- 论文题目:Reinforcement Learning with Deep Energy-Based Policies

所解决的问题?
作者提出一种energy-based 的强化学习算法,将其运用于连续的状态和动作空间问题中,将其称之为Soft Q-Learning。这种算法的好处就是鲁棒性和tasks之间的skills transfer。
背景
以往的方法是通过stochastic policy来增加一点exploration,例如增加噪声,或者使用一个entropy很高的policy来对其进行初始化。但是有时候我们确实会期望去学一个stochastic behaviors(鲁棒性会更强,具体参见文末扩展阅读)。
那这样的一种stochastic policy会是optimal policy吗?当我们考虑一个最优的控制和概率推断问题之间的联系的话( consider the connection between optimal control and probabilistic inference),stochastic policy可以被视为是一种最优的选择(optimal answer )。(Todorov, 2008)
- 参考:Todorov, E. General duality between optimal control and estimation. In IEEE Conf. on Decision and Control, pp. 4286–4292. IEEE, 2008.
- 参考:Toussaint, M. Robot trajectory optimization using approximate inference. In Int. Conf. on Machine Learning, pp. 1049–1056. ACM, 2009
直观理解就是,将控制问题作为一个推理的过程(framing control as inference produces policies),目的不仅仅是为了去产生一个确定性的lowest cost behavior,而是整个low-cost behavior。(Instead of learning the best way to perform the task, the resulting policies try to learn all of the ways of performing the task.)也就是我要找到这个问题所有的“最优解”。
这种方法也可以作为一个困难问题的初始化,比如用这种方法训练一个robot向前走的model,然后这个model作为下次训练robot跳跃、奔跑的初始化参数;在多模态的奖励空间中是一种更好的exploration机制(a better exploration mechanism for seeking out the best mode in a multi-modal reward landscape);由于behavior的选择变多了,所以在处理干扰的时候,鲁棒性更强。
前人也有一些stochastic policy的一些研究(参考文末资料),但是大部分都难以用于高维连续动作空间。或者是一些简单的高斯策略分布(very limited)。那能不能去找到一个任意分布的策略分布呢?
作者提出了一种energy-based model(EBM)的方法,energy function为soft Q function。
所采用的方法?
Maximum Entropy Reinforcement Learning
标准的强化学习算法的优化目标为:
π s t d ∗ = arg max π ∑ t E ( s t , a t ) ∼ ρ π [ r ( s t , a t ) ] pi_{mathrm{std}}^{*}=arg max _{pi} sum_{t} mathbb{E}_{left(mathbf{s}_{t}, mathbf{a}_{t}right) sim rho_{pi}}left[rleft(mathbf{s}_{t}, mathbf{a}_{t}right)right] πstd∗=argπmaxt∑E(st,at)∼ρπ[r(st,at)]
Maximum entropy RL算法的优化目标:
π M a x E n t ∗ = arg max π ∑ t E ( s t , a t ) ∼ ρ π [ r ( s t , a t ) + α H ( π ( ⋅ ∣ s t ) ) ] pi_{mathrm{MaxEnt}}^{*}=arg max _{pi} sum_{t} mathbb{E}_{left(mathbf{s}_{t}, mathbf{a}_{t}right) sim rho_{pi}}left[rleft(mathbf{s}_{t}, mathbf{a}_{t}right)+alpha mathcal{H}left(pileft(cdot | mathbf{s}_{t}right)right)right] πMaxEnt∗=argπmaxt∑E(st,at)∼ρπ[r(st,at)+αH(π(⋅∣st))]
其中
α
alpha
α是衡量reward和entropy之间的权重系数。与以往的Boltzman exploration和PGQ算法不一样的地方在于,maximum entropy objective会使得整个trajectory的policy分布的entropy变大。
Soft Value Functions and Energy-Based Models
传统的RL方法一般action是一个单峰的策略分布(unimodal policy distribution,下图中左图所示),而我们想要探索整个的action分布,很自然的想法就是对其取幂,就变成了一个多峰策略分布 (multimodal policy distribution)。
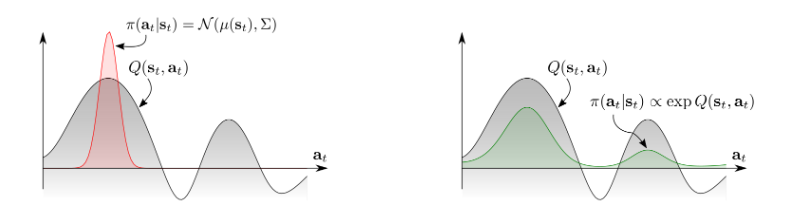
- Energy based model和soft Q function的关系:
由此作者使用了一种energy-based的policy方法,如下形式:
π ( a t ∣ s t ) ∝ exp ( − E ( s t , a t ) ) pileft(mathbf{a}_{t} | mathbf{s}_{t}right) propto exp left(-mathcal{E}left(mathbf{s}_{t}, mathbf{a}_{t}right)right) π(at∣st)∝exp(−E(st,at))
其中
E
mathcal{E}
E是energy function,可以用neural network来表示。
Theorem1. Let the soft Q-function be defined :
定义soft q function:
Q s o f t ∗ ( s t , a t ) = r t + E ( s t + 1 , … ) ∼ ρ π [ ∑ l = 1 ∞ γ l ( r t + l + α H ( π M a x E n t ∗ ( ⋅ ∣ s t + l ) ) ) ] begin{array}{l} Q_{mathrm{soft}}^{*}left(mathbf{s}_{t}, mathbf{a}_{t}right)=r_{t}+ \ mathbb{E}_{left(mathbf{s}_{t+1}, ldotsright) sim rho_{pi}}left[sum_{l=1}^{infty} gamma^{l}left(r_{t+l}+alpha mathcal{H}left(pi_{mathrm{MaxEnt}}^{*}left(cdot | mathbf{s}_{t+l}right)right)right)right] end{array} Qsoft∗(st,at)=rt+E(st+1,…)∼ρπ[∑l=1∞γl(rt+l+αH(πMaxEnt∗(⋅∣st+l)))]
和soft value function:
V s o f t ∗ ( s t ) = α log ∫ A exp ( 1 α Q s o f t ∗ ( s t , a ′ ) ) d a ′ V_{mathrm{soft}}^{*}left(mathbf{s}_{t}right)=alpha log int_{mathcal{A}} exp left(frac{1}{alpha} Q_{mathrm{soft}}^{*}left(mathbf{s}_{t}, mathbf{a}^{prime}right)right) d mathbf{a}^{prime} Vsoft∗(st)=αlog∫Aexp(α1Qsoft∗(st,a′))da′
Maximum entropy RL算法的优化目标:
π M a x E n t ∗ = arg max π ∑ t E ( s t , a t ) ∼ ρ π [ r ( s t , a t ) + α H ( π ( ⋅ ∣ s t ) ) ] pi_{mathrm{MaxEnt}}^{*}=arg max _{pi} sum_{t} mathbb{E}_{left(mathbf{s}_{t}, mathbf{a}_{t}right) sim rho_{pi}}left[rleft(mathbf{s}_{t}, mathbf{a}_{t}right)+alpha mathcal{H}left(pileft(cdot | mathbf{s}_{t}right)right)right] πMaxEnt∗=argπmaxt∑E(st,at)∼ρπ[r(st,at)+αH(π(⋅∣st))]
由此可以得到上述Maximum entropy RL算法的优化目标的 the optimal policy:
π M a x E n t ∗ ( a t ∣ s t ) = exp ( 1 α ( Q s o f t ∗ ( s t , a t ) − V s o f t ∗ ( s t ) ) ) pi_{mathrm{MaxEnt}}^{*}left(mathbf{a}_{t} | mathbf{s}_{t}right)=exp left(frac{1}{alpha}left(Q_{mathrm{soft}}^{*}left(mathbf{s}_{t}, mathbf{a}_{t}right)-V_{mathrm{soft}}^{*}left(mathbf{s}_{t}right)right)right) πMaxEnt∗(at∣st)=exp(α1(Qsoft∗(st,at)−Vsoft∗(st)))
Soft Q Learning中Policy Improvement 证明中有上述公式定义的部分解释(最优策略一定会满足这种energy-based的形式)。
Theorem1将maximum entropy objective和energy-based的方法联系在一起了。其中
1
α
Q
s
o
f
t
(
s
t
,
a
t
)
frac{1}{alpha} Q_{mathrm{soft}}left(mathbf{s}_{t}, mathbf{a}_{t}right)
α1Qsoft(st,at) acts as the negative energy。
1
α
V
s
o
f
t
(
s
t
)
frac{1}{alpha}V_{soft}(s_{t})
α1Vsoft(st) serve as the log-partition function。
Soft Q function会满足Soft Bellman Equation
Q s o f t ∗ ( s t , a t ) = r t + γ E s t + 1 ∼ p s [ V s o f t ∗ ( s t + 1 ) ] Q_{mathrm{soft}}^{*}left(mathbf{s}_{t}, mathbf{a}_{t}right)=r_{t}+gamma mathbb{E}_{mathbf{s}_{t+1} sim p_{mathbf{s}}}left[V_{mathrm{soft}}^{*}left(mathbf{s}_{t+1}right)right] Qsoft∗(st,at)=rt+γEst+1∼ps[Vsoft∗(st+1)]
到此一些基本的定义就定义完成了,之后我们需要将Q-Learning的算法用于maximum entropy policy就可以了。
Training Expressive Energy-Based Models via Soft Q-Learning
通过压缩映射能够证明:
Q s o f t ( s t , a t ) ← r t + γ E s t + 1 ∼ p s [ V s o f t ( s t + 1 ) ] , ∀ s t , a t V s o f t ( s t ) ← α log ∫ A exp ( 1 α Q s o f t ( s t , a ′ ) ) d a ′ , ∀ s t begin{aligned} Q_{mathrm{soft}}left(mathbf{s}_{t}, mathbf{a}_{t}right) & leftarrow r_{t}+gamma mathbb{E}_{mathbf{s}_{t+1} sim p_{mathrm{s}}}left[V_{mathrm{soft}}left(mathbf{s}_{t+1}right)right], forall mathbf{s}_{t}, mathbf{a}_{t} \ V_{mathrm{soft}}left(mathbf{s}_{t}right) & leftarrow alpha log int_{mathcal{A}} exp left(frac{1}{alpha} Q_{mathrm{soft}}left(mathbf{s}_{t}, mathbf{a}^{prime}right)right) d mathbf{a}^{prime}, forall mathbf{s}_{t} end{aligned} Qsoft(st,at)Vsoft(st)←rt+γEst+1∼ps[Vsoft(st+1)],∀st,at←αlog∫Aexp(α1Qsoft(st,a′))da′,∀st
会收敛到
Q
s
o
f
t
∗
Q_{soft}^{*}
Qsoft∗和
V
s
o
f
t
∗
V_{soft}^{*}
Vsoft∗。然后这里还是有几个点需要去考虑,比如如何将其用于大规模的state、action空间。从energy-based中采样会变得很棘手(intractable)。
Soft Q Learning
即使证明了soft贝尔曼方程会收敛,但是
V
s
o
f
t
∗
V_{soft}^{*}
Vsoft∗的计算过程中含有积分项,因此处理起来还是会很困难。作者用function approximator来定义
Q
s
o
f
t
θ
(
s
,
a
)
Q_{soft}^{theta}(s,a)
Qsoftθ(s,a)。
First,想要用stochastic optimization方法来对上述公式进行优化,我们首先将soft value function通过重要性采样得到其期望的形式:
V s o f t θ ( s t ) = α log E q a ′ [ exp ( 1 α Q s o f t θ ( s t , a ′ ) ) q a ′ ( a ′ ) ] V_{mathrm{soft}}^{theta}left(mathbf{s}_{t}right)=alpha log mathbb{E}_{q_{mathbf{a}^{prime}}}left[frac{exp left(frac{1}{alpha} Q_{mathrm{soft}}^{theta}left(mathbf{s}_{t}, mathbf{a}^{prime}right)right)}{q_{mathbf{a}^{prime}}left(mathbf{a}^{prime}right)}right] Vsoftθ(st)=αlogEqa′[qa′(a′)exp(α1Qsoftθ(st,a′))]
其中
q
a
′
q_{a^{prime}}
qa′可以为action space中的任意一个分布。我们可以将soft Q-Iteration 表示为最小化形式:
J Q ( θ ) = E s t ∼ q s t , a t ∼ q a t [ 1 2 ( Q ^ s o f t θ ˉ ( s t , a t ) − Q s o f t θ ( s t , a t ) ) 2 ] J_{Q}(theta)=mathbb{E}_{mathbf{s}_{t} sim q_{s_{t}}, mathbf{a}_{t} sim q_{mathbf{a}_{t}}}left[frac{1}{2}left(hat{Q}_{mathrm{soft}}^{bar{theta}}left(mathbf{s}_{t}, mathbf{a}_{t}right)-Q_{mathrm{soft}}^{theta}left(mathbf{s}_{t}, mathbf{a}_{t}right)right)^{2}right] JQ(θ)=Est∼qst,at∼qat[21(Q^softθˉ(st,at)−Qsoftθ(st,at))2]
其中
Q
^
s
o
f
t
θ
ˉ
(
s
t
,
a
t
)
=
r
t
+
γ
E
s
t
+
1
∼
p
s
[
V
s
o
f
t
θ
(
s
t
+
1
)
]
hat{Q}_{mathrm{soft}}^{bar{theta}}left(mathbf{s}_{t}, mathbf{a}_{t}right)=r_{t}+gamma mathbb{E}_{mathbf{s}_{t+1} sim p_{mathbf{s}}}left[V_{mathrm{soft}}^{theta}left(mathbf{s}_{t+1}right)right]
Q^softθˉ(st,at)=rt+γEst+1∼ps[Vsoftθ(st+1)]是target Q-Value。
Approximate Sampling and Stein Variational Gradient Descent (SVGD)
那我们如何从soft q function中采样呢?传统的从energy-based分布中采样通常会有两种策略:1. use Markov chain Monte Carlo (MCMC) based sampling;2. learn a stochastic sampling network trained to output approximate samples from the target distribution . 然而作者依据2016年Liu, Q. and Wang, D.提出的两种方法,a sampling network based on Stein variational gradient descent (SVGD) 和 amortized SVGD.做采样。
- Liu, Q. and Wang, D. Stein variational gradient descent: A general purpose bayesian inference algorithm. In Advances In Neural Information Processing Systems, pp. 2370–2378, 2016.
- Wang, D. and Liu, Q. Learning to draw samples: With application to amortized mle for generative adversarial learning. arXiv preprint arXiv:1611.01722, 2016.
这样做的好处主要有三点,提供一个stochastic sample generation;会收敛到EBM精确的后验分布;第三他可以跟actor critic算法联系起来,也就有了之后的SAC。
我们想要去学习一个state-conditioned stochastic neural network
a
t
=
f
ϕ
(
ξ
;
s
t
)
mathbf{a}_{t}=f^{phi}left(xi ; mathbf{s}_{t}right)
at=fϕ(ξ;st),
ϕ
phi
ϕ 为网络参数,
ξ
xi
ξ 为高斯或者其他任意一个分布的噪声。想要去寻找一个参数
ϕ
phi
ϕ下的动作分布
π
ϕ
(
a
t
,
s
t
)
pi^{phi}(a_{t},s_{t})
πϕ(at,st),期望这个分布能够近似energy-based的分布,KL divergence定义如下:
J π ( ϕ ; s t ) = D K L ( π ϕ ( ⋅ ∣ s t ) ∥ exp ( 1 α ( Q soft θ ( s t , ⋅ ) − V soft θ ) ) ) J_{pi}left(phi ; mathbf{s}_{t}right)= D_{K L}left(pi^{phi}left(cdot | mathbf{s}_{t}right) | exp left(frac{1}{alpha}left(Q_{text {soft }}^{theta}left(mathbf{s}_{t}, cdotright)-V_{text {soft }}^{theta}right)right)right) Jπ(ϕ;st)=DKL(πϕ(⋅∣st)∥exp(α1(Qsoft θ(st,⋅)−Vsoft θ)))
Stein variationa lgradient descent如下:
Δ f ϕ ( ⋅ ; s t ) = E a t ∼ π ϕ [ κ ( a t , f ϕ ( ⋅ ; s t ) ) ∇ a ′ ] Q s o f t θ ( s t , a ′ ) ∣ a ′ = a t + α ∇ a ′ κ ( a ′ , f ϕ ( ⋅ ; s t ) ) ∣ a ′ = a t ] begin{aligned} Delta f^{phi}left(cdot ; mathbf{s}_{t}right)= mathbb{E}_{mathbf{a}_{t}sim pi^{phi}}[kappaleft(mathbf{a}_{t}, f^{phi}left(cdot ; mathbf{s}_{t}right)right) nabla_{mathbf{a}^{prime}} ]Q_{mathrm{soft}}^{theta}left(mathbf{s}_{t}, mathbf{a}^{prime}right)|_{mathbf{a}^{prime}=mathbf{a}_{t}}\+alpha nabla_{mathbf{a}^{prime}} kappa(mathbf{a}^{prime}, f^{phi}(cdot ; mathbf{s}_{t}))|_{mathbf{a}^{prime}=mathbf{a}_{t}}] end{aligned} Δfϕ(⋅;st)=Eat∼πϕ[κ(at,fϕ(⋅;st))∇a′]Qsoftθ(st,a′)∣a′=at+α∇a′κ(a′,fϕ(⋅;st))∣a′=at]
其中 κ kappa κ表示核函数, Δ f ϕ Delta f^{phi} Δfϕ是the optimal direction of the reproducing kernel Hilbert space of κ kappa κ,使用链导法则和Stein variational gradient into policy network我们有:
∂ J π ( ϕ ; s t ) ∂ ϕ ∝ E ξ [ Δ f ϕ ( ξ ; s t ) ∂ f ϕ ( ξ ; s t ) ∂ ϕ ] frac{partial J_{pi}left(phi ; mathbf{s}_{t}right)}{partial phi} propto mathbb{E}_{xi}left[Delta f^{phi}left(xi ; mathbf{s}_{t}right) frac{partial f^{phi}left(xi ; mathbf{s}_{t}right)}{partial phi}right] ∂ϕ∂Jπ(ϕ;st)∝Eξ[Δfϕ(ξ;st)∂ϕ∂fϕ(ξ;st)]

取得的效果?
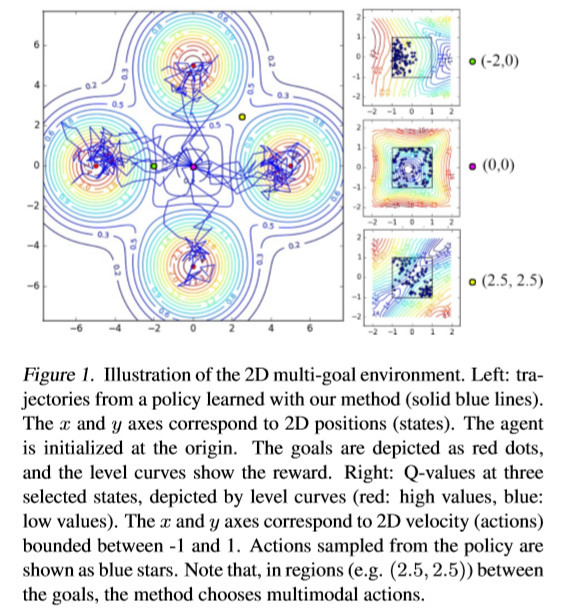
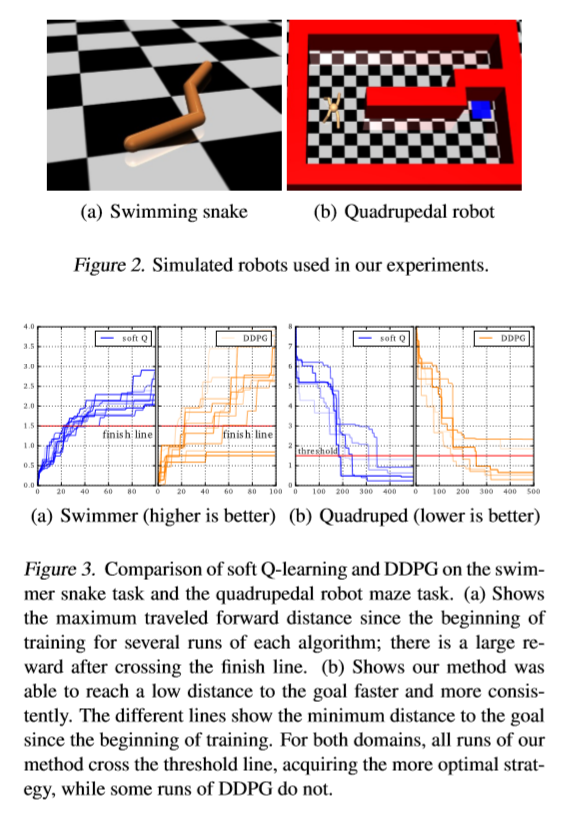
所出版信息?作者信息?
这篇文章是ICML2017上面的一篇文章。第一作者Tuomas Haarnoja是Google DeepMind的research Scientist。

参考链接
-
https://zhuanlan.zhihu.com/p/70360272
-
https://zh.wikipedia.org/wiki/%E7%8E%BB%E5%B0%94%E5%85%B9%E6%9B%BC%E5%88%86%E5%B8%83
-
https://zhuanlan.zhihu.com/p/44783057
-
https://zhuanlan.zhihu.com/p/76681229
-
https://www.dazhuanlan.com/2019/11/30/5de17e0ec54b1/
-
代码链接:https://github.com/haarnoja
扩展阅读
为什么要使用Stochastic Policy
在有些情况下我们需要去学习一个stochastic policy,为什么要去学这样一个stochastic policy呢?作者举例了两点理由:
- exploration in the presence of multimodal objectives(多模态的信息来源), and compositionality attained via pretraining. (
Daniel et al., 2012) - 增加在不确定环境下的鲁棒性(
Ziebart,2010),在模仿学习中(Ziebartetal.,2008),改善收敛性和计算性能( improved convergence and computational properties) (Gu et al., 2016a)
- 参考文献1:Daniel, C., Neumann, G., and Peters, J. Hierarchical relative entropy policy search. In AISTATS, pp. 273–281, 2012.
- 参考文献2:Ziebart,B.D. Modeling purposeful adaptive behavior with the principle of maximum causal entropy. PhD thesis, 2010.
- 参考文献3:Ziebart, B. D., Maas, A. L., Bagnell, J. A., and Dey, A. K. Maximum entropy inverse reinforcement learning. In AAAI Conference on Artificial Intelligence, pp. 1433– 1438, 2008.
- 参考文献4:Gu, S., Lillicrap, T., Ghahramani, Z., Turner, R. E., and Levine,S. Q-prop: Sample-efficientpolicygradientwith an off-policy critic. arXiv preprint arXiv:1611.02247, 2016a.
前人在 maximum entropy stochastic policy上的研究
- Z-learning (
Todorov, 2007);
Todorov, E. Linearly-solvable Markov decision problems. In Advances in Neural Information Processing Systems, pp. 1369–1376. MIT Press, 2007.
- maximum entropy inverse RL(
Ziebartetal.,2008);
Ziebart, B. D., Maas, A. L., Bagnell, J. A., and Dey, A. K. Maximum entropy inverse reinforcement learning. In AAAI Conference on Artificial Intelligence, pp. 1433– 1438, 2008.
- approximate inference using message passing (
Toussaint, 2009);
- Toussaint, M. Robot trajectory optimization using approximate inference. In Int. Conf. on Machine Learning, pp. 1049–1056. ACM, 2009.
-
Ψ
Psi
Ψ-learning (
Rawlik et al., 2012);
Rawlik, K., Toussaint, M., and Vijayakumar, S. On stochastic optimal control and reinforcement learning by approximate inference. Proceedings of Robotics: Science and Systems VIII, 2012.
- G-learning (
Fox et al., 2016),
Fox, R., Pakman, A., and Tishby, N. Taming the noise in reinforcement learning via soft updates. In Conf. on Uncertainty in Artificial Intelligence, 2016.
- PGQ (
O’Donoghue et al., 2016);recent proposals in deep RL
O’Donoghue, B., Munos, R., Kavukcuoglu, K., and Mnih, V. PGQ: Combining policy gradient and Q-learning. arXiv preprint arXiv:1611.01626, 2016
我的微信公众号名称:深度学习与先进智能决策
微信公众号ID:MultiAgent1024
公众号介绍:主要研究分享深度学习、机器博弈、强化学习等相关内容!期待您的关注,欢迎一起学习交流进步!
最后
以上就是优雅面包最近收集整理的关于【5分钟 Paper】Reinforcement Learning with Deep Energy-Based Policies的全部内容,更多相关【5分钟内容请搜索靠谱客的其他文章。

![[ICML 2015] Massively Parallel Methods for Deep Reinforcement LearningIntroductionDistributed ArchitectureExperiments](https://www.shuijiaxian.com/files_image/reation/bcimg2.png)






发表评论 取消回复