在容器中注册web三大主键:
- 方法一:采用web.xml
- 方法二:使用注解@WebServlet、@WebFilter、@WebListener代替xml配置
- 方法三:使用SPI - 服务动态扩展
SPI(服务动态扩展):人 家提供了一个类去读取我指定目录下的文件,读取文件的内容通过反射创建对象
- 工程结构
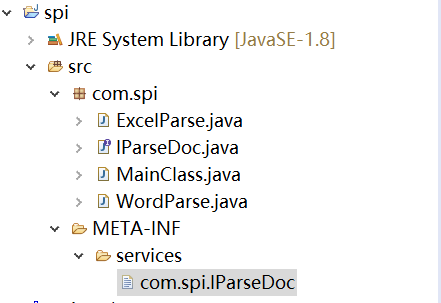
- 解析文档接口
/**
* 解析文档接口
* @author mimi
*
*/
public interface IParseDoc {
void parse();
}
- 实现类解析Excel
public class ExcelParse implements IParseDoc {
public void parse() {
System.out.println("解析 excel");
}
public ExcelParse() {
System.out.println("ExcelParse 无参构造");
}
}
- 实现类解析Word
public class WordParse implements IParseDoc {
public void parse() {
System.out.println("解析 Word");
}
}
-
配置文件
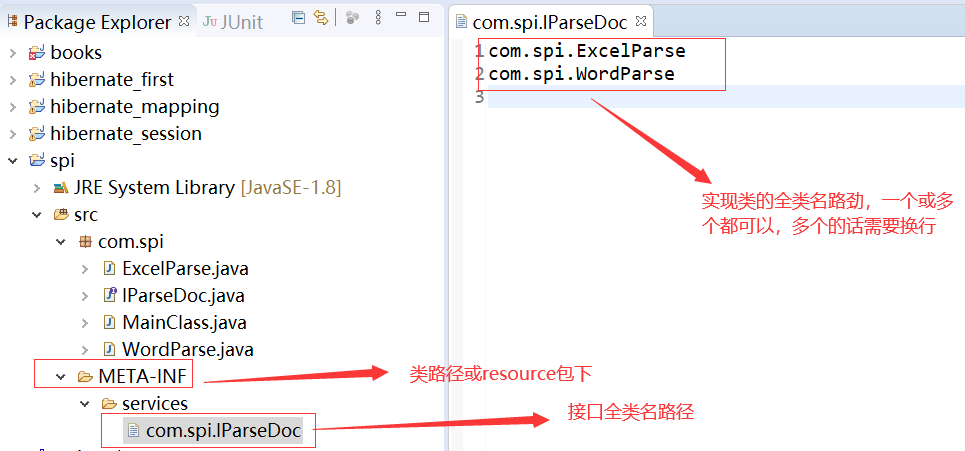
-
main
import java.util.Iterator;
import java.util.ServiceLoader;
/*
* 使用SPI的机制:
*1、当服务提供者提供了接口的一种具体实现后,在工程中的META-INF/services目录下创建一个以“按口全限定名”为命名的文件, 内容为实现类的全限定名
*2、接口实现类所在的工程classpath中:
*3、主程序通过java.util.ServiceLoder动态装载实现模块,它通过扫描META-INF/services目录下的配置文件找到实现类的全限定名
*4、SPI的实现类必须携带个不带 参数的构造方法;
*/
public class MainClass {
public static void main(String[] args) {
ServiceLoader<IParseDoc> iParseDocs=ServiceLoader.load(IParseDoc.class);
Iterator<IParseDoc> iParseDocIterator=iParseDocs.iterator();
while(iParseDocIterator.hasNext()) {
iParseDocIterator.next().parse();
}
}
}
- 结果
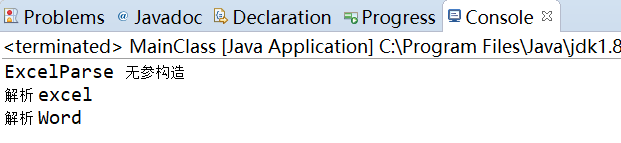
最后
以上就是个性黄蜂最近收集整理的关于SPI - 服务动态扩展的全部内容,更多相关SPI内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复