文章目录
- 前言
- 1、ZooKeeper特点
- 1.1 ZooKeeper集群节点数必须是基数
- 1.2 ZooKeeper 集群至少要有三个节点
- 2 zookeeper客户端Curator
- 2.1 引入依赖
- 2.2 创建会话
前言
高并发系统为了应对流量增长需要进行节点的横向扩展,所以高并发系统往往都是分布式系统。高并发系统基本都需要进行节点与节点之间的配合协调,这就需要用到分布式协调中间件(如ZooKeeper)。
简单来说,ZooKeeper=文件系统+通知机制,和设计模式里的观察者模式很像。
ZooKeeper在实际生产环境中应用非常广泛,比如SOA的服务监控系统,大数据基础平台Hadoop、Spark的分布式调度系统。ZooKeeper提供的服务包括:统一命名服务、统一配置管理、统一集群管理、服务器节点动态上下线、软负载均衡等。
https://zookeeper.apache.org/doc/current/zookeeperStarted.html
1、ZooKeeper特点
ZooKeeper节点数有以下要求:
1.1 ZooKeeper集群节点数必须是基数
ZooKeeper集群中需要一个主节点,称为Leader节点,并且Leader节点是集群通过选举规则从所有节点中选出来的,简称为选主。选主规则中很重要的一条是:要求“可用节点数量 > 总节点数量/2”。如果是偶数个节点,则会出现不满足这个规则的情况,比如出现“可用节点数量=总节点数量/2”的情况时就不满足选主的规则。
说明:
为什么要“可用节点数量 > 总节点数量/2”呢?为了防止集群脑裂(Split-Brain)。脑裂是分布式系统的共性问题,ElasticSearch集群也面临此问题。脑裂是一个形象的比喻,好比“大脑分裂”,也就是说本来一个“大脑”,却被拆分为两个或多个“大脑”。集群脑裂是由于网络断了,一个集群被分成了两个集群。ZooKeeper集群、ElasticSearch集群都使用一种简单的节点数过半机制来确保集群被分裂后还能正常工作。过半机制是指“可用节点数量 > 总节点数量/2”时,集群才是可用的,才可以对外服务;否则集群是非可用的,不可以提供服务。
1.2 ZooKeeper 集群至少要有三个节点
一个节点的ZooKeeper服务可以正常启动和提供服务,但是一个节点的ZooKeeper服务不能叫作集群,其可靠性会大打折扣,仅仅作为学习使用。正常情况下,搭建ZooKeeper集群至少需要三个节点。
2 zookeeper客户端Curator
Curator是Netflix公司开源的⼀套zookeeper客户端框架,Curator是对Zookeeper⽀持最好的客户端框架。Curator封装了⼤部分Zookeeper的功能,⽐如Leader选举、分布式锁等,减少了技术⼈员在使⽤Zookeeper时的底层细节开发⼯作。
2.1 引入依赖
兼容性介绍
,Curator现在最新版本是Curator 5.4,Curator 5.0以上版本对ZooKeeper 3.5.0以上版本有很强的依赖性如果您使用的是ZooKeeper 3.5.x,则无需执行任何操作 - 只需使用Curator 4.0即可。生产上也有很多3.4.x的版本,对ZooKeeper 3.4.x也是兼容的,但是你必须在maven依赖中排除 zookeeper依赖包,
在我手动从官网下载的apache-curator-5.2.0 包中,他的pom.xml文件有如下代码,但是我部署的zookeeper服务是3.7.1的(最新版),可能curator还没适配好3.7.0的zookeeper,原生的zookeeper API已经到了3.7.0。我这里先使用curator-5.2.0做尝试。
请务必重视curator和zookeeper之间的版本依赖关系

如下:
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>5.2.0</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-api</artifactId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>5.2.0</version>
</dependency>
Curator 项目组成
| 模块名称 | 描述 |
|---|---|
| curator-recipes | 所有典型应用场景。例如:分布式锁,Master选举等。需要依赖client和framework,需设置自动获取依赖 |
| curator-async | 异步操作 |
| curator-framework | Zookeeper API的高层封装,大大简化Zookeeper客户端编程,添加了例如Zookeeper连接管理、重试机制等。 |
| curator-client | Zookeeper client的封装,用于取代原生的Zookeeper客户端(ZooKeeper类),提供一些非常有用的客户端特性。 |
| curator-test | 包含TestingServer,TestingCluster和一些其他有助于测试的工具。 |
| curator-examples | 各种使用Curator特性的例子。 |
| curator-x-discovery | 服务注册发现,在SOA /分布式系统中,服务需要相互寻找。curator-x-discovery提供了服务注册,找到特定服务的单个实例,和通知服务实例何时更改。 |
| curator-x-discovery-server | 服务注册发现管理器,可以和curator-x-discovery 或者非java程序程序使用RESTful Web服务以注册,删除,查询等服务。 |
2.2 创建会话
Curator的创建会话方式与原生的API创建方式区别很大。Curator创建客户端为CuratorFramework,是由CuratorFrameworkFactory工厂类来实现的,CuratorFramework是线程安全的,要连接的每个ZooKeeper集群只需要一个 CuratorFramework对象就可以了。
Fluent风格的API调用其实,就是通过调用方法来给实例里面的属性进行注入填充,所以可以做到链式调用的Fluent风格
CuratorFrameworkFactory提供了两类三种构造CuratorFramework的方法,一种是直接newClient,还有一种方式是使用CuratorFrameworkFactory.builder(),提供了细粒度的控制。
这里我们直接贴出源码,源码路径,如果大家学有余力,请务必阅读源码,否则很容易被学艺不精人的博客误导,采用截图的方式是方便大家快速定位代码,点击下载Curator5.4.0源码
curator-mastercurator-frameworksrcmainjavaorgapachecuratorframeworkCuratorFrameworkFactory.java
构造CuratorFramework对象的方法一:

import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode;
import org.junit.Test;
public class ZookeeperDemo {
//1:创建Znode节点-永久节点
@Test
public void createZnode() throws Exception {
//1:制定重试策略
/**
* param1:重试间隔时间
* param2:最多重试次数
*/
RetryPolicy backoffRetry = new ExponentialBackoffRetry(1000, 5);
//2:获取Zookeeper的客户端对象
String connectList = "node1:2181,node2:2181,node3:2181";
//String connectList = "node1:2181,node2:2181,node3:2181"; //修改C:WindowsSystem32driversetchosts
CuratorFramework client = CuratorFrameworkFactory.newClient(connectList, backoffRetry);
//3:启动客户端
client.start();
//4:使用客户端对象来对节点进行增删改查---创建节点
client
.create() //创建节点
.creatingParentsIfNeeded() //如果父节点不存在,则创建父节点
.withMode(CreateMode.PERSISTENT) //创建永久节点
.forPath("/xxx/818/zzz", "牛逼啊".getBytes());//指定节点的路径和数据
//5:关闭客户端
client.close();
}
}
构造CuratorFramework对象的方法二:
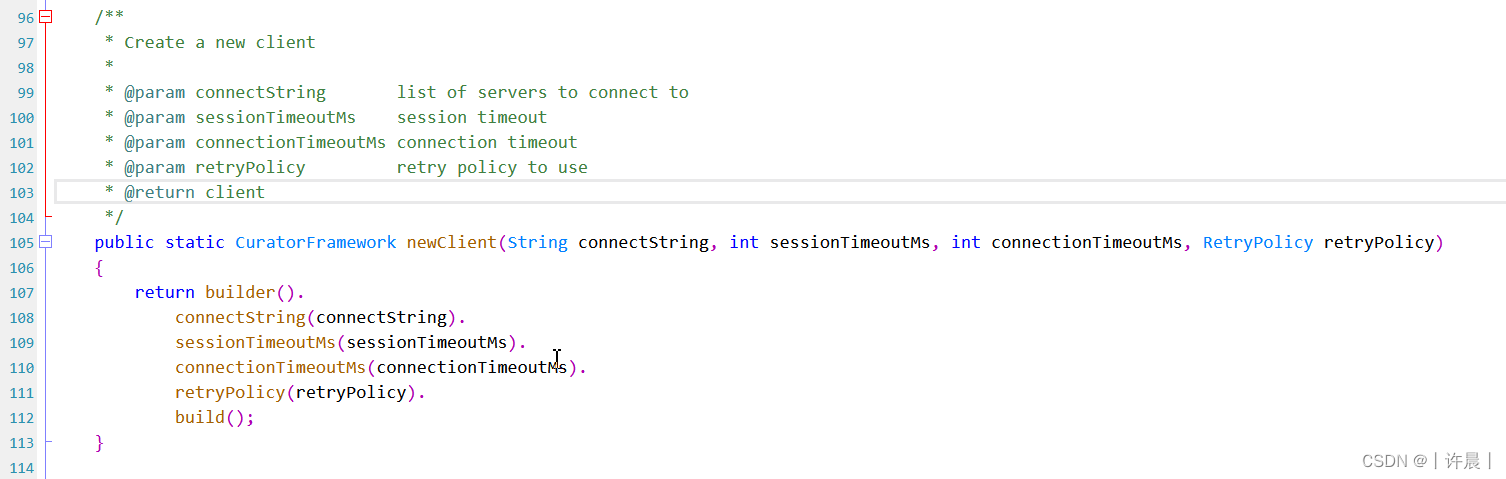
import org.apache.curator.RetryPolicy;
import org.apache.curator.framework.CuratorFramework;
import org.apache.curator.framework.CuratorFrameworkFactory;
import org.apache.curator.framework.state.ConnectionState;
import org.apache.curator.retry.ExponentialBackoffRetry;
import org.apache.zookeeper.CreateMode;
import org.junit.Test;
public class ZookeeperDemo2 {
//1:创建Znode节点-永久节点
@Test
public void createZnode() throws Exception {
//1:制定重试策略
/**
* param1:重试间隔时间
* param2:最多重试次数
*/
RetryPolicy backoffRetry = new ExponentialBackoffRetry(1000, 5);
//2:获取Zookeeper的客户端对象
String connectList = "node1:2181,node2:2181,node3:2181";
//String connectList = "node1:2181,node2:2181,node3:2181"; //修改C:WindowsSystem32driversetchosts
CuratorFramework client = CuratorFrameworkFactory.builder()
.connectString(connectList)
.sessionTimeoutMs(5000)
.connectionTimeoutMs(5000)
.retryPolicy(backoffRetry)
.build();
//3:启动客户端
client.start();
//4:使用客户端对象来对节点进行增删改查---创建节点
client
.create() //创建节点
.creatingParentsIfNeeded() //如果父节点不存在,则创建父节点
.withMode(CreateMode.PERSISTENT) //创建永久节点
.forPath("/xxx/828/zzz", "牛逼啊".getBytes());//指定节点的路径和数据
//5:关闭客户端
client.close();
}
}
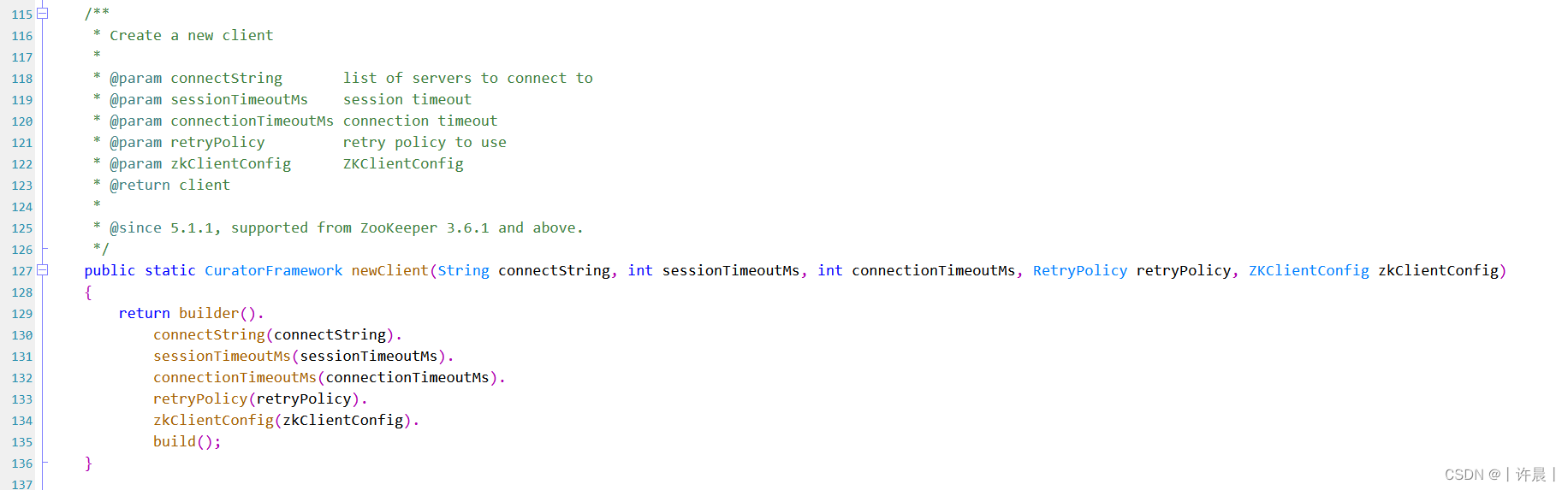
构造CuratorFramework对象的方法三:
注意,本方法要求你的Curator版本不低于5.1.1,zookeeper版本不低于3.6.1,新增了zkClientConfig参数。
参数说明
| 参数名称 | 说明 |
|---|---|
| connectString | zookeeper的服务器地址,集群中多个zookeeper服务器以逗号分隔 |
| sessionTimeoutMs | 会话超时时间,默认是60S |
| connectionTimeoutMs | 连接超时时间,默认是15S |
| retryPolicy | 失败重试策略 |
static final String ZK_SERVER_CLUSTER = "192.168.48.101:2181,192.168.48.102:2181,192.168.48.103:2181";
[main-SendThread(192.168.48.103:2181)] INFO org.apache.zookeeper.ClientCnxn - SASL config status: Will not attempt to authenticate using SASL (unknown error)
最后
以上就是活泼蚂蚁最近收集整理的关于【博学谷学习记录】超强总结,用心分享丨大数据超神之路(四):ZooKeeper开发必知必会前言1、ZooKeeper特点2 zookeeper客户端Curator的全部内容,更多相关【博学谷学习记录】超强总结,用心分享丨大数据超神之路(四):ZooKeeper开发必知必会前言1、ZooKeeper特点2内容请搜索靠谱客的其他文章。








发表评论 取消回复