1.什么是IOC
IOC是Inversion of Control的缩写,多数书籍翻译成“控制反转”。
1996年,Michael Mattson在一篇有关探讨面向对象框架的文章中,首先提出了IOC 这个概念。对于面向对象设计及编程的基本思想,前面我们已经讲了很多了,不再赘述,简单来说就是把复杂系统分解成相互合作的对象,这些对象类通过封装以后,内部实现对外部是透明的,从而降低了解决问题的复杂度,而且可以灵活地被重用和扩展。
IOC理论提出的观点大体是这样的:借助于“第三方”实现具有依赖关系的对象之间的解耦。如下图:
图3 IOC解耦过程
大家看到了吧,由于引进了中间位置的“第三方”,也就是IOC容器,使得A、B、C、D这4个对象没有了耦合关系,齿轮之间的传动全部依靠“第三方”了,全部对象的控制权全部上缴给“第三方”IOC容器,所以,IOC容器成了整个系统的关键核心,它起到了一种类似“粘合剂”的作用,把系统中的所有对象粘合在一起发挥作用,如果没有这个“粘合剂”,对象与对象之间会彼此失去联系,这就是有人把IOC容器比喻成“粘合剂”的由来。
我们再来做个试验:把上图中间的IOC容器拿掉,然后再来看看这套系统:
图4 拿掉IOC容器后的系统
我们现在看到的画面,就是我们要实现整个系统所需要完成的全部内容。这时候,A、B、C、D这4个对象之间已经没有了耦合关系,彼此毫无联系,这样的话,当你在实现A的时候,根本无须再去考虑B、C和D了,对象之间的依赖关系已经降低到了最低程度。所以,如果真能实现IOC容器,对于系统开发而言,这将是一件多么美好的事情,参与开发的每一成员只要实现自己的类就可以了,跟别人没有任何关系!
我们再来看看,控制反转(IOC)到底为什么要起这么个名字?我们来对比一下:
软件系统在没有引入IOC容器之前,如图1所示,对象A依赖于对象B,那么对象A在初始化或者运行到某一点的时候,自己必须主动去创建对象B或者使用已经创建的对象B。无论是创建还是使用对象B,控制权都在自己手上。
软件系统在引入IOC容器之后,这种情形就完全改变了,如图3所示,由于IOC容器的加入,对象A与对象B之间失去了直接联系,所以,当对象A运行到需要对象B的时候,IOC容器会主动创建一个对象B注入到对象A需要的地方。
通过前后的对比,我们不难看出来:对象A获得依赖对象B的过程,由主动行为变为了被动行为,控制权颠倒过来了,这就是“控制反转”这个名称的由来。
3.IOC也叫依赖注入(DI)
2004年,Martin Fowler探讨了同一个问题,既然IOC是控制反转,那么到底是“哪些方面的控制被反转了呢?”,经过详细地分析和论证后,他得出了答案:“获得依赖对象的过程被反转了”。控制被反转之后,获得依赖对象的过程由自身管理变为了由IOC容器主动注入。于是,他给“控制反转”取了一个更合适的名字叫做“依赖注入(Dependency Injection)”。他的这个答案,实际上给出了实现IOC的方法:注入。所谓依赖注入,就是由IOC容器在运行期间,动态地将某种依赖关系注入到对象之中。
所以,依赖注入(DI)和控制反转(IOC)是从不同的角度的描述的同一件事情,就是指通过引入IOC容器,利用依赖关系注入的方式,实现对象之间的解耦。
学过IOC的人可能都看过Martin Fowler(老马,2004年post)的这篇文章:Inversion of Control Containers and the Dependency Injection pattern[2]。
博客园的园友EagleFish(邢瑜琨)的文章: 深度理解依赖注入(Dependence Injection)[3]对老马那篇经典文章进行了解读。
CSDN黄忠成的Inside ObjectBuilder[4]也是,不过他应该来自台湾省,用的是繁体,看不管繁体中文的,可以看园中的吕震宇博友的简体中文版[转]Object Builder Application Block[5] 。
4.IOC的优缺点
In my experience, IoC using the Spring container brought the following advantages[6]:
flexibility
changing the implementation class for a widely used interface is simpler (e.g. replace a mock web service by the production instance)
changing the retrieval strategy for a given class is simpler (e.g. moving a service from the classpath to the JNDI tree)
adding interceptors is easy and done in a single place (e.g. adding a caching interceptor to a JDBC-based DAO)
readability
the project has one unified and consistent component model and is not littered with factories (e.g. DAO factories)
the code is briefer and is not littered without dependency lookup code (e.g. calls to JNDI InitialContext)
testability
dependencies are easy to replace mocks when they’re exposed through a constructor or setter
easier testing leads to more testing
more testing leads to better code quality, lower coupling, higher cohesion
使用IOC框架产品能够给我们的开发过程带来很大的好处,但是也要充分认识引入IOC框架的缺点,做到心中有数,杜绝滥用框架[1]。
第一、软件系统中由于引入了第三方IOC容器,生成对象的步骤变得有些复杂,本来是两者之间的事情,又凭空多出一道手续,所以,我们在刚开始使用IOC框架的时候,会感觉系统变得不太直观。所以,引入了一个全新的框架,就会增加团队成员学习和认识的培训成本,并且在以后的运行维护中,还得让新加入者具备同样的知识体系。
第二、由于IOC容器生成对象是通过反射方式,在运行效率上有一定的损耗。如果你要追求运行效率的话,就必须对此进行权衡。
第三、具体到IOC框架产品(比如:Spring)来讲,需要进行大量的配制工作,比较繁琐,对于一些小的项目而言,客观上也可能加大一些工作成本。
第四、IOC框架产品本身的成熟度需要进行评估,如果引入一个不成熟的IOC框架产品,那么会影响到整个项目,所以这也是一个隐性的风险。
我们大体可以得出这样的结论:一些工作量不大的项目或者产品,不太适合使用IOC框架产品。另外,如果团队成员的知识能力欠缺,对于IOC框架产品缺乏深入的理解,也不要贸然引入。最后,特别强调运行效率的项目或者产品,也不太适合引入IOC框架产品,像WEB2.0网站就是这种情况。
2.Vue路由实现
Location对象的属性
属性 描述
hash 设置或返回从井号 (#) 开始的 URL(锚)。
host 设置或返回主机名和当前 URL 的端口号。
hostname 设置或返回当前 URL 的主机名。
protocol 设置或返回当前 URL 的协议。
href 设置或返回完整的 URL。
pathname 设置或返回当前 URL 的路径部分。
port 设置或返回当前 URL 的端口号。
search 设置或返回从问号 (?) 开始的 URL(查询部分)。
Location对象的方法
方法 描述
assign() 加载新的文档。
reload() 重新加载当前文档。
replace() 用新的文档替换当前文档。
hashchange() 监听hashchange变化。
上面的属性和方法中除了hash,其他都会重新加载页面。
H5中的History对象的属性(部分)
属性 描述
length 历史记录数组的长度
state 表示当前的处在哪个记录上
H5中的History对象的方法(部分)
方法 描述
back() 等效于用户点击回退按钮
forward() 等效于用户点击前进按钮
go(num) 通过指定一个相对于当前页面位置的数值加载页面
pushState(json, “”, url) 添加一条记录
replaceState(json, “”, url) 替换掉一条记录
其中pushState方法和replaceState方法可以分别增加和替换掉一条记录(必须同源),而不会重新加载页面。
window.location.hash和window.history.pushState(或replaceState)唯一的不同是通过hash改变url带入#,而后者不会。而Vue 路由的两种模式就是基于location和history这2个对象的!
ps:注意这里可以通过重写pushstate和replacestate实现对history模式路由的监听
3.Vue路由钩子函数
路由的钩子函数总结有6个
全局的路由钩子函数:beforeEach、afterEach
单个的路由钩子函数:beforeEnter
组件内的路由钩子函数:beforeRouteEnter、beforeRouteLeave、beforeRouteUpdate
模块一:全局导航钩子函数
1、vue router.beforeEach(全局前置守卫)
beforeEach的钩子函数,它是一个全局的before 钩子函数,
(beforeEach)意思是在 每次每一个路由改变的时候都得执行一遍。
它的三个参数:
to: (Route路由对象) 即将要进入的目标 路由对象 to对象下面的属性: path params query hash fullPath matched name meta(在matched下,但是本例可以直接用)
from: (Route路由对象) 当前导航正要离开的路由
next: (Function函数) 一定要调用该方法来 resolve 这个钩子。 调用方法:next(参数或者空) ***必须调用
next(无参数的时候): 进行管道中的下一个钩子,如果走到最后一个钩子函数,那么 导航的状态就是 confirmed (确认的)
next(’/’) 或者 next({ path: ‘/’ }): 跳转到一个不同的地址。当前的导航被中断,然后进行一个新的导航。
应用场景:可进行一些页面跳转前处理,例如判断需要登录的页面进行拦截,做登录跳转!!
router.beforeEach((to, from, next) => {
if (to.meta.requireAuth) {
//判断该路由是否需要登录权限
if (cookies(‘token’)) {
//通过封装好的cookies读取token,如果存在,name接下一步如果不存在,那跳转回登录页
next()//不要在next里面加"path:/",会陷入死循环
}
else {
next({
path: ‘/login’,
query: {redirect: to.fullPath}//将跳转的路由path作为参数,登录成功后跳转到该路由
})
}
}
else {
next()
}
})
2、vue router.afterEach(全局后置守卫)
router.beforeEach 是页面加载之前,相反router.afterEach是页面加载之后
模块二:路由独享的守卫(路由内钩子)
你可以在路由配置上直接定义 beforeEnter 守卫:
const router = new VueRouter({
routes: [
{
path: ‘/foo’,
component: Foo,
beforeEnter: (to, from, next) => {
// …
}
}
]
这些守卫与全局前置守卫的方法参数是一样的。
模块三:组件内的守卫(组件内钩子)
1、beforeRouteEnter、beforeRouteUpdate、beforeRouteLeave
const Foo = {
template: ...,
beforeRouteEnter (to, from, next) {
// 在渲染该组件的对应路由被 confirm 前调用
// 不!能!获取组件实例 this
// 因为当钩子执行前,组件实例还没被创建
},
beforeRouteUpdate (to, from, next) {
// 在当前路由改变,但是该组件被复用时调用
// 举例来说,对于一个带有动态参数的路径 /foo/:id,在 /foo/1 和 /foo/2 之间跳转的时候,
// 由于会渲染同样的 Foo 组件,因此组件实例会被复用。而这个钩子就会在这个情况下被调用。
// 可以访问组件实例 this
},
beforeRouteLeave (to, from, next) {
// 导航离开该组件的对应路由时调用
// 可以访问组件实例 this
}
4.Vue如何自定义一个过滤器
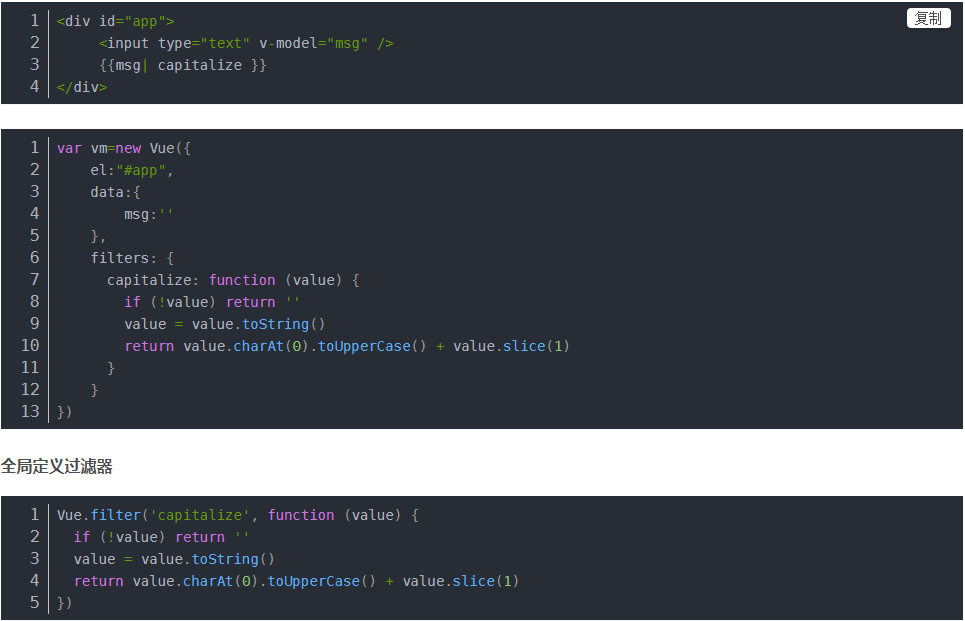
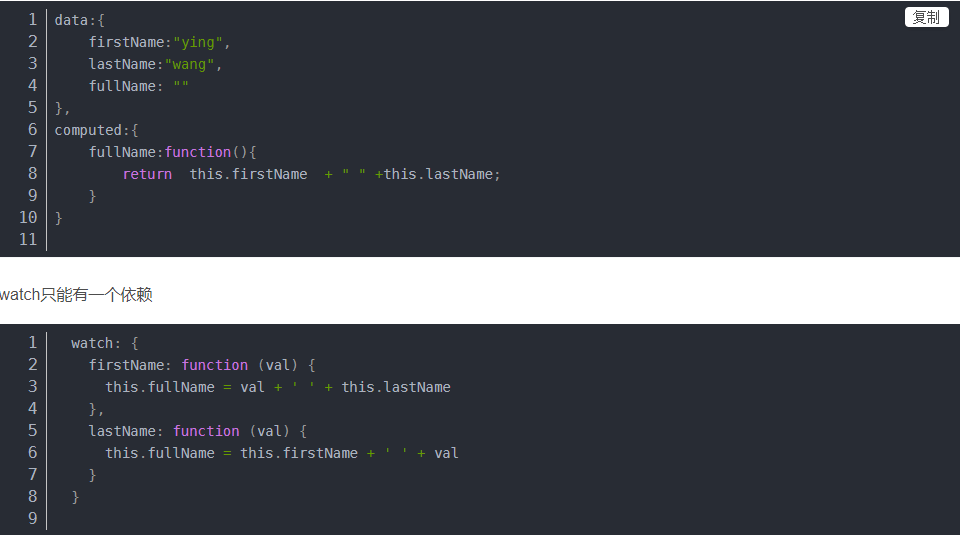
5.什么是跨域
跨域,是指浏览器不能执行其他网站的脚本。它是由浏览器的同源策略造成的,是浏览器对JavaScript实施的安全限制。
这里说明一下,无法跨域是浏览器对于用户安全的考虑,如果自己写个没有同源策略的浏览器,完全不用考虑跨域问题了。是浏览器的锅,对。
同源策略限制了一下行为:
Cookie、LocalStorage 和 IndexDB 无法读取
DOM 和 JS 对象无法获取
Ajax请求发送不出去
6.如果表的数据比较大,如何提高查询效率?
一、数据库设计方面
1、对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引;
2、应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num is null 可以在num上设置默认值0,确保表中num列没有null值,然后这样查询: select id from t where num = 0;
3、并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,查询可能不会去利用索引,如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用;
4、索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要;
5、应尽可能的避免更新索引数据列,因为索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新索引数据列,那么需要考虑是否应将该索引建为索引;
6、尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了;
7、尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些;
8、尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引);
9、避免频繁创建和删除临时表,以减少系统表资源的消耗;
10、临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表;
11、在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert;
12、如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
二、SQL语句方面
1、应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描;
2、应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如: select id from t where num=10 or num=20 可以这样查询: select id from t where num=10 union all select id from t where num=20;
3、in 和 not in 也要慎用,否则会导致全表扫描,如: select id from t where num in(1,2,3) 对于连续的数值,能用 between 就不要用 in 了: select id from t where num between 1 and 3;
4、下面的查询也将导致全表扫描: select id from t where name like ‘%abc%’
5、如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描: select id from t where num=@num 可以改为强制查询使用索引: select id from t with(index(索引名)) where num=@num;
6、应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where num/2=100 应改为: select id from t where num=100*2;
7、应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如: select id from t where substring(name,1,3)=’abc’–name以abc开头的id,select id from t where datediff(day,createdate,’2005-11-30′)=0–‘2005-11-30’生成的id 应改为: select id from t where name like ‘abc%’ select id from t where createdate>=’2005-11-30′ and createdate<’2005-12-1′
8、不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
9、不要写一些没有意义的查询,如需要生成一个空表结构: select col1,col2 into #t from t where 1=0 这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样: create table #t(…)
10、很多时候用 exists 代替 in 是一个好的选择: select num from a where num in(select num from b) 用下面的语句替换: select num from a where exists(select 1 from b where num=a.num)
11、任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
12、尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
13、尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
14、尽量避免大事务操作,提高系统并发能力。
7.什么是回调函数?
我们绕点远路来回答这个问题。
编程分为两类:系统编程(system programming)和应用编程(application programming)。所谓系统编程,简单来说,就是编写库;而应用编程就是利用写好的各种库来编写具某种功用的程序,也就是应用。系统程序员会给自己写的库留下一些接口,即API(application programming interface,应用编程接口),以供应用程序员使用。所以在抽象层的图示里,库位于应用的底下。
当程序跑起来时,一般情况下,应用程序(application program)会时常通过API调用库里所预先备好的函数。但是有些库函数(library function)却要求应用先传给它一个函数,好在合适的时候调用,以完成目标任务。这个被传入的、后又被调用的函数就称为回调函数(callback function)。
打个比方,有一家旅馆提供叫醒服务,但是要求旅客自己决定叫醒的方法。可以是打客房电话,也可以是派服务员去敲门,睡得死怕耽误事的,还可以要求往自己头上浇盆水。这里,“叫醒”这个行为是旅馆提供的,相当于库函数,但是叫醒的方式是由旅客决定并告诉旅馆的,也就是回调函数。而旅客告诉旅馆怎么叫醒自己的动作,也就是把回调函数传入库函数的动作,称为登记回调函数(to register a callback function)。如下图所示
10.对异步加载的理解
比如说web网站加载一些网络资源,是使用同步方法请求,那么此时web网站的用户界面将会阻塞,直到该方法完成对资源的网络调用,并完成结果分析。
完成这些调用所需的时间取决与网络速度,以及服务器当前的工作量。
对于用户来说,界面卡掉、一段时间的等待都是不愉快的。
所以使用异步调用。
异步可以避免阻塞,在此期间可以做更多的事情。
但是异步有一个缺陷,相对于同步来说,它对于程序的流程充满了不确定性,顺序可能会颠倒。
所以在某些场景,比如说有多个异步方法被调用,他们是有依赖关系的,后面的异步方法需要使用到之前异步方法的结果,我们需要按顺序调用这些异步方法,这个时候就需要使用async、await关键字来等待执行的结果,但是它不会阻塞线程。
最后
以上就是暴躁机器猫最近收集整理的关于前端VUE及PHP常见业务场景概括小结(程序猿提薪必备!!!)的全部内容,更多相关前端VUE及PHP常见业务场景概括小结(程序猿提薪必备内容请搜索靠谱客的其他文章。








发表评论 取消回复