文章目录
- 一、概述
- 二、cephadm 工具的使用
- 1)cephadm 工具的介绍
- 2)cephadm 安装
- 3)cephadm 常用命令使用
- 4)启用 ceph shell
- 三、ceph 命令使用
- 1)添加新节点
- 2)使用 ceph 安装软件
- 3)主机操作
- 1、列出主机
- 2、添加主机
- 3、删除主机
- 4、主机标签
- 4)维护模式
- 5)查看服务状态
- 6)查看守护进程状态
- 7)OSD 服务
- 1、列出设备
- 2、创建新的 OSD
- 3、移除 OSD
- 4、监控 OSD 删除的状态
- 5、停止删除 OSD
- 6、激活现有 OSD
- 7、查看数据延迟
- 8、详细列出集群每块磁盘的使用情况
- 8)pool相关操作
- 1、查看ceph集群中的pool数量
- 2、在ceph集群中创建一个pool
- 9)PG 相关
- 1、查看pg组的映射信息
- 2、查看一个PG的map
- 3、查看PG状态
- 4、显示一个集群中的所有的pg统计
- 四、实战操作演示
- 1)块存储使用(RDB )
- 1、 使用 create 创建 pool 池
- 2、需要初始化 pool
- 3、创建 rbd 块设备
- 4、查看块设备信息
- 5、删除块设备
- 6、设备挂载
- 7、块设备扩容
- 8、卸载
- 2)文件系统使用(CephFS)
- 1、查看ceph文件系统
- 2、创建存储池
- 3、创建文件系统
- 4、查看存储池配额
- 5、内核驱动挂载ceph文件系统
- 6、常用命令
- 3)对象存储使用(RGW)
- 1、查看ceph集群中有多少个pool
- 2、显示整个系统使用率
- 3、创建一个pool
- 4、创建一个对象object
- 5、查看对象文件
- 6、删除一个对象
- 7、通过api接口使用 Ceph 存储存储
一、概述
Ceph是当前非常流行的开源分布式存储系统,具有高扩展性、高性能、高可靠性等优点,同时提供块存储服务(rbd)、对象存储服务(rgw)以及文件系统存储服务(cephfs),Ceph在存储的时候充分利用存储节点的计算能力,在存储每一个数据时都会通过计算得出该数据的位置,尽量的分布均衡。目前也是OpenStack的主流后端存储。
关于Ceph更详细的介绍和环境部署可以参考我这篇文章:分布式存储系统 Ceph 介绍与环境部署
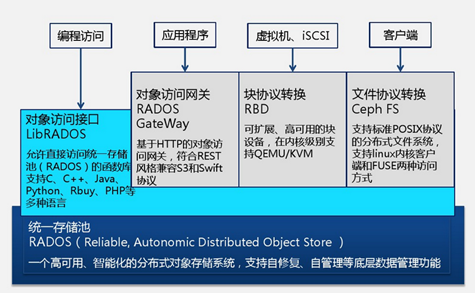
二、cephadm 工具的使用
官方文档:https://docs.ceph.com/en/latest/cephadm/
1)cephadm 工具的介绍
cephadm 是用于管理 Ceph 集群的实用程序或者是管理工具。
Cephadm的目标是提供一个功能齐全、健壮且维护良好的安装和管理层,可供不在Kubernetes中运行Ceph的任何环境使用。具体特性如下:
-
将所有组件部署在容器中—— 使用容器简化了不同发行版之间的依赖关系和打包复杂度。当然,我们仍在构建RPM和Deb软件包,但是随着越来越多的用户过渡到cephadm(或Rook)并构建容器,我们看到的特定于操作系统的bug就越少。
-
与Orchestrator API紧密集成—— Ceph的Orchestrator界面在cephadm的开发过程中得到了广泛的发展,以匹配实现并清晰地抽象出Rook中存在的(略有不同)功能。最终结果是不管是看起来还是感觉都像Ceph的一部分。
-
不依赖管理工具——Salt和Ansible之类的工具在大型环境中进行大规模部署时非常出色,但是使Ceph依赖于这种工具意味着用户还需要学习该相关的软件。更重要的是,与专为管理Ceph而专门设计的部署工具相比,依赖这些工具(Salt和Ansible等)的部署最终可能变得更加复杂,难以调试并且(最显着)更慢。
-
最小的操作系统依赖性—— Cephadm需要
Python 3,LVM和container runtime(Podman或Docker)。任何当前的Linux发行版都可以。 -
将群集彼此隔离—— 支持多个Ceph集群同时存在于同一主机上一直是一个比较小众的场景,但是确实存在,并且以一种健壮,通用的方式将集群彼此隔离,这使得测试和重新部署集群对于开发人员和用户而言都是安全自然的过程。
-
自动升级—— 一旦Ceph“拥有”自己的部署方式,它就可以以安全和自动化的方式[升级Ceph。
-
从“传统”部署工具轻松迁移——我们需要从现有工具(例如ceph-ansible,ceph-deploy和DeepSea)中现有的Ceph部署轻松过渡到cephadm。
以下是一些事情的列表 cephadm 可以做:
-
cephadm 可以将 Ceph 容器添加到集群。
-
cephadm 可以从集群中移除 Ceph 容器。
-
cephadm 可以更新 Ceph 容器。
2)cephadm 安装
mkdir -p /opt/ceph/my-cluster ; cd /opt/ceph/my-cluster
curl --silent --remote-name --location https://github.com/ceph/ceph/raw/octopus/src/cephadm/cephadm -o cephadm
chmod +x cephadm
# 开始安装ceph-common,ceph工具
./cephadm install ceph-common ceph
# 安装cephadm工具
./cephadm install
which cephadm
which ceph
# 查看帮助
cephadm --help
3)cephadm 常用命令使用
一般使用cephadm 用作环境初始化,其它的操作交由ceph工具完成,常用命令如下:
cephadm模型有一个简单的“ Bootstrap ”步骤,该步骤从命令行启动,该命令行在本地主机上启动一个最小的Ceph群集(一个monitor 与 manager 守护程序)。然后,使用orchestrator命令部署集群的其余部分,以添加其他主机,使用存储设备并为集群服务部署守护程序。
### 1、配置ceph安装源(或指定版本)
./cephadm add-repo --release octopus
#或
#./cephadm add-repo --version 15.2.1
### 2、集群初始化
cephadm bootstrap --help # 查看帮助
# cephadm bootstrap --mon-ip *<mon-ip>*
cephadm bootstrap --mon-ip 192.168.182.130
4)启用 ceph shell
cephadm 命令一般只是作为部署的引导作用。 但是,我们建议启用对 ceph 命令,因为ceph命令更加简洁强大。
# 启用ceph shell
cephadm shell
# 这命令在容器中启动 bash shell 并在本机上安装了所有 Ceph 软件包。
# 查看ceph集群状态,非交互式
cephadm shell ceph status
# 或者
cephadm shell ceph -s
您可以安装 ceph-common 包,其中包含所有 Ceph 命令,包括 ceph, rbd, mount.ceph (用于安装 CephFS 文件系统)等:
cephadm add-repo --release quincy
cephadm install ceph-common
# 当然也只安装ceph命令
cephadm install ceph
接下来就可以开心的使用ceph命令部署软件等等。
三、ceph 命令使用
上面我们已经安装了ceph的全家桶,这里就不重复了。
1)添加新节点
ceph orch host add local-168-182-131
ceph orch host add local-168-182-132
#第一次部署新节点时直接用上边的命令即可:
#但是之后的节点新增有可能上述命令出错:
ceph orch host add local-168-182-131 192.168.182.133 #后边跟上对应的IP
# 查看节点
ceph orch host ls
2)使用 ceph 安装软件
### 1、部署监视器(monitor)
# ceph orch apply mon *<number-of-monitors>*
# 确保在此列表中包括第一台(引导)主机。
ceph orch apply mon local-168-182-130,local-168-182-131,local-168-182-132
### 2、部署 osd
# 查看
ceph orch device ls
# 开始部署
# 【第一种方式】告诉Ceph使用任何可用和未使用的存储设备:
ceph orch apply osd --all-available-devices
# 【第二种方式】或者使用下面命令指定使用的磁盘(推荐使用这种方式吧)
# ceph orch daemon add osd *<host>*:*<device-path>*
#例如:
#从特定主机上的特定设备创建OSD:
ceph orch daemon add osd local-168-182-130:/dev/sdb
ceph orch daemon add osd local-168-182-130:/dev/sdc
ceph orch daemon add osd local-168-182-131:/dev/sdb
ceph orch daemon add osd local-168-182-131:/dev/sdc
ceph orch daemon add osd local-168-182-132:/dev/sdb
ceph orch daemon add osd local-168-182-132:/dev/sdc
### 3、部署mds
# ceph orch apply mds *<fs-name>* --placement="*<num-daemons>* [*<host1>* ...]"
ceph orch apply mds myfs --placement="3 local-168-182-130 local-168-182-131 local-168-182-132"
### 4、部署RGW
# 为特定领域和区域部署一组radosgw守护程序:
# ceph orch apply rgw *<realm-name>* *<zone-name>* --placement="*<num-daemons>* [*<host1>* ...]"
ceph orch apply rgw myorg us-east-1 --placement="3 local-168-182-130 local-168-182-131 local-168-182-132"
###说明:
#myorg : 领域名 (realm-name)
#us-east-1: 区域名 (zone-name)myrgw
### 5、部署ceph-mgr
ceph orch apply mgr local-168-182-130,local-168-182-131,local-168-182-132
删除OSD节点
### 1.停止osd进程
ceph osd stop x //(x 可以通过ceph osd ls 查看)
#停止osd的进程,这个是通知集群这个osd进程不在了,不提供服务了,因为本身没权重,就不会影响到整体的分布,也就没有迁移
### 2.将节点状态标记为out
ceph osd out osd.x
#停止到osd的进程,这个是通知集群这个osd不再映射数据了,不提供服务了,因为本身没权重,就不会影响到整体的分布,也就没有迁移
### 3. 从crush中移除节点
ceph osd crush remove osd.x
# 这个是从crush中删除,
### 4. 删除节点
ceph osd rm osd.x
# 这个是从集群里面删除这个节点的记录ls
### 5. 删除节点认证(不删除编号会占住)
ceph auth del osd.x
#这个是从认证当中去删除这个节点的信息
#【注意】
#比如卸载了node3的某osd,(osd.x 即: node:/dev/sdb),在node3上执行以下操作,可以后继续使用node3:/dev/sdb
#1. lvremove /dev/ceph-3f728c86-8002-47ab-b74a-d00f4cf0fdd2/osd-block-08c6dc02-85d1-4da2-8f71-5499c115cd3c // dev 后的参数可以通过lsblk查看
#2. vgremove ceph-3f728c86-8002-47ab-b74a-d00f4cf0fdd2
查看服务
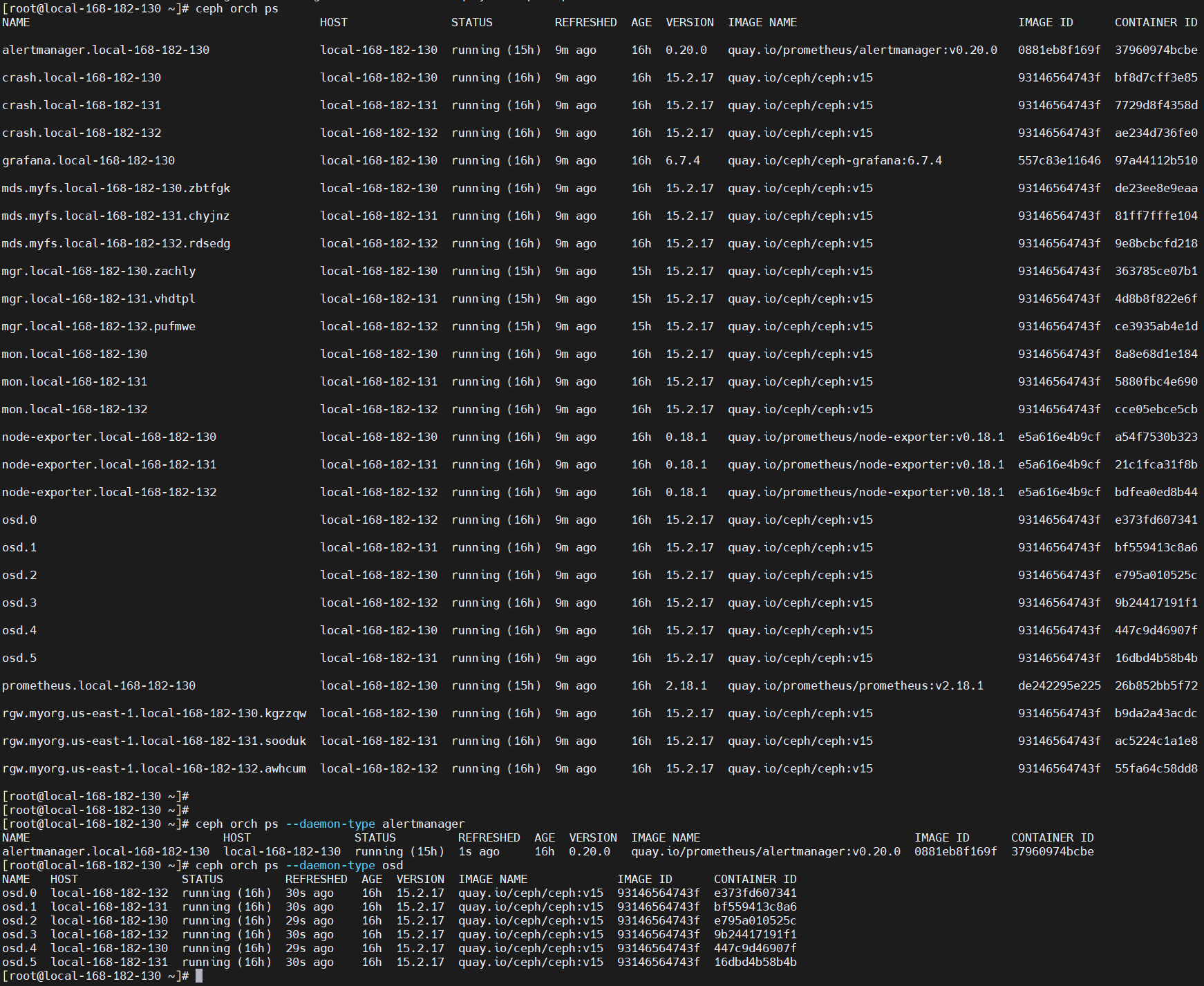
# 其实可以通过docker ps查看,但是不太直观,所以既然有ceph命令,肯定是用ceph查看更为详细直观了。
ceph orch ps
ceph orch ps --daemon-type alertmanager
ceph orch ps --daemon-type osd
# ceph orch ps --daemon-type [alertmanager|crash|grafana|mds|mgrmon|node-exporter|osd|prometheus|rgw]
3)主机操作
1、列出主机
# ceph orch host ls [--format yaml] [--host-pattern <name>] [--label <label>] [--host-status <status>]
ceph orch host ls
2、添加主机
要将每个新主机添加到群集,请执行以下步骤:
- 【1】在新主机的根用户的 authorized_keys 文件:
# ssh-copy-id -f -i /etc/ceph/ceph.pub root@*<new-host>*
ssh-copy-id -f -i /etc/ceph/ceph.pub root@192.168.182.133
- 【2】告诉 Ceph 新节点是集群的一部分:
# ceph orch host add *<newhost>* [*<ip>*] [*<label1> ...*]
ceph orch host add local-168-182-130 192.168.182.130
# 最好显式提供主机 IP 地址。 如果 IP 是 未提供,则主机名将立即通过 将使用该 DNS 和该 IP。
还可以包含一个或多个标签以立即标记 新主机。
ceph orch host add local-168-182-130 192.168.182.130 --labels _admin
3、删除主机
删除所有守护程序后,可以安全地从集群中移除主机 从它。
- 【1】要从主机中排出所有守护程序,请运行以下形式的命令:
# ceph orch host drain *<host>*
ceph orch host drain local-168-182-130
#将计划删除主机上的所有 osd。您可以通过以下方式检查 osd 删除进度:
ceph orch osd rm status
# 可以使用以下命令检查主机上是否没有守护程序:
# ceph orch ps <host>
ceph orch ps local-168-182-130
- 【2】删除所有守护程序后,可以使用以下命令删除主机:
# ceph orch host rm <host>
ceph orch host rm local-168-182-130
如果主机处于脱机状态且无法恢复,仍可以通过以下方法将其从群集中移除:
# ceph orch host rm <host> --offline --force
ceph orch host rm local-168-182-130 --offline --force
4、主机标签
业务流程协调程序支持将标签分配给主机。标签 是自由形式的,本身和每个主机都没有特定的含义 可以有多个标签。它们可用于指定放置 的守护进程。
- 【1】添加标签
# ceph orch host add my_hostname --labels=my_label1
ceph orch host add local-168-182-130 --labels=my_label1,my_label2
# 也可以,ceph orch host label add my_hostname my_label
ceph orch host label add local-168-182-130 my_label
- 【2】删除标签
# ceph orch host label rm my_hostname my_label
ceph orch host label rm local-168-182-130 my_label
特殊主机标签
以下宿主标签对头孢具有特殊含义。 一切始于 _.
_no_schedule: 不要在此主机上调度或部署守护程序.
此标签可防止 cephadm 在此主机上部署守护程序。 如果它被添加到 已经包含 Ceph 守护进程的现有主机,将导致 cephadm 移动 其他位置的守护程序(OSD 除外,不会自动删除)。
_no_autotune_memory: 不自动调整此主机上的内存.
此标签将阻止守护程序内存被调整,即使 osd_memory_target_autotune 或为一个或多个守护程序启用类似选项 在该主机上。
_admin: 将 client.admin 和 ceph.conf 分发到此主机.
默认情况下,一个
_admin标签应用于群集中的第一个主机(其中 引导程序最初是运行的),并且client.admin密钥设置为分发 到该主机通过 功能。 添加此标签 到其他主机通常会导致 CEPHADM 部署配置和密钥环文件 在 .从版本 16.2.10和 17.2.1 开始 添加到默认位置 Cephadm 还存储配置和密钥环 文件中的文件 目录。ceph orch client-keyring .../etc/ceph/etc/ceph//var/lib/ceph/<fsid>/config
4)维护模式
将主机置于维护模式和退出维护模式(停止主机上的所有 Ceph 守护进程):
# 进入维护模式
# ceph orch host maintenance enter <hostname> [--force]
ceph orch host maintenance enter local-168-182-130
# 退出维护模式
# ceph orch host maintenance exit <hostname>
ceph orch host maintenance exit local-168-182-130
5)查看服务状态
查看一个的状态 在 Ceph 集群中运行的服务中,执行以下操作:
# ceph orch ls [--service_type type] [--service_name name] [--export] [--format f] [--refresh]
# 查看所有服务
ceph orch ls
# 查看指定服务
ceph orch ls alertmanager
ceph orch ls --service_name crash
6)查看守护进程状态
首先,打印业务流程协调程序已知的所有守护程序的列表:
# ceph orch ps [--hostname host] [--daemon_type type] [--service_name name] [--daemon_id id] [--format f] [--refresh]
ceph orch ps
# 然后查询特定服务实例的状态(mon、osd、mds、rgw)。 对于 OSD,ID 是数字 OSD ID。对于 MDS 服务,id 是文件 系统名称:
ceph orch ps --daemon_type osd --daemon_id 0
7)OSD 服务
1、列出设备
ceph-volume 按顺序不时扫描群集中的每个主机 确定存在哪些设备以及它们是否有资格 用作 OSD。
查看列表,运行以下命令:
# ceph orch device ls [--hostname=...] [--wide] [--refresh]
ceph orch device ls
# 使用 --wide 选项提供与设备相关的所有详细信息, 包括设备可能不符合用作 OSD 条件的任何原因。
ceph orch device ls --wide
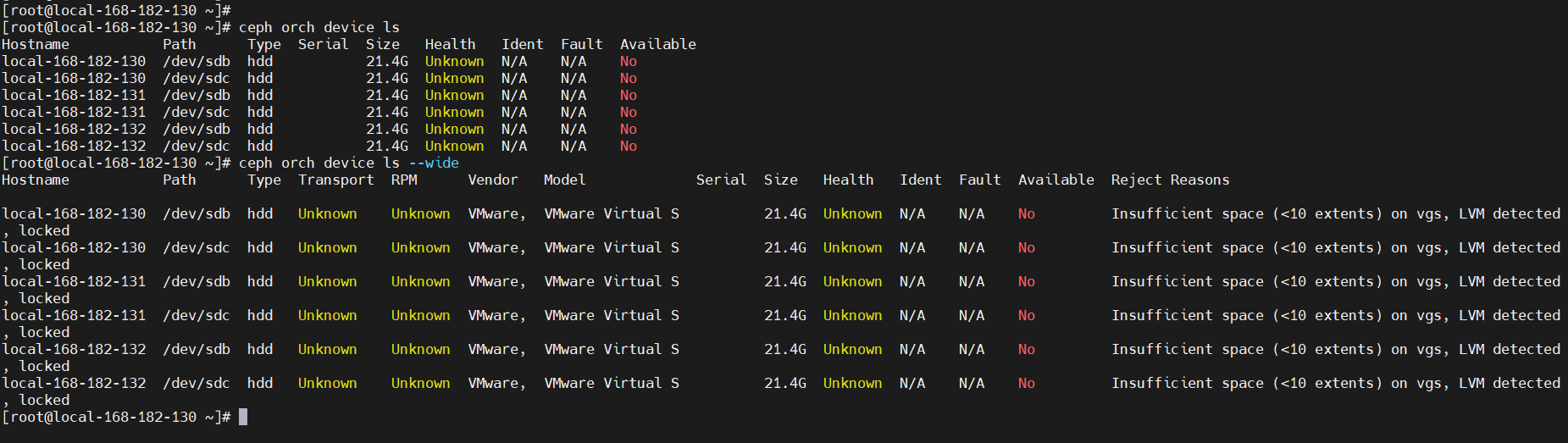
在上面的示例中,您可以看到名为“运行状况”、“标识”和“故障”的字段。 此信息通过与 libstoragemgmt.默认情况下, 此集成已禁用(因为 libstoragemgmt 可能不是 100% 与您的硬件兼容)。 要使 cephadm 包括这些字段, 启用CEPHADM的“增强设备扫描”选项,如下所示;
ceph config set mgr mgr/cephadm/device_enhanced_scan true
2、创建新的 OSD
有几种方法可以创建新的 OSD:
- 【1】告诉 Ceph 使用任何可用和未使用的存储设备:
# 如果将新磁盘添加到群集,它们将自动用于 创建新的 OSD。
ceph orch apply osd --all-available-devices
- 【2】从特定主机上的特定设备创建 OSD:
# ceph orch daemon add osd *<host>*:*<device-path>*
ceph orch daemon add osd local-168-182-133:/dev/sdb
ceph orch daemon add osd local-168-182-133:/dev/sdc
# 或者
# ceph orch daemon add osd host1:data_devices=/dev/sda,/dev/sdb,db_devices=/dev/sdc,osds_per_device=2
ceph orch daemon add osd local-168-182-133:data_devices=/dev/sdb,/dev/sdc
# 使用lvm
# ceph orch daemon add osd *<host>*:*<lvm-path>*
ceph orch daemon add osd host1:/dev/vg_osd/lvm_osd1701
- 【3】试运行,不是真正的执行
# 这 --dry-run 标志使业务流程协调程序显示内容的预览 将在不实际创建 OSD 的情况下发生。
ceph orch apply osd --all-available-devices --dry-run
3、移除 OSD
从集群中删除 OSD 涉及两个步骤:
-
从集群中撤出所有归置组 (PG)
-
从集群中删除无 PG 的 OSD
以下命令执行这两个步骤:
# ceph orch osd rm <osd_id(s)> [--replace] [--force]
ceph orch osd rm 0
4、监控 OSD 删除的状态
ceph orch osd rm status
5、停止删除 OSD
# ceph orch osd rm stop <osd_id(s)>
ceph orch osd rm stop 4
6、激活现有 OSD
如果重新安装主机的操作系统,则需要激活现有的 OSD 再。对于此用例,cephadm 提供了一个包装器 激活 那 激活主机上的所有现有 OSD。
# ceph cephadm osd activate <host>...
ceph cephadm osd activate local-168-182-133
7、查看数据延迟
ceph osd perf
8、详细列出集群每块磁盘的使用情况
ceph osd df
8)pool相关操作
1、查看ceph集群中的pool数量
ceph osd lspools
#或者
ceph osd pool ls
2、在ceph集群中创建一个pool
#这里的100指的是PG组:
ceph osd pool create rbdtest 100
9)PG 相关
PG =“放置组”。当集群中的数据,对象映射到编程器,被映射到这些PGS的OSD。
1、查看pg组的映射信息
ceph pg dump
# 或者
# ceph pg ls
2、查看一个PG的map
ceph pg map 7.1a
3、查看PG状态
ceph pg stat
4、显示一个集群中的所有的pg统计
ceph pg dump --format plain
这里只是列举了一些常用的操作命令,更多的命令可以查看帮助或者查看官方文档。
四、实战操作演示
1)块存储使用(RDB )
1、 使用 create 创建 pool 池
ceph osd lspools
# 创建
ceph osd pool create ceph-demo 64 64
# 创建命令时需要指定PG、PGP数量,还可以指定复制模型还是纠删码模型,副本数量等等
# osd pool create <pool> [<pg_num:int>] [<pgp_num:int>] [replicated|erasure] [<erasure_code_ create pool profile>] [<rule>] [<expected_num_objects:int>] [<size:int>] [<pg_num_min:int>] [on|off| warn] [<target_size_bytes:int>] [<target_size_ratio:float>]
【温馨提示】PG (Placement Group),pg是一个虚拟的概念,用于存放object,PGP(Placement Group for Placement purpose),相当于是pg存放的一种osd排列组合。
获取 pool 池属性信息,可以重新设置,有很多参数,都可以如下设置
# 1、获取 pg 个数
ceph osd pool get ceph-demo pg_num
# 2、获取 pgp 个数
ceph osd pool get ceph-demo pgp_num
# 3、获取副本数
ceph osd pool get ceph-demo size
# 4、获取使用模型
ceph osd pool get ceph-demo crush_rule
# 5、设置副本数
ceph osd pool set ceph-demo size 2
# 6、设置 pg 数量
ceph osd pool set ceph-demo pg_num 128
# 7、设置 pgp 数量
ceph osd pool set ceph-demo pgp_num 128
2、需要初始化 pool
rbd pool init ceph-demo
3、创建 rbd 块设备
# 查看 块设备
rbd -p ceph-demo ls
# 【方式一】创建块设备
rbd create -p ceph-demo --image rbd-demo.img --size 10G
# 【方式二】创建块设备
rbd create ceph-demo/rbd-demo2.img --size 10G
# 查看 块设备
rbd -p ceph-demo ls
4、查看块设备信息
rbd info ceph-demo/rbd-demo2.img
5、删除块设备
rbd rm -p ceph-demo --image rbd-demo2.img
6、设备挂载
由于没有虚拟机进行挂载,所以需要使用内核 map 进行挂载;
rbd map ceph-demo/rbd-demo.img
[root@local-168-182-130 ceph]# rbd map ceph-demo/rbd-demo.img
rbd: sysfs writefailed
RBD image feature set mismatch. You can disable featuresunsupportedby the kernel with “rbd feature disable ceph-demo/rbd-demo.img object-map fast-diff deep-flatten”.
In some cases useful info is found in syslog - try “dmesg | tail”.
rbd: mapfailed: (6) No such device or address
映射的过程当中出现错误,这是因为 Centos7 当中不支持这几个特性,我们可以在创建时指定 features 。
rbd feature disable ceph-demo/rbd-demo.img deep-flatten
rbd feature disable ceph-demo/rbd-demo.img fast-diff
rbd feature disable ceph-demo/rbd-demo.img object-map
rbd feature disable ceph-demo/rbd-demo.img exclusive-lock
再次挂载,挂载成功
rbd map ceph-demo/rbd-demo.img
查看设备列表
rbd device list
通过fdisk 查看设备列表
fdisk -l
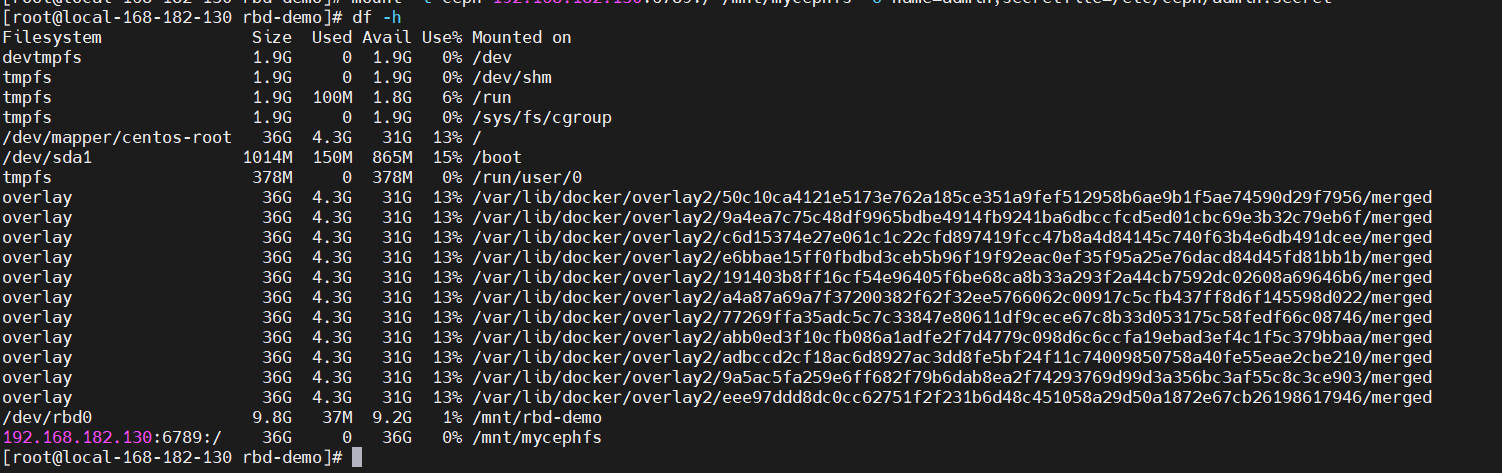
使用 rbd 设备
# 格式化
mkfs.ext4 /dev/rbd0
# 创建挂载目录
mkdir /mnt/rbd-demo
# 挂载
mount /dev/rbd0 /mnt/rbd-demo/
7、块设备扩容
设备可以扩容,也可以缩容,但不建议使用缩容,有可能产生数据丢失。
# 扩容
rbd resize ceph-demo/rbd-demo.img --size 10G
# 查看
rbd -p ceph-demo info --image rbd-demo.img
# 也可以通过lsblk查看
lsblk
8、卸载
umount /mnt/rbd-demo
2)文件系统使用(CephFS)
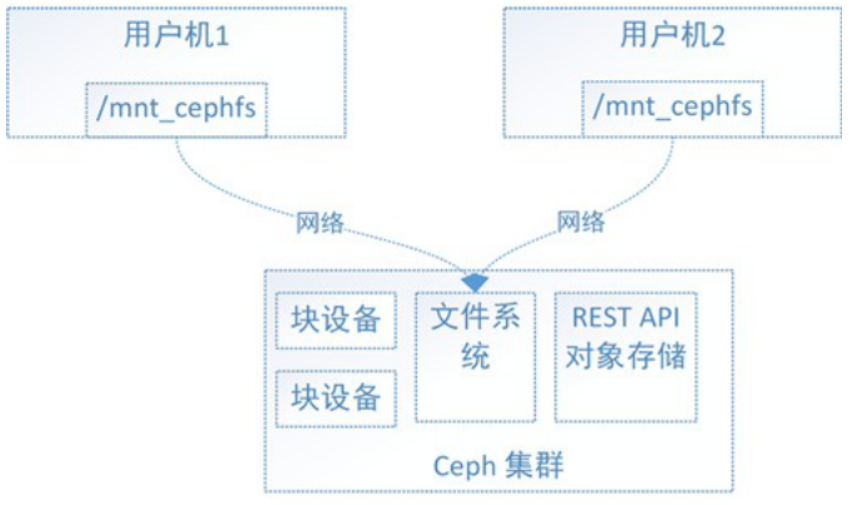
1、查看ceph文件系统
ceph fs ls
2、创建存储池
ceph osd pool create cephfs_data 128
ceph osd pool create cephfs_metadata 128
# 创建命令时需要指定PG、PGP数量,还可以指定复制模型还是纠删码模型,副本数量等等
# osd pool create <pool> [<pg_num:int>] [<pgp_num:int>] [replicated|erasure] [<erasure_code_ create pool profile>] [<rule>] [<expected_num_objects:int>] [<size:int>] [<pg_num_min:int>] [on|off| warn] [<target_size_bytes:int>] [<target_size_ratio:float>]
【温馨提示】PG (Placement Group),pg是一个虚拟的概念,用于存放object,PGP(Placement Group for Placement purpose),相当于是pg存放的一种osd排列组合。
3、创建文件系统
ceph fs new 128 cephfs_metadata cephfs_data
#此时再回头查看文件系统,mds节点状态
ceph fs ls
ceph mds stat
4、查看存储池配额
ceph osd pool get-quota cephfs_metadata
5、内核驱动挂载ceph文件系统
【1】创建挂载点
mkdir /mnt/mycephfs
【2】获取存储密钥,如果没有前往管理节点重新复制
cat /etc/ceph/ceph.client.admin.keyring
#将存储密钥保存到/etc/ceph/admin.secret文件中:
vim /etc/ceph/admin.secret
# AQBFVrFjqst6CRAA9WaF1ml7btkn6IuoUDb9zA==
#如果想开机挂载可以写入/etc/rc.d/rc.local文件中
【3】挂载
# Ceph 存储集群默认需要认证,所以挂载时需要指定用户名 name 和创建密钥文件一节中创建的密钥文件 secretfile ,例如:
# mount -t ceph {ip-address-of-monitor}:6789:/ /mnt/mycephfs
mount -t ceph 192.168.182.130:6789:/ /mnt/mycephfs -o name=admin,secretfile=/etc/ceph/admin.secret
【4】卸载
umount /mnt/mycephfs
6、常用命令
# 查看存储池副本数
ceph osd pool get [存储池名称] size
# 修改存储池副本数
ceph osd pool set [存储池名称] size 3
# 打印存储池列表
ceph osd lspools
# 创建存储池
ceph osd pool create [存储池名称] [pg_num的取值]
# 存储池重命名
ceph osd pool rename [旧的存储池名称] [新的存储池名称]
# 查看存储池的pg_num
ceph osd pool get [存储池名称] pg_num
# 查看存储池的pgp_num
ceph osd pool get [存储池名称] pgp_num
# 修改存储池的pg_num值
ceph osd pool set [存储池名称] pg_num [pg_num的取值]
# 修改存储池的pgp_num值
ceph osd pool set [存储池名称] pgp_num [pgp_num的取值]
3)对象存储使用(RGW)
rados 是和Ceph的对象存储集群(RADOS),Ceph的分布式文件系统的一部分进行交互是一种实用工具。
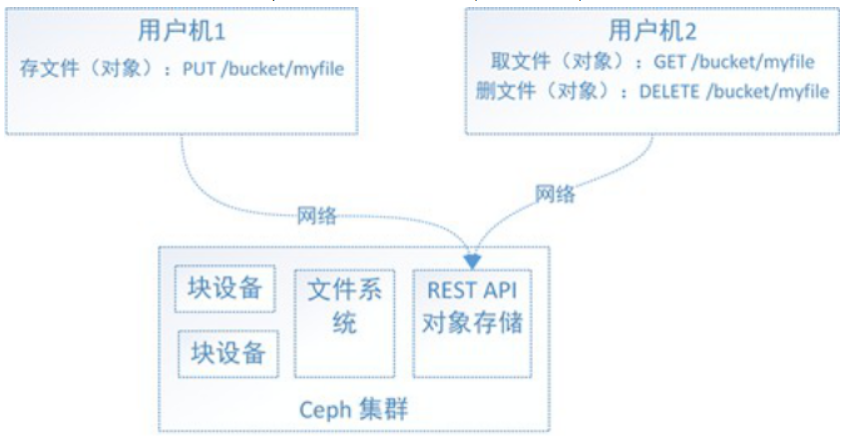
1、查看ceph集群中有多少个pool
rados lspools
# 同 ceph osd pool ls 输出结果一致
2、显示整个系统使用率
rados df
3、创建一个pool
ceph osd pool create test
4、创建一个对象object
rados create test-object -p test
5、查看对象文件
rados -p test ls
6、删除一个对象
rados rm test-object -p test
7、通过api接口使用 Ceph 存储存储
为了使用 Ceph SGW REST 接口, 我们需要为 S3 接口初始化一个 Ceph 对象网关用户. 然后为 Swif接口新建一个子用户,最后就可以通过创建的用户访问对象网关验证了。
官方文档:https://docs.ceph.com/en/latest/api/#ceph-restful-api
这里使用
radosgw-admin,radosgw-admin是 RADOS 网关用户管理工具,可用于创建和修改用户。
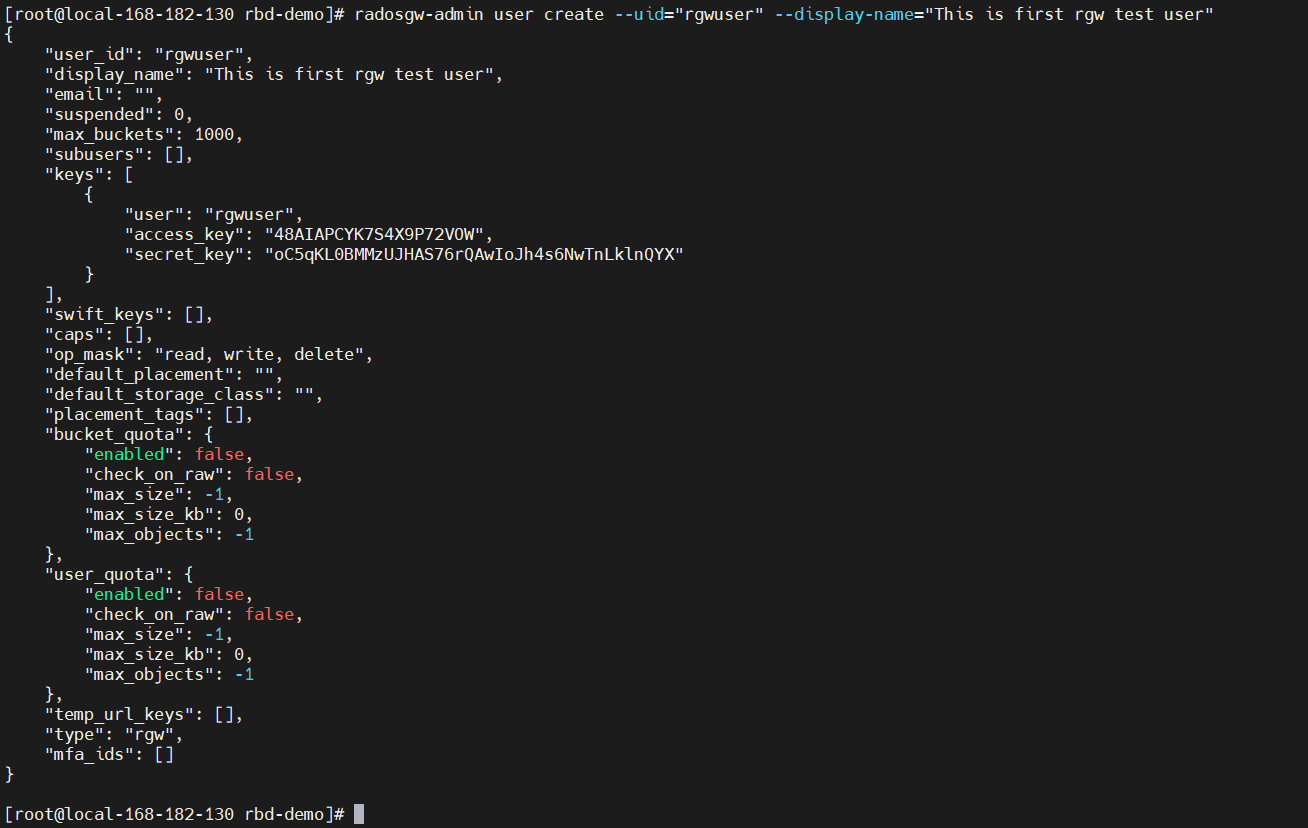
【1】创建 S3 网关用户
radosgw-admin user create --uid="rgwuser" --display-name="This is first rgw test user"
info
{
"user_id": "rgwuser",
"display_name": "This is first rgw test user",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [],
"keys": [
{
"user": "rgwuser",
"access_key": "48AIAPCYK7S4X9P72VOW",
"secret_key": "oC5qKL0BMMzUJHAS76rQAwIoJh4s6NwTnLklnQYX"
}
],
"swift_keys": [],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
【2】测试访问 S3 接口
#参照官方文档,我们需要编写一个 Python 测试脚本,该脚本将会连接 radosgw,然后新建一个新的 bucket 再列出所有的 buckets。脚本变量 aws_access_key_id 和 aws_secret_access_key 的值就是上边返回值中的 access_key 和 secret_key。
#首先,我们需要安装 python-boto 包,用于测试连接 S3。:
yum install python-boto -y
# 然后,编写 python 测试脚本。
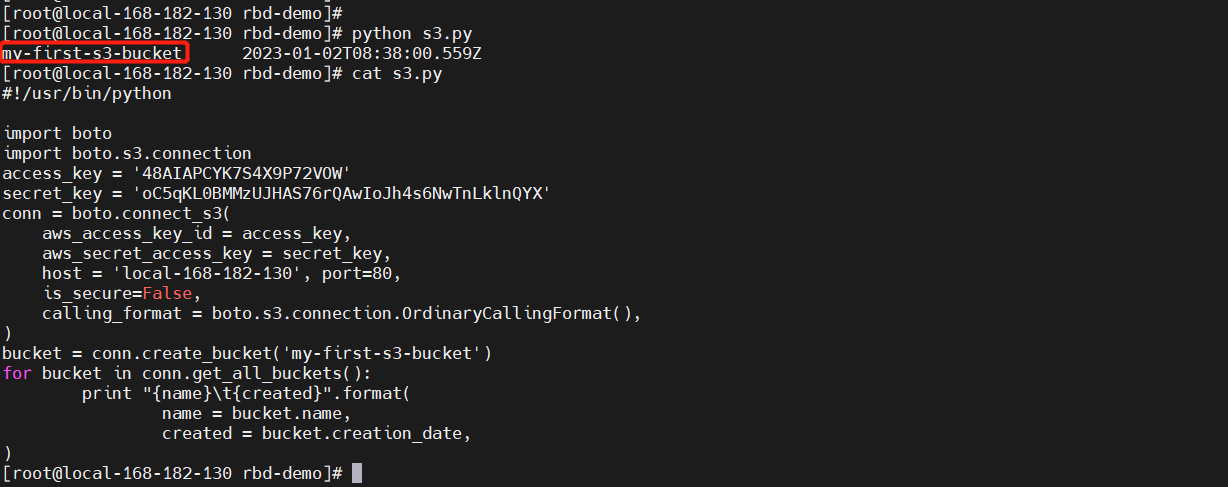
# cat s3.py
#!/usr/bin/python
import boto
import boto.s3.connection
access_key = '48AIAPCYK7S4X9P72VOW'
secret_key = 'oC5qKL0BMMzUJHAS76rQAwIoJh4s6NwTnLklnQYX'
conn = boto.connect_s3(
aws_access_key_id = access_key,
aws_secret_access_key = secret_key,
host = 'local-168-182-130', port=80,
is_secure=False,
calling_format = boto.s3.connection.OrdinaryCallingFormat(),
)
bucket = conn.create_bucket('my-first-s3-bucket')
for bucket in conn.get_all_buckets():
print "{name}t{created}".format(
name = bucket.name,
created = bucket.creation_date,
)
【温馨提示】这里使用了python-boto 包,使用认证信息连接 S3,然后创建了一个 my-first-s3-bucket 的 bucket,最后列出所有已创建的 bucket,打印名称和创建时间。
【3】创建 Swift 用户
#要通过 Swift 访问对象网关,需要 Swift 用户,我们创建subuser作为子用户。
radosgw-admin subuser create --uid=rgwuser --subuser=rgwuser:swift --access=full
info
{
"user_id": "rgwuser",
"display_name": "This is first rgw test user",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [
{
"id": "rgwuser:swift",
"permissions": "full-control"
}
],
"keys": [
{
"user": "rgwuser",
"access_key": "48AIAPCYK7S4X9P72VOW",
"secret_key": "oC5qKL0BMMzUJHAS76rQAwIoJh4s6NwTnLklnQYX"
}
],
"swift_keys": [
{
"user": "rgwuser:swift",
"secret_key": "6bgDOAsosiD28M0eE8U1N5sZeGyrhqB1ca3uDtI2"
}
],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
【4】创建密钥
radosgw-admin key create --subuser=rgwuser:swift --key-type=swift --gen-secret
#注意:返回的 Json 值中,我们要记住swift_keys中的secret_key 因为下边我们测试访问 Swift 接口时需要使用。secret_key以这条命令为准
info
{
"user_id": "rgwuser",
"display_name": "This is first rgw test user",
"email": "",
"suspended": 0,
"max_buckets": 1000,
"subusers": [
{
"id": "rgwuser:swift",
"permissions": "full-control"
}
],
"keys": [
{
"user": "rgwuser",
"access_key": "48AIAPCYK7S4X9P72VOW",
"secret_key": "oC5qKL0BMMzUJHAS76rQAwIoJh4s6NwTnLklnQYX"
}
],
"swift_keys": [
{
"user": "rgwuser:swift",
"secret_key": "AVThl3FGiVQW3VepkQl4Wsoyq9lbPlLlpKhXLhtR"
}
],
"caps": [],
"op_mask": "read, write, delete",
"default_placement": "",
"default_storage_class": "",
"placement_tags": [],
"bucket_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"user_quota": {
"enabled": false,
"check_on_raw": false,
"max_size": -1,
"max_size_kb": 0,
"max_objects": -1
},
"temp_url_keys": [],
"type": "rgw",
"mfa_ids": []
}
【5】测试访问 Swift 接口
#注意,以下命令需要python环境和可用的pip服务。
yum install python-pip -y
pip install --upgrade python-swiftclient
#测试
swift -A http://192.168.182.130/auth/1.0 -U rgwuser:swift -K 'AVThl3FGiVQW3VepkQl4Wsoyq9lbPlLlpKhXLhtR' list

【5】S3相关操作
# 1、删除S3用户
radosgw-admin user rm --uid=rgwuser
# 2、权限调整,允许rgwuser读写users信息:
radosgw-admin caps add --uid=rgwuser --caps="users=*"
# 3、允许admin读写所有的usage信息
radosgw-admin caps add --uid=rgwuser --caps="usage=read,write"
# 4、删除swift子用户
radosgw-admin subuser rm --subuser=rgwuser:swift
# 5、列出当前系统下所有的bucket信息
radosgw-admin bucket list
# 6、查看具体某个BUCKET属性
radosgw-admin bucket stats --bucket=my-first-s3-bucket
一般是通过api接口使用对象存储,这里只是演示了一个非常简单的示例。
分布式存储系统 Ceph 实战操作就先到这里了,有任何疑问的小伙伴欢迎给我留言或私信,后续会持续更新【大数据+云原生】方向的技术文章,请小伙伴耐心等。也可以关注我的公众号【大数据与云原生技术分享】!!!
最后
以上就是坚定小松鼠最近收集整理的关于分布式存储系统 Ceph 实战操作的全部内容,更多相关分布式存储系统内容请搜索靠谱客的其他文章。








发表评论 取消回复