Q-Learning算法详解:




参考博文:1、http://blog.csdn.NET/pi9nc/article/details/27649323
2、http://mnemstudio.org/path-finding-q-learning-example-1.htm
JAVA代码
import java.util.Random;
public class QLearning1
{
private static final int Q_SIZE = 6;//状态数
private static final double GAMMA = 0.8;//学习参数
private static final int ITERATIONS = 10;//迭代次数
private static final int INITIAL_STATES[] = new int[] {1, 3, 5, 2, 4, 0};//随机初始状态
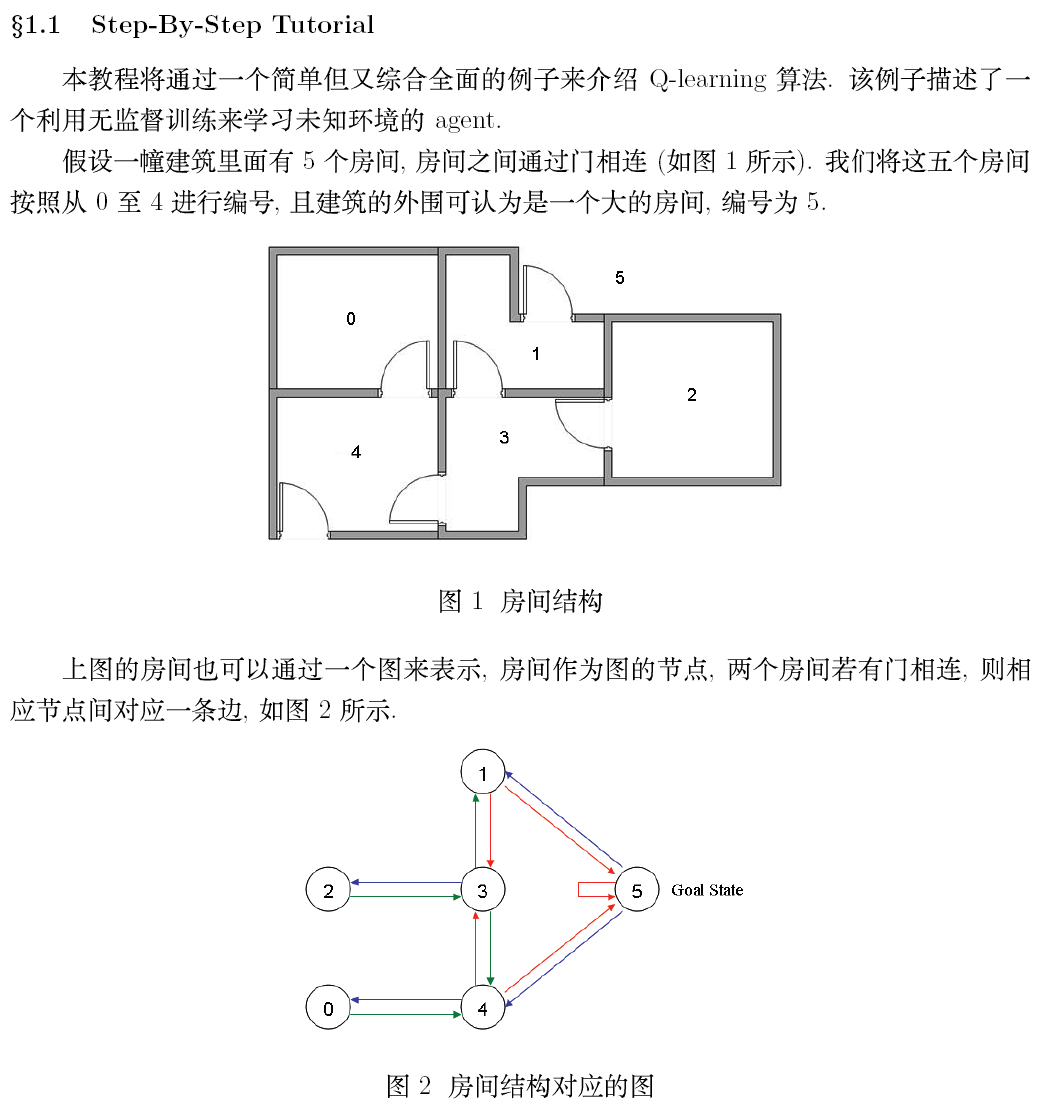
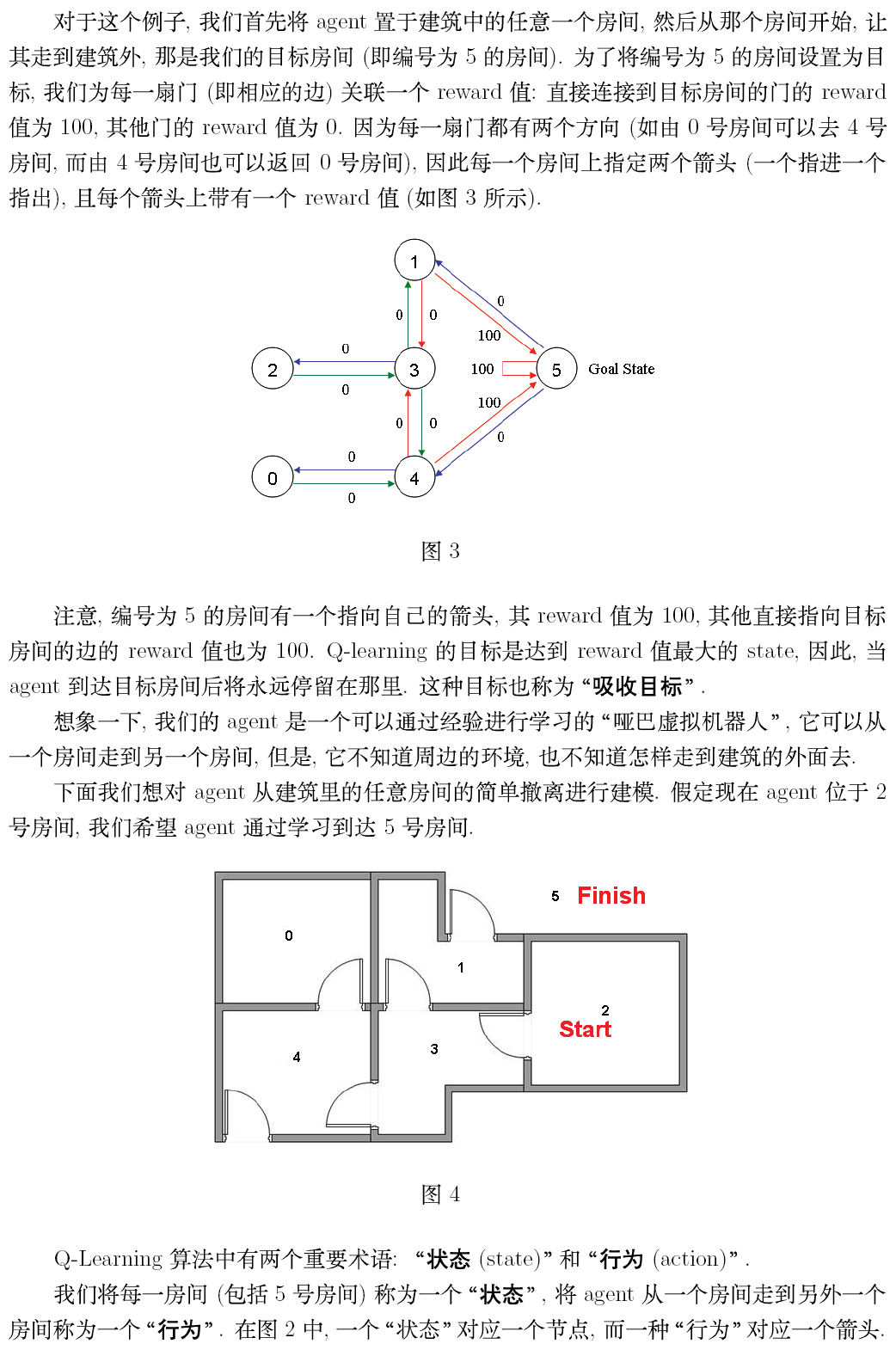
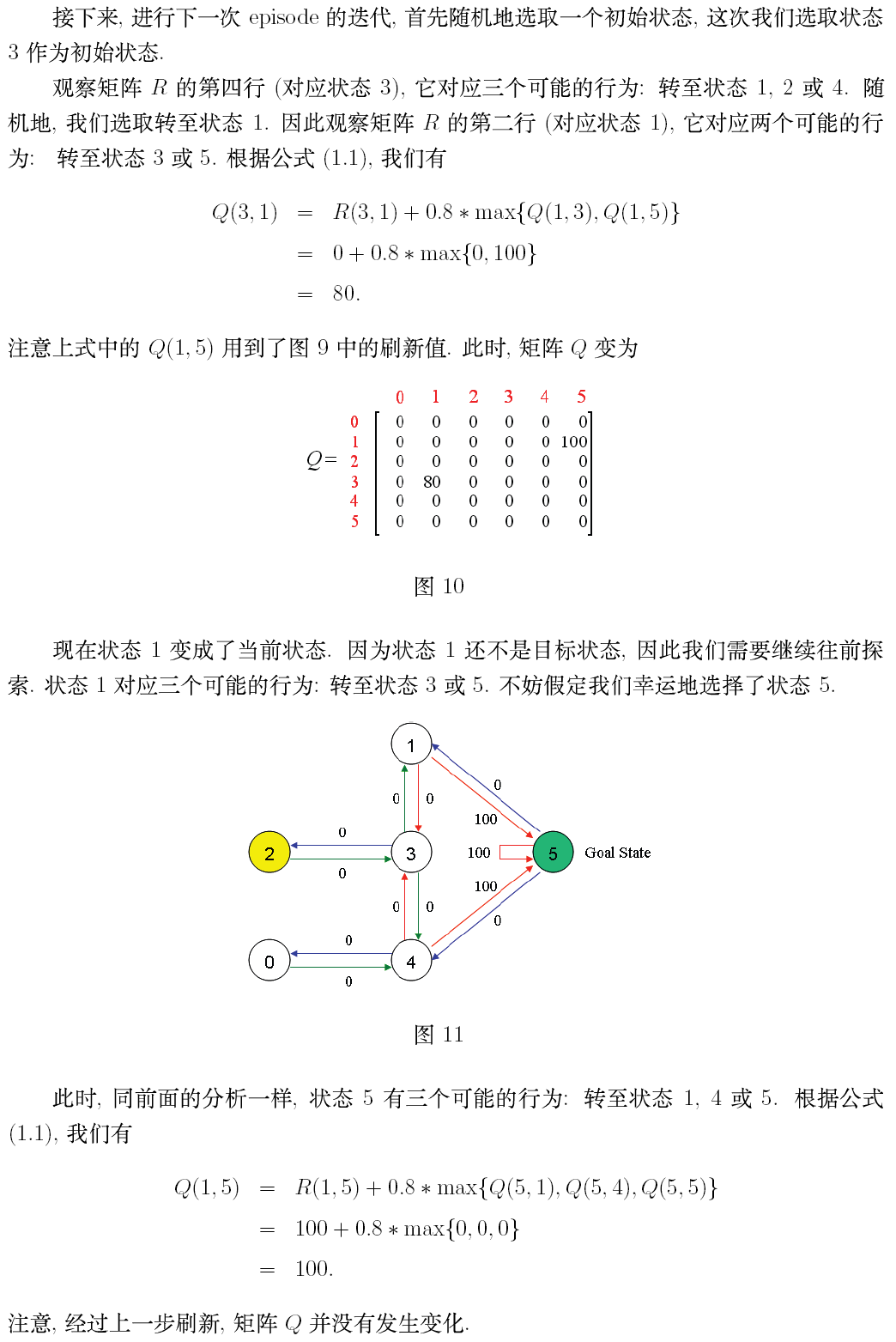
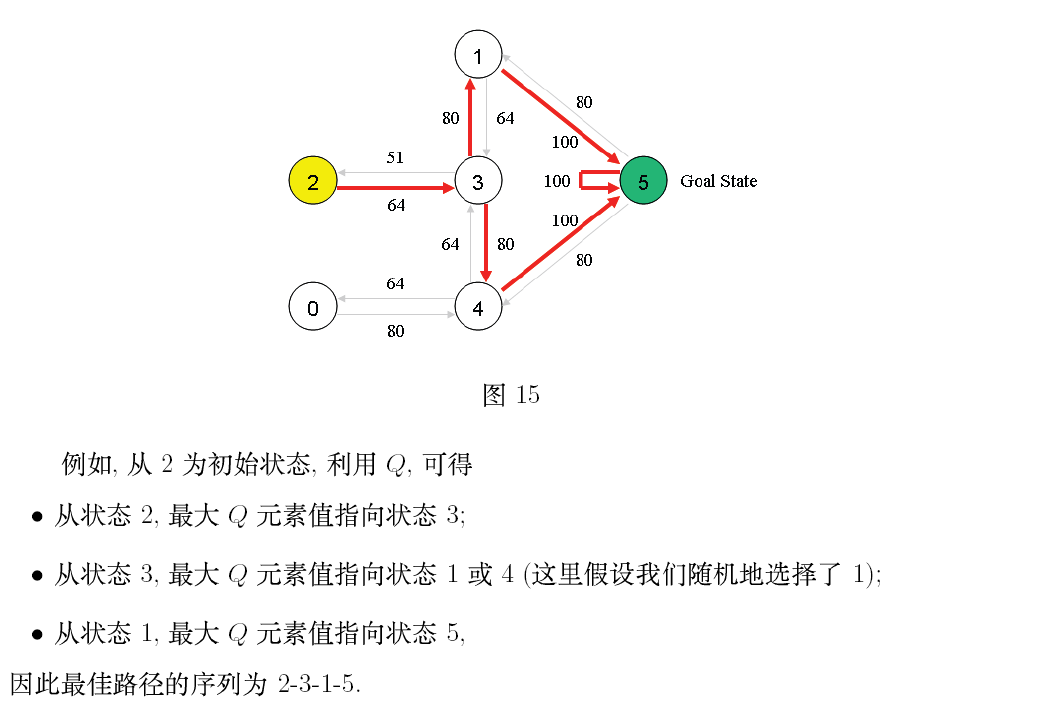
private static final int R[][] = new int[][] {{-1, -1, -1, -1, 0, -1}, //reward矩阵,-1表示相应节点之间没有相连
{-1, -1, -1, 0, -1, 100},
{-1, -1, -1, 0, -1, -1},
{-1, 0, 0, -1, 0, -1},
{0, -1, -1, 0, -1, 100},
{-1, 0, -1, -1, 0, 100}};
private static int q[][] = new int[Q_SIZE][Q_SIZE];//用来表示已经学到的知识
private static int currentState = 0;//当前状态序号
private static void train()
{
initialize();//初始化Q矩阵 --》零矩阵
// Perform training, starting at all initial states.
for(int j = 0; j < ITERATIONS; j++)
{
for(int i = 0; i < Q_SIZE; i++)
{
episode(INITIAL_STATES[i]);//迭代10次,每一次对将一个状态作为初始状态
} // i
} // j
System.out.println("Q Matrix values:");
for(int i = 0; i < Q_SIZE; i++)
{
for(int j = 0; j < Q_SIZE; j++)
{
System.out.print(q[i][j] + ",t");
} // j
System.out.print("n");
} // i
System.out.print("n");
return;
}
private static void test()
{
// Perform tests, starting at all initial states.
System.out.println("Shortest routes from initial states:");
for(int i = 0; i < Q_SIZE; i++)
{
currentState = INITIAL_STATES[i];
int newState = 0;
do
{
newState = maximum(currentState, true);//最大值的位置
System.out.print(currentState + ", ");
currentState = newState;
}while(currentState < 5);
System.out.print("5n");
}
return;
}
private static void episode(final int initialState)//每一个training session
{
currentState = initialState;
// Travel from state to state until goal state is reached.
do
{
chooseAnAction();
}while(currentState == 5);
// When currentState = 5, Run through the set once more for convergence.
for(int i = 0; i < Q_SIZE; i++)
{
chooseAnAction();
}
return;
}
private static void chooseAnAction()
{
int possibleAction = 0;
// Randomly choose a possible action connected to the current state.
possibleAction = getRandomAction(Q_SIZE);
if(R[currentState][possibleAction] >= 0){
q[currentState][possibleAction] = reward(possibleAction);
currentState = possibleAction;
}
return;
}
private static int getRandomAction(final int upperBound)
{
int action = 0;
boolean choiceIsValid = false;
// Randomly choose a possible action connected to the current state.
while(choiceIsValid == false)
{
// Get a random value between 0(inclusive) and 6(exclusive).
action = new Random().nextInt(upperBound);
if(R[currentState][action] > -1){
choiceIsValid = true;
}
}
return action;
}
private static void initialize()
{
for(int i = 0; i < Q_SIZE; i++)
{
for(int j = 0; j < Q_SIZE; j++)
{
q[i][j] = 0;
} // j
} // i
return;
}
private static int maximum(final int State, final boolean ReturnIndexOnly)
{
// If ReturnIndexOnly = True, the Q matrix index is returned.
// If ReturnIndexOnly = False, the Q matrix value is returned.
int winner = 0;
boolean foundNewWinner = false;
boolean done = false;
while(!done)
{
foundNewWinner = false;
for(int i = 0; i < Q_SIZE; i++)
{
if(i != winner){ // Avoid self-comparison.
if(q[State][i] > q[State][winner]){
winner = i;
foundNewWinner = true;
}
}
}
if(foundNewWinner == false){
done = true;
}
}
if(ReturnIndexOnly == true){//for test
return winner;
}else{//for training
return q[State][winner];
}
}
private static int reward(final int Action)
{
return (int)(R[currentState][Action] + (GAMMA * maximum(Action, false)));
}
public static void main(String[] args)
{
train();
test();
}
}
最后
以上就是光亮未来最近收集整理的关于Q-Learning分析的全部内容,更多相关Q-Learning分析内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复