对于这个问题,一开始本人也是对于在做题的时候出现的一个小bug。
有必要说明一下,笔者也是一个小菜鸡,有什么说的不好的,欢迎指正。
编译器回车问题简要描述:
1 在对于一个可以多次输入的程序来说(简单来说就是输入的时候是利用Scanner.hasNext()方法进行处理的),这样的程序往往可以进行一个多组数据的处理,如果有兴趣的话,可以进行一个最为简单的测试。
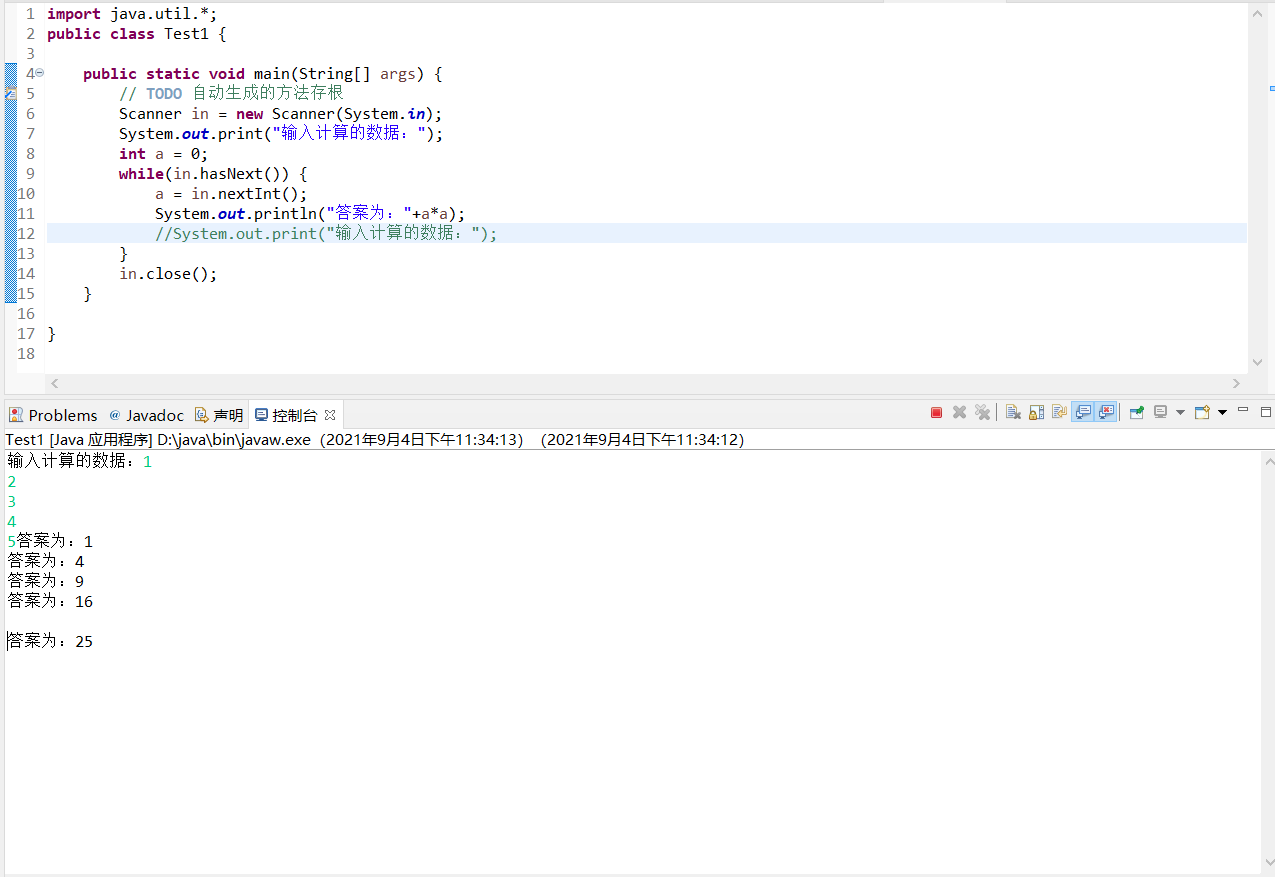
这是我做的一个简单的程序,你会发现 在多组数据的输入以后,除了最后一组数据的结果没有出来,其他的都出来了,对于这个时候你再敲一次回车,这才最后一个结果才会出来,其实在这个时候,最后出来的结果已经不是预想的结果了。
在最后的结果中,其中的空格回车也是非常显眼。
对于这个的原理,通过我查阅资料以及自身的经验来说的话,第一次复制粘贴以后结果马上就出来了,这是以为在原本的文本中就是最后一次的换行没有粘贴进去,也就是说除了最后一个数据其他数据的回车是我们已经敲好了的,而最后的一个回车是我们没有敲的,当我们粘贴进去以后也就是最后一个没有出数据了,当我们把这个回车敲进去以后,这个时候输出的过程中就已经记住了一个回车,所以这个时候在数据的输出中才会多出一行空行,其实本质上来说这个空行是我们自己敲进去的。
如果实在无法理解的话,也可以说是我们在测试数据粘贴的时候,少粘贴了一个回车。
而恰恰这个回车就是最致命的,因为我们在对于in.hasNext(),这个方法的读取是以回车为结束标志的,所以这才会有多出一个空行。
2. 而对于需要不定个以空格分隔的数据,需要当以回车结束的处理数据的方法具体如下。
其实说起来目前我掌握的方法,大同小异,简单来说就是把数据以in.nextLine();用以读取,众所周知,这样读出来的是一个String类型的数据。
第一种方法:
将读取的String类型进行一个以空格做一个分隔,其后对于其中的数据进行一个数据转化后进行一个处理。
第二种方法:
创建两个Scanner对象,将第一个对象读取的字符串保存以后,将其传入第二个Scanner对象中,而此时第二个对象以一定的规则进行一个读取,读取以后在进行一个数据处理。
这其中,笔者也就实现一个,另一个类似。
ArrayList<Integer> arr = new ArrayList() ;
System.out.println("Enter a space separated list of numbers:");
Scanner in = new Scanner(System.in);
String line = in.nextLine();
Scanner in2 = new Scanner(line);
while(in2.hasNextInt()){
arr.add(in2.nextInt());
}
System.out.println("The numbers were:"+arr.toString());对了另外唠叨一句,对于一般的初学者尽量有一个良好的代码编写规则,因为你写的代码不是给你一个人看的,是一个团队看的,以后这样别人帮你改代码会方便很多。
其次代码复用率尽量高(泛型),一个代码好不好,除了效率重要,另一个重要的就是简洁,这就是要求编程人员提高代码的复用率,这样也方便别人看你的代码,这其中比较好用的方法笔者认为是泛型(将一个需要多次操作的点作为一个泛型类),这个也不会很难,掌握一下也不是难事。
如果泛型学习需要帮忙,可以用得上笔者的,一定尽力帮忙。这里也对一个泛型类的模板仅供参考。
import java.util.*;
class GnnericsA<T>{
T t;
String st;
public T sum(T t1){
if(st.equals("I")) {
int i = Integer.parseInt((String)t1);
int j = Integer.parseInt((String)t);
Integer c = j + i;
return (T)("整数类,和为"+c);
}else {
String fa = (String)t1;
String fb = (String)t;
String fc = fb+"-"+fa;
return (T)("字符串类,和为"+fc);
}
}
public GnnericsA(T t, String st) {
this.t = t;
this.st = st;
}
}
public class Main4 {
public static void main(String[] args) {
Scanner in = new Scanner(System.in);
int i1=1;
while(in.hasNext()) {
String st = in.next();
String st2 = in.next();
String st3 = in.next();
GnnericsA<String> ga = new GnnericsA<String>(st2,st);
System.out.println("Case "+i1+++":"+ga.sum(st3));
}
in.close();
}
}
还有一个尽量在创建项目的时候尽量建个包,因为这样能提高代码的复用率,这样出来的代码其他的程序中可以进行一个引用。
最后
以上就是典雅白云最近收集整理的关于编译器在处理多组数据多出的强制回车与数据多次输入以回车结束的数据处理方法。与泛型的相关实现。的全部内容,更多相关编译器在处理多组数据多出内容请搜索靠谱客的其他文章。








发表评论 取消回复