针对全美婴儿姓名数据进行一些分析
1880-2014年间全美婴儿姓名数据来源于kaggle,利用这个数据我们可以进行一些有趣的分析,比如分析这些年中叫西蒙的婴儿数量的变化,国家婴儿数据如下:
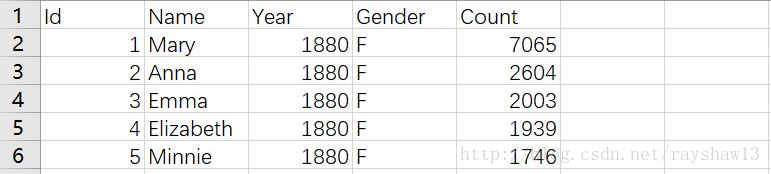
有五个特征,分别为ID、姓名、年份、性别和数量。以下为州数据state_names:
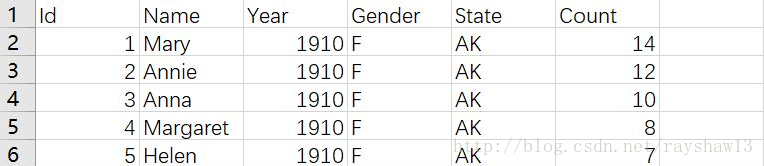
我们可以看到有六个特征,相比national来说,增加了州一项。
下面开始正式进入数据分析,我使用的是jupyter notebook(也可以使用spyder等IDE,但是注意怎样实现即时交互):
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from collections import Counter
data=pd.read_csv('./NationalNames.csv')
data.head()结果输出:
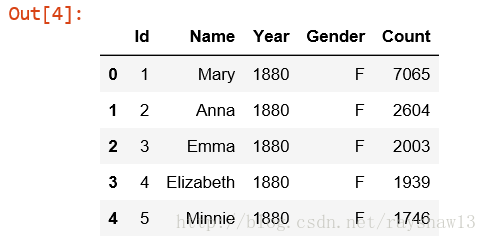
data.info()输出数据类型(这里隐藏结果显示)
将名字和数量进行统计,并放在一个字典中:
#将名字和相应的数量进行统计,存在一个字典中
names_dict=dict()
for index,row in data.iterrows():
if row['Name'] not in names_dict:
names_dict[row['Name']]=row['Count']
else:
names_dict[row['Name']]+=row['Count']
name='Mary'
print('%s->%i' %(name,names_dict.get(name)))
name='Minnie'
print('%s->%i' %(name,names_dict.get(name)))统计最流行的10个名字和最不流行的10个名字:
#利用counter计数器你的most_common函数进行统计
#返回最常用的10个名字以及相应计数
top_10=Counter(names_dict).most_common(10)
print('全美最流行的10个婴儿名字:')
for pair in top_10:
print('姓名:%s->数量:%i' %(pair[0],pair[1]))
#返回最不常用的10个名字,在这里我们直接取top_10里最后10个数就好了
print('全美最不流行的10个婴儿名字:')
for pair in Counter(names_dict).most_common()[:-10:-1]:
print('姓名:%s->数量:%i' %(pair[0],pair[1]))计算名字的平均长度:
#名字的平均长度
def average_length_data_transform():
'''
统计每年男性、女性姓名的平均长度'''
#按行遍历数据
years=[]
#女性姓名
female_average_length=[]
female_average_name_length=dict()
#男性名字
male_average_length=[]
male_average_name_length=dict()
for index,row in data.iterrows():
if row['Gender']=='F':#女性
curr_year=row['Year']
curr_name_length=len(row['Name'])
if curr_year not in female_average_name_length:
female_average_name_length[curr_year]=[curr_name_length,1]
else:
female_average_name_length[curr_year][0]+=curr_name_length
female_average_name_length[curr_year][1]+=1
else:#男性
curr_year=row['Year']
curr_name_length=len(row['Name'])
if curr_year not in male_average_name_length:
male_average_name_length[curr_year]=[curr_name_length,1]
else:
male_average_name_length[curr_year][0]+=curr_name_length
male_average_name_length[curr_year][1]+=1
for key,value in female_average_name_length.items():
years.append(key)
female_average_length.append(float(value[0])/value[1])
for key,value in male_average_name_length.items():
years.append(key)
male_average_length.append(float(value[0])/value[1])
return (female_average_length,female_average_name_length,male_average_length,male_average_name_length)注意上面定义的是一个函数,因此使用的时候需要调用
#处理时间较长
female_average_length,female_average_name_length,male_average_length,male_average_name_length=average_length_data_transform()
for year in range(1880,1891):
print('年份:%i,总长:%i,个数:%i' %(year,female_average_name_length.get(year)[0],female_average_name_length.get(year)[1]))
#输出平均长度
print(female_average_length[:10])可视化输出:
years=range(1880,2015)
f,ax=plt.subplots(figsize=(10,6))
ax.set_xlim([1880,2014])
plt.plot(years,female_average_length,label='Average length of female names',color='r')
plt.plot(years,male_average_length,label='Average length of male names',color='b')
ax.set_ylabel('Length of name')
ax.set_xlabel('Year')
ax.set_title('Average length of names')
legend=plt.legend(loc='best',frameon=True,borderpad=1,borderaxespad=1)
plt.show()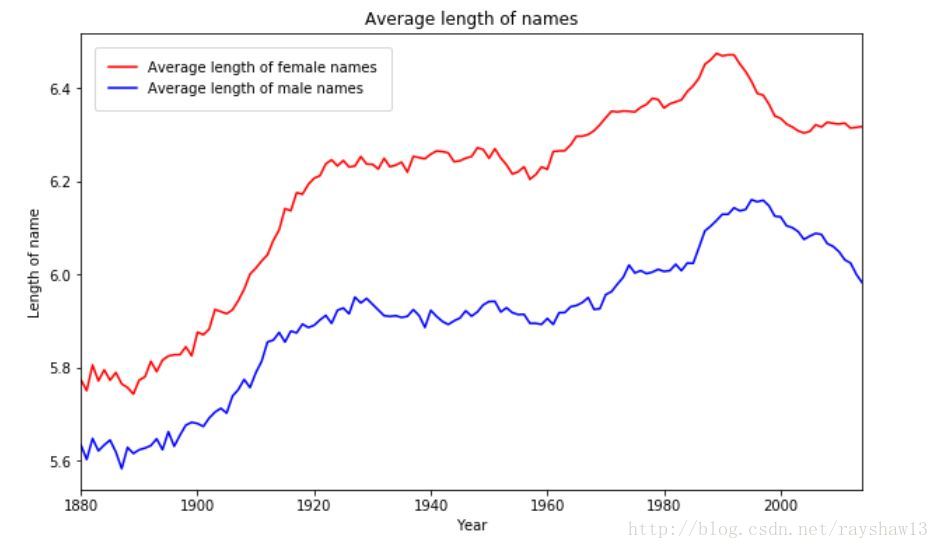
最后
以上就是呆萌花卷最近收集整理的关于1880-2014年间全美婴儿姓名分析的全部内容,更多相关1880-2014年间全美婴儿姓名分析内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复