数据拆分写入Excel并压缩
上篇Poi版本升级优化中讲到了如果不做poi版本升级, 遇到大数据量时, 可以通过将数据拆分的方式写入到多个Excel文件中并压缩后提供给前端下载.
1. 实现思想
(1) 设置一个
阈值, 当数据量大于该阈值时就将数据量拆分进行写入Excel;(2) 如何拆分? 数据量对阈值
取模:
模为阈值的整数n倍, 则创建n个Excel文件写入, 每个Excel文件写入阈值条数据;
模为阈值的小数n.xx倍, 则创建n+1个Excel文件写入, 前面每个Excel文件写入阈值条数据, 最后一个Excel 文件写入余数条数据.(3) 将生成的多个Excel文件暂存到服务器临时下载目录中, 等所有数据写入完成后, 将临时下载目录的Excel文件进行压缩处理, 并返回一个
压缩文件给前端下载.(4) 临时下载目录的清理, 服务器的空间是有限的, 临时数据需要考虑到清理机制. 可以通过
定时任务调度进行删除.
2. 编写代码
我将大部分公共逻辑进行了封装, 抽象出不同场景的数据查询方法给子类重写实现.
2.1 公共方法入口
com.poi.service.ExpExcelByPagesService#exportExcel
/**
* 导出Excel文件
* @param dataMap
*/
public void exportExcel(Map<String, Object> dataMap) {
logger.info(">>>>{}, dataMap is:{}", this.getClass().getSimpleName(), dataMap);
// 统计查询的数据量
int record = 0;
// 阈值: 每个excel文件数据量, 也是db分页查询的数据量上限, 推荐 10000
int pageSize = 10000;
// 当前页码, 默认查询第一页
int currentPage = 1;
// 用户编号
String userCode = (String) dataMap.get(CSISCONSTANT.USER_CODE);
// 文件类型 .xls .xlsx
String fileType = (String) dataMap.get(CSISCONSTANT.EXCEL_FILE_TYPE);
// 文件类型非空判断,如果为空, 默认下载03版xls
fileType = !StringUtils.isEmpty(fileType) &&
Objects.equals(CSISCONSTANT.EXCEL07_EXTENSION, fileType) ? fileType :
CSISCONSTANT.EXCEL03_EXTENSION;
logger.info("export excel fileType is:{}", fileType);
// /home/wasadmin/exportData/yyyyMMdd/yyyyMMddHHmmss+userCode/
String writeDir = String.format(EXPORT_PARENT_PATH + DateUtil.format(
new Date(), CSISCONSTANT.FORMAT_YYYYMMDD) + File.separator +
DateUtil.format(new Date(), CSISCONSTANT.FORMATYYYYMMDDHHMMSS)) +
userCode + File.separator;
// 目录不存在, 则创建
File writeDirFile = new File(writeDir);
if (!writeDirFile.exists()) {
writeDirFile.mkdirs();
}
// 标题行(表头) key-value
LinkedHashMap<String, Object> titleMap = getTitleMap();
// 获取查询的全量数据 实际应用场景中应该只需要查询总条数, 不需要所有字段都查询出来
//具体的数据应该在后面的分页查询中获取(db查询)
// 因为我这里是demo,所以暂时用集合模拟全量数据查询了
List<HashMap<String, Object>> dataList = getDataList();
// 当前查询的数据总条数
record = dataList.size();
// 如果大于设置的每个excel文件数据量, 则将数据切割写入多个excel文件
if (record > pageSize) {
loopCreateExcel(dataMap, record, pageSize, fileType, writeDir, titleMap,
dataList);
} else {
List<HashMap<String, Object>> pageDataList = queryDataByPages(dataMap, pageSize, currentPage, 0, dataList);
writeToExcel(fileType, writeDir, userCode, titleMap, currentPage, pageDataList);
}
// 所有文件写入到服务器后, 将它们压缩成一个zip文件给前端界面下载
String zipFileName = writeDir + "EXP" + DateUtil.format(
new Date(), CSISCONSTANT.FORMAT_YYYYMMDD) + DataHandleUtil.getRandomNumber(8) + CSISCONSTANT.ZIP_FILE_EXTENSION;
ExportDataToExcelService.writeZipExcel(writeDir, zipFileName);
// 设置 FILE_DOWN_LOAD_NAME 由拦截器将下载文件路径写入上下文的响应流中
dataMap.put(CSISCONSTANT.FILE_DOWNLOAD_NAME, new File(zipFileName));
}
2.2 获取标题行数据
不同应用场景, 导出的Excel文件标题行(表头)不一样, 需要进行个性化定制, 我将获取标题行数据的方法抽象出来, 提供了子类重写.
com.poi.service.ExpExcelByPagesService#getTitleMap
/**
* 储存标题行(表头)数据 , 可以抽象, 在子类实现
* @return
*/
public abstract LinkedHashMap<String, Object> getTitleMap();
2.3 获取数据行数据
数据行的数据获取也跟上面一样, 导出的数据根据场景而定, 进行抽象.
com.poi.service.ExpExcelByPagesService#getDataList
/**
* 查询全量数据, 可以抽象, 在子类实现
* @return
*/
public abstract List<HashMap<String, Object>> getDataList();
2.4 阈值判断是否拆分数据
上面获取到了总的数据量, 可以与设置的阈值进行比较, 判断是否需要进行数据拆分.
// 当前查询的数据总条数
record = dataList.size();
// 如果大于设置的每个excel文件数据量, 则将数据切割写入多个excel文件
if (record > pageSize) {
loopCreateExcel(dataMap, record, pageSize, fileType, writeDir, titleMap, dataList);
} else {
List<HashMap<String, Object>> pageDataList = queryDataByPages(dataMap, pageSize, currentPage, 0, dataList);
writeToExcel(fileType, writeDir, userCode, titleMap, currentPage, pageDataList);
}
2.5 数据量大于阈值-拆分
if (record > pageSize) {
loopCreateExcel(dataMap, record, pageSize, fileType, writeDir, titleMap, dataList);
}
数据拆分规则, 按照分页查询出来, 每页数据需要重新设置分页查询起始位置和结束位置, 从而获取到拆分的每页数据.
com.poi.service.ExpExcelByPagesService#loopCreateExcel
private void loopCreateExcel(Map<String, Object> dataMap, int record, int pageSize,
String fileType, String writeDir, LinkedHashMap<String,
Object> titleMap,
List<HashMap<String, Object>> contentList) {
int currentPage = 0;
// 超过设置的单个sheet表数据上限 , 分页查询并分多个excel文件写入
int loopNum = record / pageSize;
int remainder = record % pageSize;
logger.info("loopNum={}, remainder={} ", loopNum, remainder);
String userCode = (String) dataMap.get(CSISCONSTANT.USER_CODE);
for (int i = 0; i < loopNum; i++) {
currentPage = i + 1; // 一页对应一个excel文件
List<HashMap<String, Object>> pageDataList = queryDataByPages(dataMap, pageSize, currentPage, 0, contentList);
writeToExcel(fileType, writeDir, userCode, titleMap, currentPage, pageDataList);
}
if (remainder > 0) {
currentPage = loopNum + 1;
List<HashMap<String, Object>> pageDataList = queryDataByPages(dataMap, pageSize, currentPage, remainder, contentList);
writeToExcel(fileType, writeDir, userCode, titleMap, currentPage, pageDataList);
}
}
设置分页参数 com.poi.service.ExpExcelByPagesService#storePageParam
private void storePageParam(Map<String, Object> dataMap, int pageSize, int currentPage, int remainder) {
// 起始位置 db查询和集合的索引定义不一样, 要注意区分起始索引是0或1
// int startIndex = (currentPage - 1) * pageSize + 1;
int startIndex = (currentPage - 1) * pageSize;
// 结束位置
int endIndex = currentPage * pageSize;
// 如果最后一页不满pageSize条, 就是实际的余数remainder条记录
if (remainder > 0) {
endIndex = (currentPage - 1) * pageSize + remainder;
}
dataMap.put(CSISCONSTANT.START_INDEX, startIndex);
dataMap.put(CSISCONSTANT.END_INDEX, endIndex);
}
分页查询数据 com.poi.service.ExpExcelByPagesService#queryDataByPages
private List<HashMap<String, Object>> queryDataByPages(Map<String, Object> dataMap,
int pageSize, int currentPage,
int remainder, List<HashMap<String, Object>> contentList) {
// 设置分页查询参数
storePageParam(dataMap, pageSize, currentPage, remainder);
int startIndex = (Integer) dataMap.get(CSISCONSTANT.START_INDEX);
int endIndex = (Integer) dataMap.get(CSISCONSTANT.END_INDEX);
// 分页查询数据, 实际场景是db分页查询
//而且也应该抽取到抽象方法中, 在子类中实现(因为不同场景查询的数据不一样)
List<HashMap<String, Object>> pageDataList = contentList.subList(startIndex,
endIndex);
// 删除集合中的空行
List<HashMap<String, Object>> newDataList =
pageDataList.stream().filter(Objects::nonNull).collect(Collectors.toList());
return newDataList;
}
2.6 数据写入Excel
不管数据量是在设置阈值以内, 还是大于阈值, 数据准备完成后, 就是将数据写入Excel文件中了.
List<HashMap<String, Object>> pageDataList = queryDataByPages(dataMap, pageSize, currentPage, 0, dataList);
writeToExcel(fileType, writeDir, userCode, titleMap, currentPage, pageDataList);
数据行和标题行数据转换的公共方法 com.poi.service.ExpExcelByPagesService#writeToExcel
private String writeToExcel(String fileType, String writeDir, String userCode,
LinkedHashMap<String, Object> titleMap,
int currentPage,
List<HashMap<String, Object>> pageDataList) {
if (CollectionUtils.isEmpty(titleMap)) {
throw new RuntimeException("标题行数据不能为空");
}
// 封装标题行
List<String> titleList = ExportDataToExcelService.getTitleList(titleMap);
// 封装数据行
List<List<String>> detailList =
ExportDataToExcelService.getDetailList(pageDataList, titleMap);
// 获取Excel文件写入的绝对路径 /home/wasadmin/exportData/20210927/202109271010103102435/EXP20210927_3102435_1.xls
String writeFileName = writeDir + "EXP" + DateUtil.format(
new Date(), CSISCONSTANT.FORMAT_YYYYMMDD) + "_" + userCode + "_" +
currentPage + fileType;
logger.info("export excel writeFileName is : {}", writeFileName);
// 生成Excel文件并写入数据
ExportDataToExcelService.writeExcel(fileType, writeFileName, titleList,
detailList);
return writeFileName;
}
写入Excel的公共方法 com.poi.service.ExportDataToExcelService#writeExcel
public static void writeExcel(String fileType, String writeFileName,
List<String> titleList,
List<List<String>> detailList) {
FileOutputStream out = null;
try {
out = new FileOutputStream(writeFileName);
toWritePerExcelByOneSheet(out, titleList, detailList, fileType);
} catch (IOException e) {
e.printStackTrace();
} finally {
if (out != null) {
try {
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
toWritePerExcelByOneSheet
private static void toWritePerExcelByOneSheet(FileOutputStream out,
List<String> titleList,
List<List<String>> contentList,
String fileType) throws IOException {
Workbook wb = getWorkbook(fileType); // 根据fileType获取HSSF或XSSF工作簿
Sheet sheet = wb.createSheet(); // 创建一个sheet表
createHeadRow(wb, sheet, titleList); // 创建标题行
createDataRow(wb, sheet, contentList); // 创建数据行(单元格)
wb.write(out); // 把相应的excel在工作簿存盘
out.flush(); // 刷新
if (null != out) {
out.close();
}
}
com.poi.service.ExportDataToExcelService#getWorkbook
/**
* 根据要生成的文件类型创建HSSF或者XSSF工作簿
* @param fileType .xls .xlsx
* @return
*/
public static Workbook getWorkbook(String fileType) {
Workbook wb = null;
switch (fileType) {
case CSISCONSTANT.EXCEL03_EXTENSION:
wb = new HSSFWorkbook(); // 创建工作簿 2003版excel
break;
case CSISCONSTANT.EXCEL07_EXTENSION:
default:
wb = new XSSFWorkbook(); // 创建工作簿 2007版excel
break;
}
return wb;
}
createHeadRow, createDataRow 在博客Poi实现Excel导出已经给出过代码实现, 这里就不重复了.
2.7 文件压缩下载
所有拆分的数据写入Excel文件后, 将服务器临时下载目录的Excel文件压缩成一个zip文件后, 返回给前端下载.
// 所有文件写入到服务器后, 将它们压缩成一个zip文件给前端界面下载
String zipFileName = writeDir + "EXP" + DateUtil.format(
new Date(), CSISCONSTANT.FORMAT_YYYYMMDD) + DataHandleUtil.getRandomNumber(8) + CSISCONSTANT.ZIP_FILE_EXTENSION;
ExportDataToExcelService.writeZipExcel(writeDir, zipFileName);
// 设置 FILE_DOWN_LOAD_NAME 由拦截器将下载文件路径写入上下文的响应流中
dataMap.put(CSISCONSTANT.FILE_DOWNLOAD_NAME, new File(zipFileName));
ExportDataToExcelService#writeZipExcel在博客Poi实现Excel导出已经给出过代码实现, 这里就不重复了.
2.8 子类实现
因为标题行和数据行的数据在不同场景下是不一样的, 所以对这两部的数据获取进行抽象处理, 需要在子类中重写.
子类 com.poi.service.impl.ExpExcelByPageImpl
/**
* 类描述:分流导出数据到Excel
* @Author wang_qz
* @Date 2021/9/27 20:04
* @Version 1.0
* 调用{@link ExpExcelByPagesService#exportExcel} 方法分流写入Excel
* 需要重写{@link ExpExcelByPagesService#getTitleMap()} 和
* {@link ExpExcelByPagesService#getDataList()} 方法
*/
public class ExpExcelByPageImpl extends ExpExcelByPagesService {
@Override
public LinkedHashMap<String, Object> getTitleMap() {
LinkedHashMap<String, Object> titleMap = new LinkedHashMap<>();
titleMap.put("id", "序号");
titleMap.put("name", "姓名");
titleMap.put("age", "年龄");
titleMap.put("gender", "性别");
return titleMap;
}
/**
* 查询全量数据, 实际场景中可能是查询db
* @return
*/
@Override
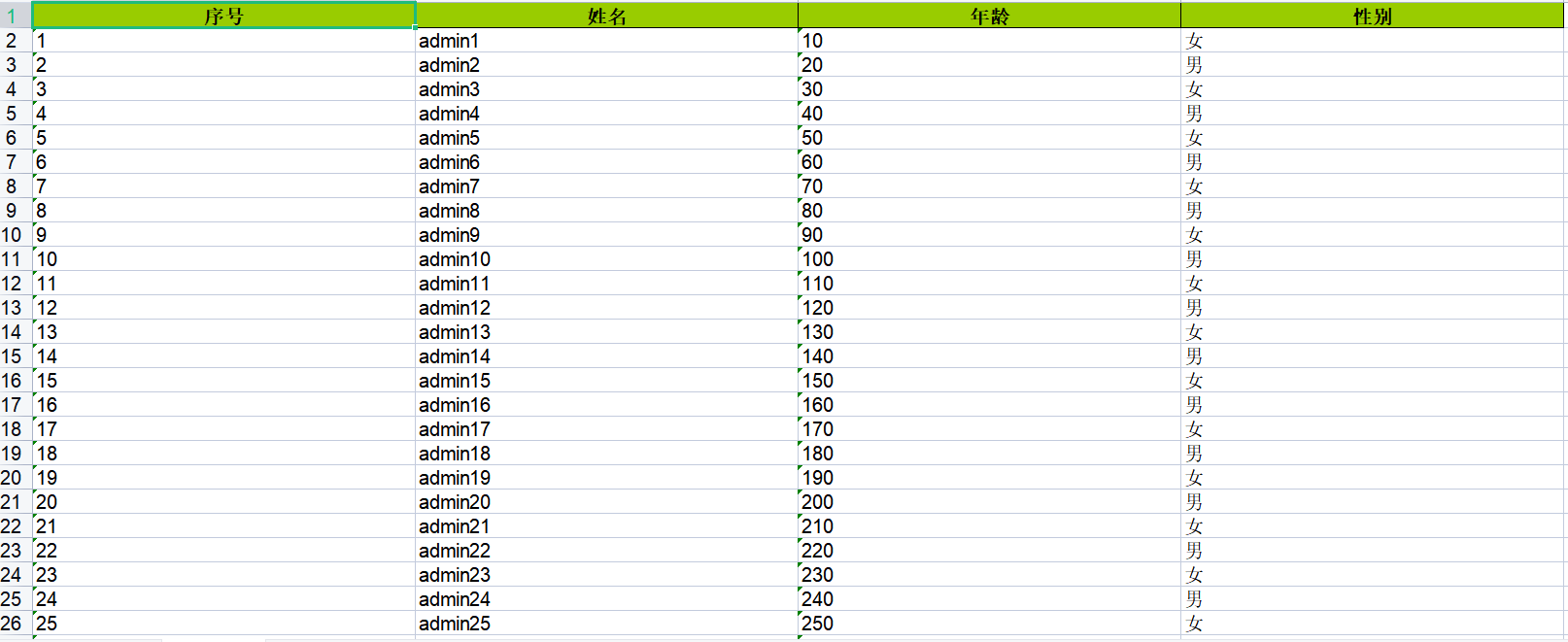
public List<HashMap<String, Object>> getDataList() {
List<HashMap<String, Object>> dataList = new ArrayList<>();
for (int i = 1; i <= 50000; i++) {
HashMap<String, Object> data = new HashMap<>();
data.put("id", i);
data.put("name", "admin" + i);
data.put("age", 10 * i);
data.put("gender", i % 2 == 0 ? "男" : "女");
dataList.add(data);
}
return dataList;
}
}
3. 单元测试
3.1 测试代码
com.test.poi.PoiExcelTest#testExpExcelByPagesService
@Test
public void testExpExcelByPagesService() {
Map<String, Object> dataMap = new HashMap<>();
dataMap.put(CSISCONSTANT.USER_CODE, "3102435");
// dataMap.put(CSISCONSTANT.EXCEL_FILE_TYPE, CSISCONSTANT.EXCEL07_EXTENSION);
dataMap.put(CSISCONSTANT.EXCEL_FILE_TYPE, CSISCONSTANT.EXCEL03_EXTENSION);
ExpExcelByPagesService service = new ExpExcelByPageImpl();
service.exportExcel(dataMap);
}
3.2 测试结果
我在上面的子类中模拟的是5万条数据, 阈值设置的是1万, 所以会生成5个Excel文件并压缩.
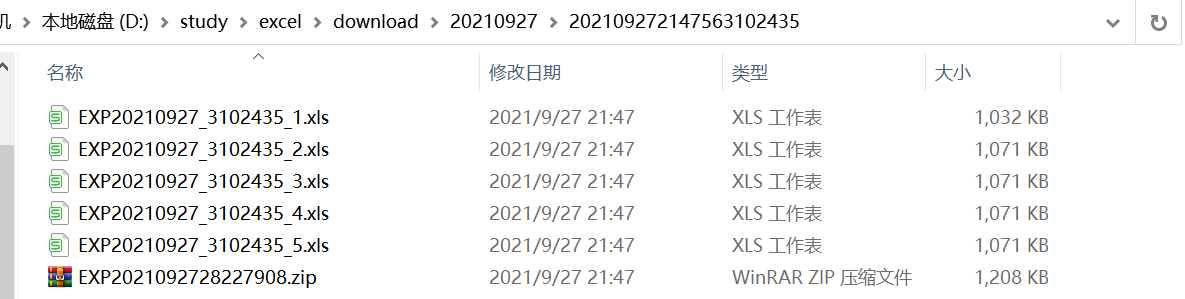
打开压缩包
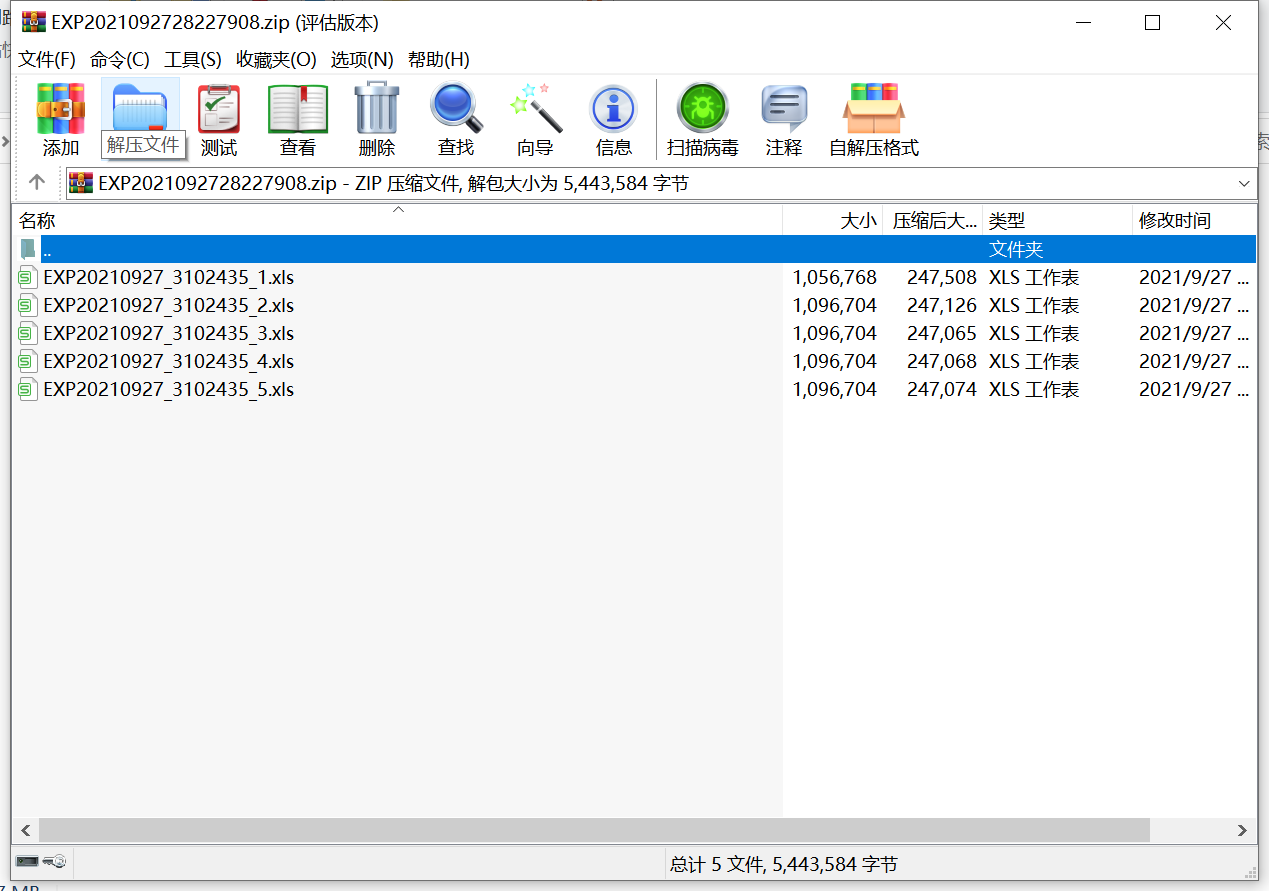
打开Excel文件, 查看写入的数据
4. Web端测试
4.1 编写Controller
com.poi.controller.ExcelController#downloadExcel3
/**
* 经过服务器临时下载目录中转的实现-数据分流写入多个Excel且压缩后下载
* @param response
* @throws MyException
* @throws IOException
*/
@RequestMapping("/downloadExcel3")
public void downloadExcel3(HttpServletResponse response) throws MyException, IOException {
// 设置响应头
response.setContentType("application/vnd.ms-excel");
response.setCharacterEncoding("utf-8");
// 设置防止中文名乱码
String filename = URLEncoder.encode("用户信息", "utf-8");
// 文件下载方式(附件下载还是在当前浏览器打开) xxx.zip文件
response.setHeader("Content-disposition", "attachment;filename=" + filename +
CSISCONSTANT.ZIP_FILE_EXTENSION);
Map<String, Object> dataMap = new HashMap<>();
dataMap.put(CSISCONSTANT.USER_CODE, "3102435");
dataMap.put(CSISCONSTANT.EXCEL_FILE_TYPE, CSISCONSTANT.EXCEL03_EXTENSION);
ExpExcelByPagesService service = new ExpExcelByPageImpl();
service.exportExcel(dataMap);
// 数据分流写入多个Excel且压缩后下载
File downloadFile = (File) dataMap.get(CSISCONSTANT.FILE_DOWNLOAD_NAME);
// 因为将文件存在了服务器的临时下载目录,所以需要读取服务器上的文件写入响应流中
FileInputStream read = new FileInputStream(downloadFile);
ServletOutputStream out = response.getOutputStream();
byte[] bys = new byte[1024];
while (read.read(bys) != -1) {
out.write(bys, 0, bys.length);
out.flush();
}
out.close();
}
4.2 测试结果
启动tomcat应用, 在浏览器访问 http://localhost:8080/excel/downloadExcel3, 查看下载效果:
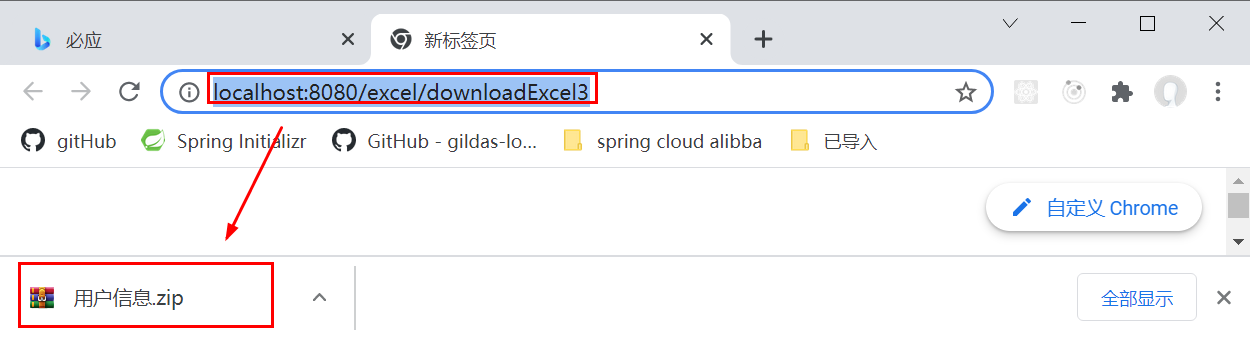
打开压缩包, 也是生成的5个Excel文件
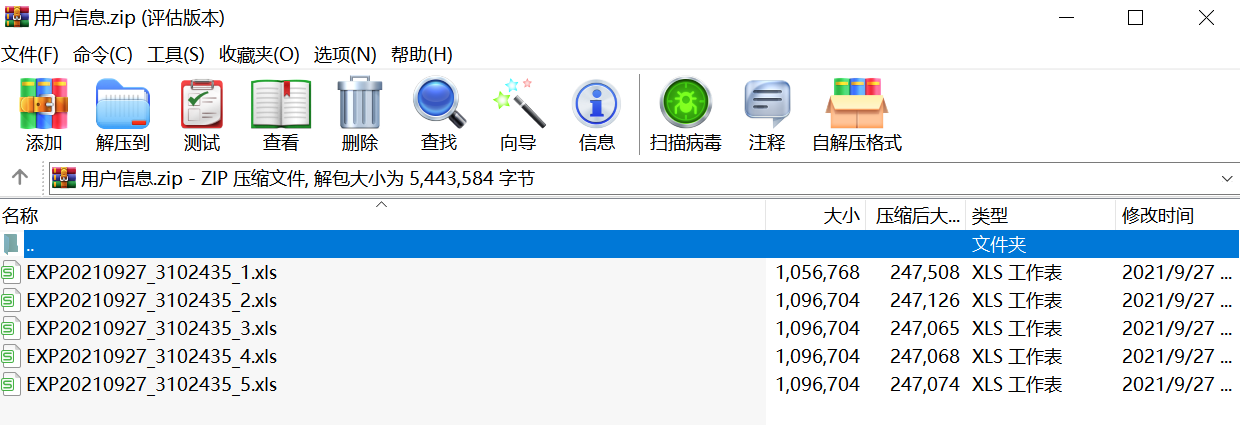
5. 临时下载目录清理
临时下载目录的清理, 服务器的空间是有限的, 临时数据需要考虑到清理机制. 可以通过定时任务调度进行删除 . 我使用的是Quartz框架, 当然也有很多其他方式实现定时任务调度, 比如:
(1) SpringBoot注解@EnableScheduling + @Scheduled
(2) java.util.Timer + java.util.TimerTask
(3) ScheduledExecutorService
(4) Quartz
(5) Spring Task
(6) 分布式任务调度实现: 推荐许雪里老师的
xxl-job
5.1 清理任务实现
添加依赖
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz</artifactId>
<version>2.3.1</version>
</dependency>
<dependency>
<groupId>org.quartz-scheduler</groupId>
<artifactId>quartz-jobs</artifactId>
<version>2.3.1</version>
</dependency>
如果是SpringBoot,就不用上面的依赖,直接引入starter,会自动导入上面的依赖
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-quartz</artifactId>
<version>2.3.1.RELEASE</version>
</dependency>
代码实现 com.timer.ClearExcelDownloadTimer
package com.timer;
import cn.hutool.core.date.DateUtil;
import com.constant.CSISCONSTANT;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.File;
import java.util.Calendar;
import java.util.Date;
/**
* 删除服务器上excel文件临时下载目录(一个小时之前的导出目录)
* 每个小时调度一次
*/
public class ClearExcelDownloadTimer {
private static final Logger logger =
LoggerFactory.getLogger(ClearExcelDownloadTimer.class);
private static final String EXPORT_PARENT_PATH = CSISCONSTANT.TEMP_DOWNLOAD_DIR;
public void task() {
logger.info(">>>{} start", this.getClass().getSimpleName());
String today = DateUtil.format(new Date(), CSISCONSTANT.FORMAT_YYYYMMDD);
// 获取excel导出的服务器目录 /home/wasadmin/exportData
String exportParentDir = EXPORT_PARENT_PATH;
String exportTodayDir = exportParentDir + File.separator + today +
File.separator;
File exportTodayDirFile = new File(exportTodayDir);
if (!exportTodayDirFile.exists()) {
logger.info("execel temporary download directory {} not exist !",
exportTodayDirFile.getAbsolutePath());
return;
}
// 获取当天导出目录下的所有子目录, 将需要删除的子目录筛选出来
// FilenameFilter, 下面使用了jdk8语法
File[] files = exportTodayDirFile.listFiles((File dir, String name) -> {
boolean flag = false;
// name >>> 202109271010103102435 yyyyMMddHHmmss+userCode
File file = new File(dir.getAbsolutePath() + File.separator + name);
if (file.isDirectory()) {
// yyyyMMddHHmmss userCode长度7
Date subDirDateTime = DateUtil.parse(name.substring(
0, name.length() - 7), CSISCONSTANT.FORMATYYYYMMDDHHMMSS);
Calendar calendar = Calendar.getInstance();
calendar.setTime(new Date());
// calendar.add(Calendar.HOUR_OF_DAY, -1); // 当前时间-1h
calendar.add(Calendar.MINUTE, -2); // 测试用 2分钟之前的临时下载文件全部删除
Date substrDate = calendar.getTime();
flag = substrDate.compareTo(subDirDateTime) > 0;
}
return flag;
});
if (files != null && files.length > 0) {
for (File file : files) {
// 删除目录 yyyyMMddHHmmss+userCode 下面的excel或zip文件
deleteFile(file);
}
} else {
logger.info("there's no match condition temporary download directory
to remove in {} !", exportTodayDirFile.getAbsolutePath());
}
// 20
String delTodayTime = "20";
// 判断当前时间, 如果到了晚上20点, 就将excel文件下载的日期目录删除
if (new Date().compareTo(
DateUtil.parse(today + delTodayTime.trim(), "yyyyMMddHH")) >= 0 &&
exportTodayDirFile.delete()) {
logger.info("remove excel temporary download directory {}
successfully !", exportTodayDirFile.getAbsolutePath());
}
}
// 递归删除文件
private void deleteFile(File destFile) {
if (destFile.isFile()) {
boolean isDel = destFile.delete();
if (isDel) {
logger.info("remove temporary excel {} successfully !",
destFile.getAbsolutePath());
}
} else {
// destFile是目录, 循环删除, 因为含有文件的目录无法删除成功
File[] files = destFile.listFiles();
for (File file : files) {
// 递归调用
deleteFile(file);
}
// 删除完目录里面的文件后, 再删除当前空目录
boolean del = destFile.delete();
if (del) {
logger.info("remove excel temporary download directory {}
successfully !", destFile.getAbsolutePath());
}
}
}
}
5.2 定时任务调度配置
classapth下面新增spring-timer.xml文件
<?xml version="1.0" encoding="UTF-8"?>
<beans xmlns="http://www.springframework.org/schema/beans"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://www.springframework.org/schema/beans
http://www.springframework.org/schema/beans/spring-beans.xsd">
<!--实例化定时执行的任务类-->
<bean id="myJob" class="com.timer.ClearExcelDownloadTimer"/>
<!--配置触发任务 myJobDetail-->
<bean id="myJobDetail" class=
"org.springframework.scheduling.quartz.MethodInvokingJobDetailFactoryBean">
<property name="targetObject" ref="myJob"/>
<property name="targetMethod" value="task"/>
</bean>
<!--配置触发器myTrigger-->
<bean id="myTrigger" class=
"org.springframework.scheduling.quartz.CronTriggerFactoryBean">
<property name="jobDetail" ref="myJobDetail"/>
<property name="cronExpression" value="0/5 * * * * ?"/>
</bean>
<!--配置调度器scheduler-->
<bean id="myScheduler" class=
"org.springframework.scheduling.quartz.SchedulerFactoryBean">
<property name="triggers">
<list>
<ref bean="myTrigger"/>
</list>
</property>
</bean>
</beans>
5.3 初始化加载定时任务调度配置
webapp/WEB-INF/web.xml文件中配置如下:
<!--配置加载spring ioc容器的文件路径,多个配置文件可以使用逗号隔开(也可以使用模糊匹配)-->
<context-param>
<param-name>contextConfigLocation</param-name>
<param-value>classpath:applicationContext.xml, classpath:spring-timer.xml</param-value>
</context-param>
6. 数据拆分完整代码
com.poi.service.ExpExcelByPagesService
package com.poi.service;
import cn.hutool.core.date.DateUtil;
import com.constant.CSISCONSTANT;
import com.util.DataHandleUtil;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import org.springframework.util.CollectionUtils;
import org.springframework.util.StringUtils;
import java.io.File;
import java.util.*;
import java.util.stream.Collectors;
/**
* 分流写入Excel文件 , 大部分公共逻辑已经封装好, 不同应用场景的数据查询部分需要在具体子类中
* 重写下面两个方法
* {@link ExpExcelByPagesService#getTitleMap()} 和
* {@link ExpExcelByPagesService#getDataList()}
* @see ExpExcelByPagesService#exportExcel
*/
public abstract class ExpExcelByPagesService {
private static final Logger logger =
LoggerFactory.getLogger(ExpExcelByPagesService.class);
private static final String EXPORT_PARENT_PATH = CSISCONSTANT.TEMP_DOWNLOAD_DIR;
/**
* 导出Excel文件
* @param dataMap
*/
public void exportExcel(Map<String, Object> dataMap) {
logger.info(">>>>{}, dataMap is:{}", this.getClass().getSimpleName(),
dataMap);
// 统计查询的数据量
int record = 0;
// 每个excel文件数据量, 也是db分页查询的数据量上限, 推荐 10000
int pageSize = 10000;
// 当前页码, 默认查询第一页
int currentPage = 1;
// 用户编号
String userCode = (String) dataMap.get(CSISCONSTANT.USER_CODE);
// 文件类型 .xls .xlsx
String fileType = (String) dataMap.get(CSISCONSTANT.EXCEL_FILE_TYPE);
// 文件类型非空判断,如果为空, 默认下载03版xls
fileType = !StringUtils.isEmpty(fileType) &&
Objects.equals(CSISCONSTANT.EXCEL07_EXTENSION, fileType) ? fileType :
CSISCONSTANT.EXCEL03_EXTENSION;
logger.info("export excel fileType is:{}", fileType);
// /home/wasadmin/exportData/yyyyMMdd/yyyyMMddHHmmss+userCode/
String writeDir = String.format(
EXPORT_PARENT_PATH + DateUtil.format(
new Date(), CSISCONSTANT.FORMAT_YYYYMMDD) + File.separator +
DateUtil.format(new Date(), CSISCONSTANT.FORMATYYYYMMDDHHMMSS)) +
userCode + File.separator;
// 目录不存在, 则创建
File writeDirFile = new File(writeDir);
if (!writeDirFile.exists()) {
writeDirFile.mkdirs();
}
// 标题行(表头) key-value
LinkedHashMap<String, Object> titleMap = getTitleMap();
// 获取查询的全量数据 实际应用场景中应该只需要查询总条数, 不需要所有字段都查询出来
//具体的数据应该在后面的分页查询中获取(db查询)
// 因为我这里是demo,所以暂时用集合模拟全量数据查询了
List<HashMap<String, Object>> dataList = getDataList();
// 当前查询的数据总条数
record = dataList.size();
// 如果大于设置的每个excel文件数据量, 则将数据切割写入多个excel文件
if (record > pageSize) {
loopCreateExcel(dataMap, record, pageSize, fileType, writeDir, titleMap,
dataList);
} else {
List<HashMap<String, Object>> pageDataList = queryDataByPages(dataMap, pageSize, currentPage, 0, dataList);
writeToExcel(fileType, writeDir, userCode, titleMap, currentPage,
pageDataList);
}
// 所有文件写入到服务器后, 将它们压缩成一个zip文件给前端界面下载
String zipFileName = writeDir + "EXP" + DateUtil.format(
new Date(), CSISCONSTANT.FORMAT_YYYYMMDD) +
DataHandleUtil.getRandomNumber(8) + CSISCONSTANT.ZIP_FILE_EXTENSION;
ExportDataToExcelService.writeZipExcel(writeDir, zipFileName);
// 设置 FILE_DOWN_LOAD_NAME 由拦截器将下载文件路径写入上下文的响应流中
dataMap.put(CSISCONSTANT.FILE_DOWNLOAD_NAME, new File(zipFileName));
}
/**
* 生成excel, 并写入数据
* @param fileType
* @param writeDir
* @param userCode 3102435
* @param titleMap
* @param currentPage
* @param pageDataList
* @return 返回写入服务器的excel文件路径
*/
private String writeToExcel(String fileType, String writeDir, String userCode,
LinkedHashMap<String, Object> titleMap,
int currentPage,
List<HashMap<String, Object>> pageDataList) {
if (CollectionUtils.isEmpty(titleMap)) {
throw new RuntimeException("标题行数据不能为空");
}
// 封装标题行
List<String> titleList = ExportDataToExcelService.getTitleList(titleMap);
// 封装数据行
List<List<String>> detailList =
ExportDataToExcelService.getDetailList(pageDataList, titleMap);
// 获取Excel文件写入的绝对路径 /home/wasadmin/exportData/20210927/202109271010103102435/EXP20210927_3102435_1.xls
String writeFileName = writeDir + "EXP" + DateUtil.format(
new Date(), CSISCONSTANT.FORMAT_YYYYMMDD) + "_" + userCode + "_" +
currentPage + fileType;
logger.info("export excel writeFileName is : {}", writeFileName);
// 生成Excel文件并写入数据
ExportDataToExcelService.writeExcel(fileType, writeFileName,
titleList, detailList);
return writeFileName;
}
/**
* 分割数据, 分多个excel文件写入数据
* @param dataMap
* @param record
* @param pageSize
* @param fileType
* @param writeDir
* @param titleMap
* @param contentList
*/
private void loopCreateExcel(Map<String, Object> dataMap, int record,
int pageSize, String fileType,
String writeDir,
LinkedHashMap<String, Object> titleMap,
List<HashMap<String, Object>> contentList) {
int currentPage = 0;
// 超过设置的单个sheet表数据上限 , 分页查询并分多个excel文件写入
int loopNum = record / pageSize;
int remainder = record % pageSize;
logger.info("loopNum={}, remainder={} ", loopNum, remainder);
String userCode = (String) dataMap.get(CSISCONSTANT.USER_CODE);
for (int i = 0; i < loopNum; i++) {
currentPage = i + 1; // 一页对应一个excel文件
List<HashMap<String, Object>> pageDataList = queryDataByPages(dataMap, pageSize, currentPage, 0, contentList);
writeToExcel(fileType, writeDir, userCode, titleMap, currentPage,
pageDataList);
}
if (remainder > 0) {
currentPage = loopNum + 1;
List<HashMap<String, Object>> pageDataList = queryDataByPages(dataMap, pageSize, currentPage, remainder, contentList);
writeToExcel(fileType, writeDir, userCode, titleMap, currentPage,
pageDataList);
}
}
/**
* 分页查询数据
* @param dataMap
* @param pageSize
* @param currentPage
* @param remainder
* @param contentList
* @return
*/
private List<HashMap<String, Object>> queryDataByPages(
Map<String, Object> dataMap,
int pageSize, int currentPage,
int remainder, List<HashMap<String, Object>> contentList) {
// 设置分页查询参数
storePageParam(dataMap, pageSize, currentPage, remainder);
int startIndex = (Integer) dataMap.get(CSISCONSTANT.START_INDEX);
int endIndex = (Integer) dataMap.get(CSISCONSTANT.END_INDEX);
// 分页查询数据, 实际场景是db分页查询, 而且也应该抽取到抽象方法中,
// 在子类中实现(因为不同场景查询的数据不一样)
List<HashMap<String, Object>> pageDataList = contentList.subList(
startIndex, endIndex);
// 删除集合中的空行
List<HashMap<String, Object>> newDataList = pageDataList.stream()
.filter(Objects::nonNull)
.collect(Collectors.toList());
return newDataList;
}
/**
* 设置分页查询的起始和结束索引参数
* @param dataMap
* @param pageSize
* @param currentPage
* @param remainder
*/
private void storePageParam(Map<String, Object> dataMap, int pageSize,
int currentPage, int remainder) {
// 起始位置 db查询和集合的索引定义不一样, 要注意区分起始索引是0或1
// int startIndex = (currentPage - 1) * pageSize + 1;
int startIndex = (currentPage - 1) * pageSize;
// 结束位置
int endIndex = currentPage * pageSize;
// 如果最后一页不满pageSize条, 就是实际的余数remainder条记录
if (remainder > 0) {
endIndex = (currentPage - 1) * pageSize + remainder;
}
dataMap.put(CSISCONSTANT.START_INDEX, startIndex);
dataMap.put(CSISCONSTANT.END_INDEX, endIndex);
}
/**
* 储存标题行(表头)数据 , 可以抽象, 在子类实现
* @return
*/
public abstract LinkedHashMap<String, Object> getTitleMap();
/**
* 查询全量数据, 可以抽象, 在子类实现
* @return
*/
public abstract List<HashMap<String, Object>> getDataList();
}
相关推荐
Poi版本升级优化
StringTemplate实现Excel导出
Poi模板技术
SAX方式实现Excel导入
DOM方式实现Excel导入
Poi实现Excel导出
EasyExcel实现Excel文件导入导出
EasyPoi实现excel文件导入导出
个人博客
欢迎各位访问我的个人博客: https://www.crystalblog.xyz/
备用地址: https://wang-qz.gitee.io/crystal-blog/
最后
以上就是诚心豌豆最近收集整理的关于数据分流写入Excel数据拆分写入Excel并压缩相关推荐个人博客的全部内容,更多相关数据分流写入Excel数据拆分写入Excel并压缩相关推荐个人博客内容请搜索靠谱客的其他文章。








发表评论 取消回复