配置hive支持动态分区
<property>
<name>hive.exec.dynamic.partition</name>
<value>true</value>
<description>Whether or not to allow dynamic partitions in DML/DDL.</description>
</property>
<property>
<name>hive.exec.max.dynamic.partitions</name>
<value>10000</value>
<description>Maximum number of dynamic partitions allowed to be created in total.</description>
</property>
<property>
<name>hive.exec.max.dynamic.partitions.pernode</name>
<value>10000</value>
<description>Maximum number of dynamic partitions allowed to be created in each mapper/reducer node.</description>
</property>
<property>
<name>hive.exec.dynamic.partition.mode</name>
<value>nonstrict</value>
#开启允许所有分区都是动态的,否则必须要有静态分区才能使用。
<description>
In strict mode, the user must specify at least one static partition
in case the user accidentally overwrites all partitions.
In nonstrict mode all partitions are allowed to be dynamic.
</description>
</property>
ddl语句创建分区表
CREATE TABLE IF NOT EXISTS `test_p` (
`id` int COMMENT 'date in file',
`name` string COMMENT 'appname' )
COMMENT 'cleared log of origin log'
PARTITIONED BY (
`ct` string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS ORC
TBLPROPERTIES ('creator'='c-chenjc', 'crate_time'='2018-06-07')
;
CREATE TABLE IF NOT EXISTS `my_test_p` (
`id` int COMMENT 'date in file',
`name` string COMMENT 'appname' ,
`ct` string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY ','
STORED AS ORC
TBLPROPERTIES ('creator'='c-chenjc', 'crate_time'='2018-06-07')
;
准备数据
指定表中行数据信息
ROW FORMAT DELIMITED FIELDS TERMINATED BY ‘t’ LINES TERMINATED BY ‘n’
- ROW FORMAT
- TERMINATED BY ‘t’ 每行数据中字段的分隔符
- LINES TERMINATED BY ‘n’ 行的分隔符,不指定的时候默认为‘n’
所以测试数据格式
123,me1,hangzhou
245,peter,beijing
789,alice,shanghai
201,mark,guangzhou
222,mawww,guangzhou
2222,aliuc,beijing
loadl示例
load data local inpath '/app/bigdata/apache-hive-2.3.7-bin/data/testdatact' into table my_test_p;
(partition(dt='20200717'))有静态分区就要加这个
查看结果
hive> select * from my_test_P;
OK
123 me1 hangzhou
245 peter beijing
789 alice shanghai
201 mark guangzhou
222 mawww guangzhou
2222 aliuc beijing
Time taken: 1.837 seconds, Fetched: 6 row(s)
hive>
Insert示例
insert overwrite table test_p partition(ct) select id ,name,ct from my_test_p;
要点:因为dpartition表中只有两个字段,所以当我们查询了三个字段时(多了city字段),所以系统默认以最后一个字段city为分区名,因为分区表的
分区字段默认也是该表中的字段,且依次排在表中字段的最后面。所以分区需要分区的字段只能放在后面,不能把顺序弄错。如果我们查询了四个字段的话,则会报错,因为该表加上分区字段也才三个。要注意系统是根据查询字段的位置推断分区名的,而不是字段名称。
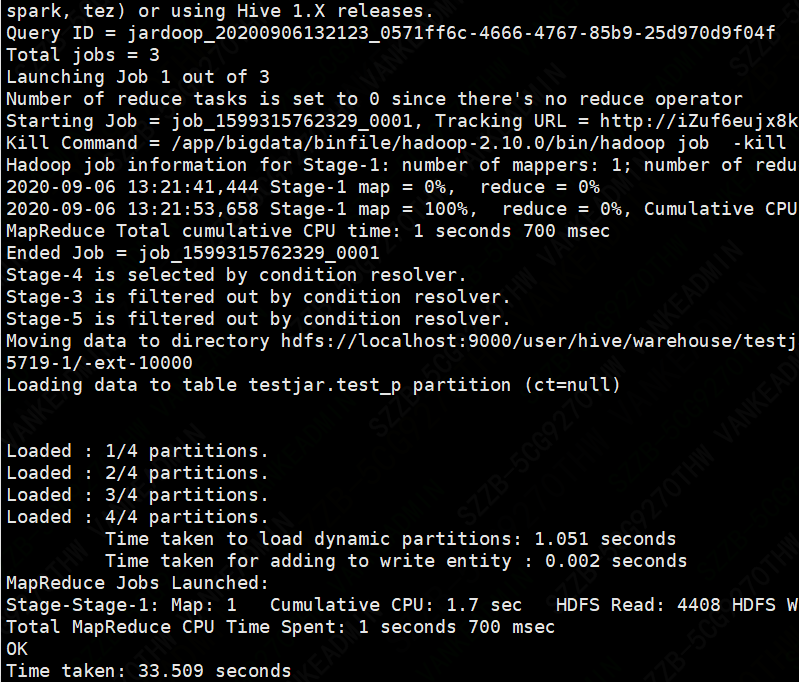
查看分区
show partitions test_table;
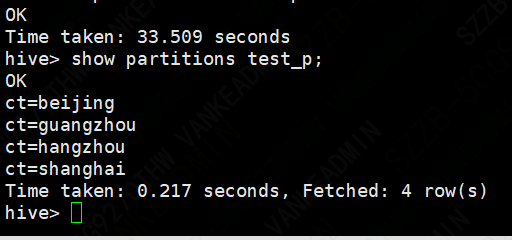
分区用法
分区字段 其实就是一个虚拟字段
select * from table_name where ct='xxx' ;
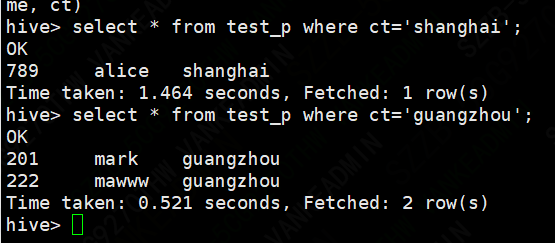
文件定时导入分区
datax模板配置
此方式会失败
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["*"],
"password": "xxx",
"username": "xxxx",
"where": "",
"connection": [{
"jdbcUrl": ["jdbc:mysql://xxxxx:3306/web_magic"],
"table": ["mysql_test_p"]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
},
{
"name": "ct",
"type": "string"
}
],
"compress": "",
"defaultFS": "hdfs://master:9000",
"fieldDelimiter": ",",
"fileName": "test_p",
"fileType": "text",
"path": "/user/hive/warehouse/testjar.db/test_p",
"writeMode": "append"
}
}
}]
单分区模版
必须确定分区
{
"job": {
"setting": {
"speed": {
"channel": 1
}
},
"content": [{
"reader": {
"name": "mysqlreader",
"parameter": {
"column": ["id","name"],
"password": "xxxxx$xx",
"username": "xxxx",
"where": "",
"connection": [{
"jdbcUrl": ["jdbc:mysql://x x xx:3306/web_magic"],
"table": ["mysql_test_p"]
}]
}
},
"writer": {
"name": "hdfswriter",
"parameter": {
"column": [{
"name": "id",
"type": "int"
},
{
"name": "name",
"type": "string"
}
],
"compress": "",
"defaultFS": "hdfs://xxxxx:xxx",
"fieldDelimiter": ",",
"fileName": "test_p",
"fileType": "text",
"path": "/user/hive/warehouse/testjar.db/test_p/ct=shanghai",
"writeMode": "append"
}
}
}]
}
}
python ../bin/datax.py --jvm="-Xms128M -Xmx128M" ./mysql2hive2.json
## --jvm是这是最大最小使用内存
对于hdfswriter功能限制
功能与限制
(1)、目前HdfsWriter仅支持textfile和orcfile两种格式的文件,且文件内容存放的必须是一张逻辑意义上的二维表;
(2)、由于HDFS是文件系统,不存在schema的概念,因此不支持对部分列写入;
(3)、目前仅支持与以下Hive数据类型: 数值型:TINYINT,SMALLINT,INT,BIGINT,FLOAT,DOUBLE 字符串类型:STRING,VARCHAR,CHAR 布尔类型:BOOLEAN 时间类型:DATE,TIMESTAMP 目前不支持:decimal、binary、arrays、maps、structs、union类型;
(4)、对于Hive分区表目前仅支持一次写入单个分区;
(5)、对于textfile需用户保证写入hdfs文件的分隔符与在Hive上创建表时的分隔符一致,从而实现写入hdfs数据与Hive表字段关联;
(6)、HdfsWriter实现过程是:首先根据用户指定的path,创建一个hdfs文件系统上不存在的临时目录,创建规则:path_随机;然后将读取的文件写入这个临时目录;全部写入后再将这个临时目录下的文件移动到用户指定目录(在创建文件时保证文件名不重复); 最后删除临时目录。如果在中间过程发生网络中断等情况造成无法与hdfs建立连接,需要用户手动删除已经写入的文件和临时目录。
(7)、目前插件中Hive版本为1.1.1,Hadoop版本为2.7.1(Apache[为适配JDK1.7],在Hadoop 2.5.0, Hadoop 2.6.0 和Hive 1.2.0测试环境中写入正常;其它版本需后期进一步测试;
(8)、目前HdfsWriter支持Kerberos认证(注意:如果用户需要进行kerberos认证,那么用户使用的Hadoop集群版本需要和hdfsreader的Hadoop版本保持一致,如果高于hdfsreader的Hadoop版本,不保证kerberos认证有效)
博主公众号
求关注

最后
以上就是开朗蜜蜂最近收集整理的关于datax导入hive动态分区的全部内容,更多相关datax导入hive动态分区内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复