**
* The name of the field
* */
public final String fieldName;
public TDItem(Type t, String n) {
this.fieldName = n;
this.fieldType = t;
}
public String toString() {
return fieldName + "(" + fieldType + ")";
}
}
/**
* @return
* An iterator which iterates over all the field TDItems
* that are included in this TupleDesc
* */
public Iterator<TDItem> iterator() {
// some code goes here
return null;
}
private static final long serialVersionUID = 1L;
/**
* Create a new TupleDesc with typeAr.length fields with fields of the
* specified types, with associated named fields.
*
* @param typeAr
* array specifying the number of and types of fields in this
* TupleDesc. It must contain at least one entry.
* @param fieldAr
* array specifying the names of the fields. Note that names may
* be null.
*/
public TupleDesc(Type[] typeAr, String[] fieldAr) {
// some code goes here
tdItems = new TDItem[typeAr.length];
for(int i=0;i< typeAr.length;i++){
tdItems[i] = new TDItem(typeAr[i],fieldAr[i]);
}
}
/**
* Constructor. Create a new tuple desc with typeAr.length fields with
* fields of the specified types, with anonymous (unnamed) fields.
*
* @param typeAr
* array specifying the number of and types of fields in this
* TupleDesc. It must contain at least one entry.
*/
public TupleDesc(Type[] typeAr) {
// some code goes here
tdItems = new TDItem[typeAr.length];
for(int i=0;i< typeAr.length;i++){
tdItems[i] = new TDItem(typeAr[i],"");
}
}
/**
* @return the number of fields in this TupleDesc
*/
public int numFields() {
// some code goes here
return tdItems.length;
}
/**
* Gets the (possibly null) field name of the ith field of this TupleDesc.
*
* @param i
* index of the field name to return. It must be a valid index.
* @return the name of the ith field
* @throws NoSuchElementException
* if i is not a valid field reference.
*/
public String getFieldName(int i) throws NoSuchElementException {
// some code goes here
if(i<0||i>= tdItems.length){
throw new NoSuchElementException();
}
return tdItems[i].fieldName;
}
/**
* Gets the type of the ith field of this TupleDesc.
*
* @param i
* The index of the field to get the type of. It must be a valid
* index.
* @return the type of the ith field
* @throws NoSuchElementException
* if i is not a valid field reference.
*/
public Type getFieldType(int i) throws NoSuchElementException {
// some code goes here
if(i<0||i>=tdItems.length){
throw new NoSuchElementException();
}
return tdItems[i].fieldType;
}
/**
* Find the index of the field with a given name.
*
* @param name
* name of the field.
* @return the index of the field that is first to have the given name.
* @throws NoSuchElementException
* if no field with a matching name is found.
*/
public int fieldNameToIndex(String name) throws NoSuchElementException {
// some code goes here
for(int i=0;i<tdItems.length;++i){
if(tdItems[i].fieldName.equals(name)){
return i;
}
}
throw new NoSuchElementException("not find fieldName " + name);
}
/**
* @return The size (in bytes) of tuples corresponding to this TupleDesc.
* Note that tuples from a given TupleDesc are of a fixed size.
*/
public int getSize() {
// some code goes here
int size = 0;
for(int i=0;i<tdItems.length;i++){
size += tdItems[i].fieldType.getLen();
}
return size;
}
/**
* Merge two TupleDescs into one, with td1.numFields + td2.numFields fields,
* with the first td1.numFields coming from td1 and the remaining from td2.
*
* @param td1
* The TupleDesc with the first fields of the new TupleDesc
* @param td2
* The TupleDesc with the last fields of the TupleDesc
* @return the new TupleDesc
*/
public static TupleDesc merge(TupleDesc td1, TupleDesc td2) {
Type[] typeAr = new Type[td1.numFields() + td2.numFields()];
String[] fieldAr = new String[td1.numFields() + td2.numFields()];
for(int i=0;i<td1.numFields();++i){
typeAr[i] = td1.tdItems[i].fieldType;
fieldAr[i] = td1.tdItems[i].fieldName;
}
for(int i=0;i<td2.numFields();++i){
typeAr[i+td1.numFields()] = td2.tdItems[i].fieldType;
fieldAr[i+td1.numFields()] = td2.tdItems[i].fieldName;
}
return new TupleDesc(typeAr,fieldAr);
}
/**
* Compares the specified object with this TupleDesc for equality. Two
* TupleDescs are considered equal if they have the same number of items
* and if the i-th type in this TupleDesc is equal to the i-th type in o
* for every i.
*
* @param o
* the Object to be compared for equality with this TupleDesc.
* @return true if the object is equal to this TupleDesc.
*/
public boolean equals(Object o) {
// some code goes here
if(this.getClass().isInstance(o)){
if(numFields()==((TupleDesc) o).numFields()){
for(int i=0;i<numFields();i++){
if(!tdItems[i].fieldType.equals(((TupleDesc) o).tdItems[i].fieldType)){
return false;
}
}
}
return true;
}
return false;
}
public int hashCode() {
// If you want to use TupleDesc as keys for HashMap, implement this so
// that equal objects have equals hashCode() results
throw new UnsupportedOperationException("unimplemented");
}
/**
* Returns a String describing this descriptor. It should be of the form
* "fieldType[0](fieldName[0]), ..., fieldType[M](fieldName[M])", although
* the exact format does not matter.
*
* @return String describing this descriptor.
*/
public String toString() {
StringBuilder sb = new StringBuilder();
for(int i=0;i<tdItems.length-1;++i){
sb.append(tdItems[i].fieldName + "(" + tdItems[i].fieldType + "), ");
}
sb.append(tdItems[tdItems.length-1].fieldName + "(" + tdItems[tdItems.length-1].fieldType + ")");
return sb.toString();
}
}
Tuple.java
package simpledb.storage;
import java.io.Serializable;
import java.util.Arrays;
import java.util.Iterator;
/**
* Tuple maintains information about the contents of a tuple. Tuples have a
* specified schema specified by a TupleDesc object and contain Field objects
* with the data for each field.
*/
public class Tuple implements Serializable {
private static final long serialVersionUID = 1L;
private TupleDesc tupleDesc;
private RecordId recordId;
private final Field[] fields;
/**
* Create a new tuple with the specified schema (type).
*
* @param td
* the schema of this tuple. It must be a valid TupleDesc
* instance with at least one field.
*/
public Tuple(TupleDesc td) {
// some code goes here
tupleDesc = td;
fields = new Field[td.numFields()];
}
/**
* @return The TupleDesc representing the schema of this tuple.
*/
public TupleDesc getTupleDesc() {
// some code goes here
return tupleDesc;
}
/**
* @return The RecordId representing the location of this tuple on disk. May
* be null.
*/
public RecordId getRecordId() {
// some code goes here
return recordId;
}
/**
* Set the RecordId information for this tuple.
*
* @param rid
* the new RecordId for this tuple.
*/
public void setRecordId(RecordId rid) {
// some code goes here
recordId = rid;
}
/**
* Change the value of the ith field of this tuple.
*
* @param i
* index of the field to change. It must be a valid index.
* @param f
* new value for the field.
*/
public void setField(int i, Field f) {
// some code goes here
fields[i] = f;
}
/**
* @return the value of the ith field, or null if it has not been set.
*
* @param i
* field index to return. Must be a valid index.
*/
public Field getField(int i) {
// some code goes here
return fields[i];
}
/**
* Returns the contents of this Tuple as a string. Note that to pass the
* system tests, the format needs to be as follows:
*
* column1tcolumn2tcolumn3t...tcolumnN
*
* where t is any whitespace (except a newline)
*/
public String toString() {
StringBuilder sb = new StringBuilder();
for(int i=0;i<tupleDesc.numFields()-1;++i){
sb.append(fields[i].toString()+" ");
}
sb.append(fields[tupleDesc.numFields()-1].toString()+"n");
return sb.toString();
}
/**
* @return
* An iterator which iterates over all the fields of this tuple
* */
public Iterator<Field> fields()
{
// some code goes here
return Arrays.stream(fields).iterator();
}
/**
* reset the TupleDesc of this tuple (only affecting the TupleDesc)
* */
public void resetTupleDesc(TupleDesc td)
{
// some code goes here
tupleDesc = td;
}
}
Catalog.java
package simpledb.common;
import simpledb.common.Type;
import simpledb.storage.DbFile;
import simpledb.storage.HeapFile;
import simpledb.storage.TupleDesc;
import java.io.BufferedReader;
import java.io.File;
import java.io.FileReader;
import java.io.IOException;
import java.util.*;
import java.util.concurrent.ConcurrentHashMap;
/**
* The Catalog keeps track of all available tables in the database and their
* associated schemas.
* For now, this is a stub catalog that must be populated with tables by a
* user program before it can be used -- eventually, this should be converted
* to a catalog that reads a catalog table from disk.
* catalog类描述的是数据库实例。包含了数据库现有的表信息以及表的schema信息。现在需要实现添加新表
* 的功能,以及从特定的表中提取信息。提取信息时通过表对应的TupleDesc对象决定操作的字段类型和数量。
*
* 全局catalog是分配给整个SimpleDB进程的Catalog类一个实例,可以
* 通过方法Database.getCatalog()获得,global buffer pool可以通过方法Database.getBufferPool()获得。
* ————————————————
* @Threadsafe
*/
public class Catalog {
private static final long serialVersionUID = 1L;
private final ConcurrentHashMap<Integer,Table> hashTable;
private static class Table{
private static final long serialVersionUID = 1L;
public final DbFile dbFile;
public final String tableName;
public final String pk;
public Table(DbFile file,String name,String pkeyField){
dbFile = file;
tableName = name;
pk = pkeyField;
}
public String toString(){
return tableName + "(" + dbFile.getId() + ":" + pk +")";
}
}
/**
* Constructor.
* Creates a new, empty catalog.
*/
public Catalog() {
hashTable = new ConcurrentHashMap<Integer, Table>();
}
/**
* Add a new table to the catalog.
* This table's contents are stored in the specified DbFile.
* @param file the contents of the table to add; file.getId() is the identfier of
* this file/tupledesc param for the calls getTupleDesc and getFile
* @param name the name of the table -- may be an empty string. May not be null. If a name
* conflict exists, use the last table to be added as the table for a given name.
* @param pkeyField the name of the primary key field
*/
public void addTable(DbFile file, String name, String pkeyField) {
// some code goes here
Table t = new Table(file,name,pkeyField);
hashTable.put(file.getId(),t);
}
public void addTable(DbFile file, String name) {
addTable(file, name, "");
}
/**
* Add a new table to the catalog.
* This table has tuples formatted using the specified TupleDesc and its
* contents are stored in the specified DbFile.
* @param file the contents of the table to add; file.getId() is the identfier of
* this file/tupledesc param for the calls getTupleDesc and getFile
*/
public void addTable(DbFile file) {
addTable(file, (UUID.randomUUID()).toString());
}
/**
* Return the id of the table with a specified name,
* @throws NoSuchElementException if the table doesn't exist
*/
public int getTableId(String name) throws NoSuchElementException {
// some code goes here
var ret = hashTable.searchValues(1,value->{
if(value.tableName.equals(name)) return value.dbFile.getId();
return null;
});
return 0;
}
/**
* Returns the tuple descriptor (schema) of the specified table
* @param tableid The id of the table, as specified by the DbFile.getId()
* function passed to addTable
* @throws NoSuchElementException if the table doesn't exist
*/
public TupleDesc getTupleDesc(int tableid) throws NoSuchElementException {
// some code goes here
var t = hashTable.getOrDefault(tableid,null);
if(t!=null){
return t.dbFile.getTupleDesc();
}else{
throw new NoSuchElementException();
}
}
/**
* Returns the DbFile that can be used to read the contents of the
* specified table.
* @param tableid The id of the table, as specified by the DbFile.getId()
* function passed to addTable
*/
public DbFile getDatabaseFile(int tableid) throws NoSuchElementException {
// some code goes here
Table t = hashTable.getOrDefault(tableid,null);
if(t != null){
return t.dbFile;
}else{
throw new NoSuchElementException("not found db file for table " + tableid);
}
}
public String getPrimaryKey(int tableid) {
Table t = hashTable.getOrDefault(tableid,null);
if(t != null){
return t.pk;
}else{
throw new NoSuchElementException("not found primary key for table " + tableid);
}
}
public Iterator<Integer> tableIdIterator() {
// 返回一个内部引用,并且指向一个内部类对象,该内部类重写了迭代器方法
return hashTable.keySet().iterator();
}
public String getTableName(int id) {
// some code goes here
Table t = hashTable.getOrDefault(id,null);
if(t != null){
return t.tableName;
}else{
throw new NoSuchElementException("not found name for table " + id);
}
}
/** Delete all tables from the catalog */
public void clear() {
// some code goes here
hashTable.clear();
}
/**
* Reads the schema from a file and creates the appropriate tables in the database.
* @param catalogFile
*/
public void loadSchema(String catalogFile) {
String line = "";
String baseFolder=new File(new File(catalogFile).getAbsolutePath()).getParent();
try {
BufferedReader br = new BufferedReader(new FileReader(catalogFile));
while ((line = br.readLine()) != null) {
//assume line is of the format name (field type, field type, ...)
String name = line.substring(0, line.indexOf("(")).trim();
//System.out.println("TABLE NAME: " + name);
String fields = line.substring(line.indexOf("(") + 1, line.indexOf(")")).trim();
String[] els = fields.split(",");
ArrayList<String> names = new ArrayList<>();
ArrayList<Type> types = new ArrayList<>();
String primaryKey = "";
for (String e : els) {
String[] els2 = e.trim().split(" ");
names.add(els2[0].trim());
if (els2[1].trim().equalsIgnoreCase("int"))
types.add(Type.INT_TYPE);
else if (els2[1].trim().equalsIgnoreCase("string"))
types.add(Type.STRING_TYPE);
else {
System.out.println("Unknown type " + els2[1]);
System.exit(0);
}
if (els2.length == 3) {
if (els2[2].trim().equals("pk"))
primaryKey = els2[0].trim();
else {
System.out.println("Unknown annotation " + els2[2]);
System.exit(0);
}
}
}
Type[] typeAr = types.toArray(new Type[0]);
String[] namesAr = names.toArray(new String[0]);
TupleDesc t = new TupleDesc(typeAr, namesAr);
HeapFile tabHf = new HeapFile(new File(baseFolder+"/"+name + ".dat"), t);
addTable(tabHf,name,primaryKey);
System.out.println("Added table : " + name + " with schema " + t);
}
} catch (IOException e) {
e.printStackTrace();
System.exit(0);
} catch (IndexOutOfBoundsException e) {
System.out.println ("Invalid catalog entry : " + line);
System.exit(0);
}
}
}
BufferPool.java
package simpledb.storage;
import simpledb.common.Database;
import simpledb.common.Permissions;
import simpledb.common.DbException;
import simpledb.common.DeadlockException;
import simpledb.transaction.TransactionAbortedException;
import simpledb.transaction.TransactionId;
import java.io.*;
import java.util.concurrent.ConcurrentHashMap;
/**
* BufferPool manages the reading and writing of pages into memory from
* disk. Access methods call into it to retrieve pages, and it fetches
* pages from the appropriate location.
* <p>
* The BufferPool is also responsible for locking; when a transaction fetches
* a page, BufferPool checks that the transaction has the appropriate
* locks to read/write the page.
*
* @Threadsafe, all fields are final
*/
public class BufferPool {
/** Bytes per page, including header. */
private static final int DEFAULT_PAGE_SIZE = 4096;
private static int pageSize = DEFAULT_PAGE_SIZE;
/** Default number of pages passed to the constructor. This is used by
other classes. BufferPool should use the numPages argument to the
constructor instead. */
public static final int DEFAULT_PAGES = 50;
private final int numPages;
private final ConcurrentHashMap<Integer,Page> pageStore;
/**
* Creates a BufferPool that caches up to numPages pages.
*
* @param numPages maximum number of pages in this buffer pool.
*/
public BufferPool(int numPages) {
// some code goes here
this.numPages = numPages;
pageStore = new ConcurrentHashMap<Integer, Page>();
}
public static int getPageSize() {
return pageSize;
}
// THIS FUNCTION SHOULD ONLY BE USED FOR TESTING!!
public static void setPageSize(int pageSize) {
BufferPool.pageSize = pageSize;
}
// THIS FUNCTION SHOULD ONLY BE USED FOR TESTING!!
public static void resetPageSize() {
BufferPool.pageSize = DEFAULT_PAGE_SIZE;
}
/**
* Retrieve the specified page with the associated permissions.
* Will acquire a lock and may block if that lock is held by another
* transaction.
* <p>
* The retrieved page should be looked up in the buffer pool. If it
* is present, it should be returned. If it is not present, it should
* be added to the buffer pool and returned. If there is insufficient
* space in the buffer pool, a page should be evicted and the new page
* should be added in its place.
*
* @param tid the ID of the transaction requesting the page
* @param pid the ID of the requested page
* @param perm the requested permissions on the page
*/
public Page getPage(TransactionId tid, PageId pid, Permissions perm)
throws TransactionAbortedException, DbException {
// some code goes here
Page ret = null;
if(!pageStore.contains(pid.hashCode())){
var dbFile = Database.getCatalog().getDatabaseFile(pid.getTableId());
var page = dbFile.readPage(pid);
ret = page;
pageStore.put(pid.hashCode(),page);
}
return ret==null?pageStore.get(pid.hashCode()):ret;
}
/**
* Releases the lock on a page.
* Calling this is very risky, and may result in wrong behavior. Think hard
* about who needs to call this and why, and why they can run the risk of
* calling it.
*
* @param tid the ID of the transaction requesting the unlock
* @param pid the ID of the page to unlock
*/
public void unsafeReleasePage(TransactionId tid, PageId pid) {
// some code goes here
// not necessary for lab1|lab2
}
/**
* Release all locks associated with a given transaction.
*
* @param tid the ID of the transaction requesting the unlock
*/
public void transactionComplete(TransactionId tid) {
// some code goes here
// not necessary for lab1|lab2
}
/** Return true if the specified transaction has a lock on the specified page */
public boolean holdsLock(TransactionId tid, PageId p) {
// some code goes here
// not necessary for lab1|lab2
return false;
}
/**
* Commit or abort a given transaction; release all locks associated to
* the transaction.
*
* @param tid the ID of the transaction requesting the unlock
* @param commit a flag indicating whether we should commit or abort
*/
public void transactionComplete(TransactionId tid, boolean commit) {
// some code goes here
// not necessary for lab1|lab2
}
/**
* Add a tuple to the specified table on behalf of transaction tid. Will
* acquire a write lock on the page the tuple is added to and any other
* pages that are updated (Lock acquisition is not needed for lab2).
* May block if the lock(s) cannot be acquired.
*
* Marks any pages that were dirtied by the operation as dirty by calling
* their markDirty bit, and adds versions of any pages that have
* been dirtied to the cache (replacing any existing versions of those pages) so
* that future requests see up-to-date pages.
*
* @param tid the transaction adding the tuple
* @param tableId the table to add the tuple to
* @param t the tuple to add
*/
public void insertTuple(TransactionId tid, int tableId, Tuple t)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
// not necessary for lab1
}
/**
* Remove the specified tuple from the buffer pool.
* Will acquire a write lock on the page the tuple is removed from and any
* other pages that are updated. May block if the lock(s) cannot be acquired.
*
* Marks any pages that were dirtied by the operation as dirty by calling
* their markDirty bit, and adds versions of any pages that have
* been dirtied to the cache (replacing any existing versions of those pages) so
* that future requests see up-to-date pages.
*
* @param tid the transaction deleting the tuple.
* @param t the tuple to delete
*/
public void deleteTuple(TransactionId tid, Tuple t)
throws DbException, IOException, TransactionAbortedException {
// some code goes here
// not necessary for lab1
}
/**
* Flush all dirty pages to disk.
* NB: Be careful using this routine -- it writes dirty data to disk so will
* break simpledb if running in NO STEAL mode.
*/
public synchronized void flushAllPages() throws IOException {
// some code goes here
// not necessary for lab1
}
/** Remove the specific page id from the buffer pool.
Needed by the recovery manager to ensure that the
buffer pool doesn't keep a rolled back page in its
cache.
Also used by B+ tree files to ensure that deleted pages
are removed from the cache so they can be reused safely
*/
public synchronized void discardPage(PageId pid) {
// some code goes here
// not necessary for lab1
}
/**
* Flushes a certain page to disk
* @param pid an ID indicating the page to flush
*/
private synchronized void flushPage(PageId pid) throws IOException {
// some code goes here
// not necessary for lab1
}
/** Write all pages of the specified transaction to disk.
*/
public synchronized void flushPages(TransactionId tid) throws IOException {
// some code goes here
// not necessary for lab1|lab2
}
/**
* Discards a page from the buffer pool.
* Flushes the page to disk to ensure dirty pages are updated on disk.
*/
private synchronized void evictPage() throws DbException {
// some code goes here
// not necessary for lab1
}
}
SeqSacn.java
package simpledb.execution;
import simpledb.common.Database;
import simpledb.storage.DbFileIterator;
import simpledb.transaction.Transaction;
import simpledb.transaction.TransactionAbortedException;
import simpledb.transaction.TransactionId;
import simpledb.common.DbException;
import simpledb.storage.Tuple;
import simpledb.storage.TupleDesc;
import javax.xml.crypto.Data;
import java.util.*;
/**
* SeqScan is an implementation of a sequential scan access method that reads
* each tuple of a table in no particular order (e.g., as they are laid out on
* disk).
*/
public class SeqScan implements OpIterator {
private static final long serialVersionUID = 1L;
private final TransactionId tid;
private int tableId;
private String tableAlias;
private DbFileIterator it;
/**
* Creates a sequential scan over the specified table as a part of the
* specified transaction.
*
* @param tid
* The transaction this scan is running as a part of.
* @param tableid
* the table to scan.
* @param tableAlias
* the alias of this table (needed by the parser); the returned
* tupleDesc should have fields with name tableAlias.fieldName
* (note: this class is not responsible for handling a case where
* tableAlias or fieldName are null. It shouldn't crash if they
* are, but the resulting name can be null.fieldName,
* tableAlias.null, or null.null).
*/
public SeqScan(TransactionId tid, int tableid, String tableAlias) {
// some code goes here
this.tid = tid;
this.tableId = tableid;
this.tableAlias = tableAlias;
}
/**
* @return
* return the table name of the table the operator scans. This should
* be the actual name of the table in the catalog of the database
* */
public String getTableName() {
return Database.getCatalog().getTableName(tableId);
}
/**
* @return Return the alias of the table this operator scans.
* */
public String getAlias()
{
// some code goes here
return tableAlias;
}
/**
* Reset the tableid, and tableAlias of this operator.
* @param tableid
* the table to scan.
* @param tableAlias
* the alias of this table (needed by the parser); the returned
* tupleDesc should have fields with name tableAlias.fieldName
* (note: this class is not responsible for handling a case where
* tableAlias or fieldName are null. It shouldn't crash if they
* are, but the resulting name can be null.fieldName,
* tableAlias.null, or null.null).
*/
public void reset(int tableid, String tableAlias) {
// some code goes here
this.tableId = tableid;
this.tableAlias = tableAlias;
}
public SeqScan(TransactionId tid, int tableId, Transaction tid1, Transaction tid2, TransactionId tid3) {
this(tid, tableId, Database.getCatalog().getTableName(tableId));
}
public void open() throws DbException, TransactionAbortedException {
// some code goes here
it = Database.getCatalog().getDatabaseFile(tableId).iterator(tid);
it.open();
}
/**
* Returns the TupleDesc with field names from the underlying HeapFile,
* prefixed with the tableAlias string from the constructor. This prefix
* becomes useful when joining tables containing a field(s) with the same
* name. The alias and name should be separated with a "." character
* (e.g., "alias.fieldName").
*
* @return the TupleDesc with field names from the underlying HeapFile,
* prefixed with the tableAlias string from the constructor.
*/
public TupleDesc getTupleDesc() {
// some code goes here
return Database.getCatalog().getTupleDesc(tableId);
}
public boolean hasNext() throws TransactionAbortedException, DbException {
// some code goes here
if(it == null){
return false;
}
return it.hasNext();
}
public Tuple next() throws NoSuchElementException,
TransactionAbortedException, DbException {
// some code goes here
if(it == null){
throw new NoSuchElementException("no next tuple");
}
Tuple t = it.next();
if(t == null){
throw new NoSuchElementException("no next tuple");
}
return t;
}
public void close() {
// some code goes here
it = null;
}
public void rewind() throws DbException, NoSuchElementException,
TransactionAbortedException {
// some code goes here
it.rewind();
}
}
最后
以上就是坚定发箍最近收集整理的关于MIT6.830 simple-db lab1的全部内容,更多相关MIT6.830内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复