活动地址:CSDN21天学习挑战赛
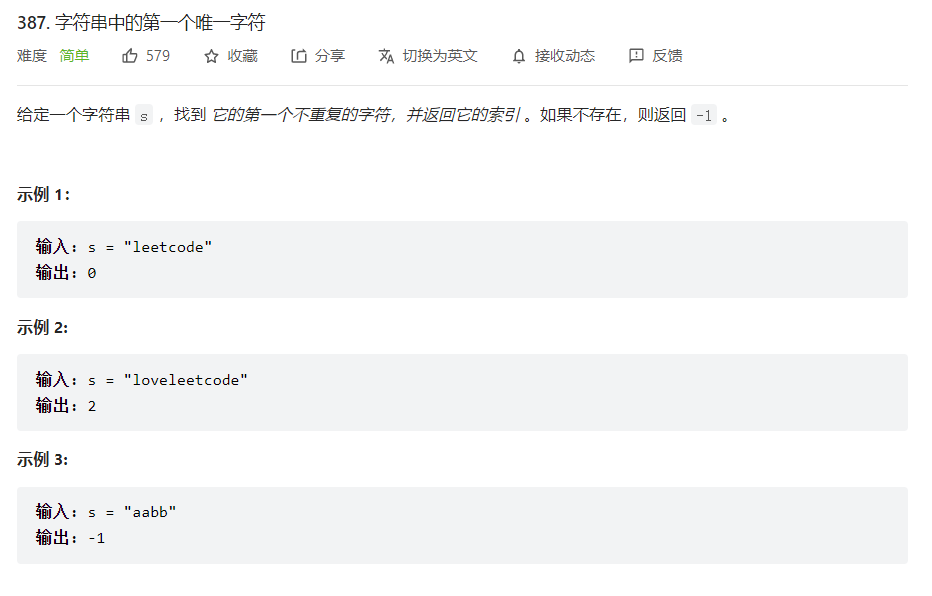
一、字符串中的第一个唯一字符
 第一种方法
第一种方法
根据题意是返回字符的索引,所以我没可以把字符串放到数组中,又因为一共有26个字母,所以我没创建一个容量为26的数组把字符串放进去,利用哈希的思想来统计数据,最后看第一个字母数量为1的,返回就行。
public int firstUniqChar(String s) {
int[] arr = new int[26];
char[] chars = s.toCharArray();
//统计
for (int i = chars.length - 1; i >= 0; i--) {
arr[chars[i] - 'a'] = arr[chars[i] - 'a'] + 1;
}
//找出第一次出现的字母
for (int i = 0; i < chars.length; i++) {
if (arr[chars[i] - 'a'] == 1) {
return i;
}
}
return -1;
}第二种方法
双层循环,一个一个检验。遍历一圈后如果没有和当前待检验的字符相同且下标不同的字符,则输出当前字符下标,否则,继续检验下一个字符,全部检验完后未发现符合条件字符,则输出-1。然后通过continue跳出内层循环,直接开启下一个外层循环。
public int firstUniqChar(String s) {
char[] arr = s.toCharArray();
int i = 0 , len = arr.length;
label:
while(i < len){
for(int j=0; j<len; ++j){
if(arr[i]==arr[j] && i != j){
++i; continue label;
}
}
return i;
}
return -1;
}
第三种方法
利用哈希的思想,第一次遍历的时候记录每个字符出现的次数,然后再第二次遍历的时候,只要他对应的value值是一,那么就返回。
public int firstUniqChar(String s) {
Map<Character, Integer> map = new HashMap<>();
for (int i = 0; i < s.length(); ++i) {
char ch = s.charAt(i);
map.put(ch, map.getOrDefault(ch, 0) + 1);
}
for (int i = 0; i < s.length(); ++i) {
if (map.get(s.charAt(i)) == 1) {
return i;
}
}
return -1;
}
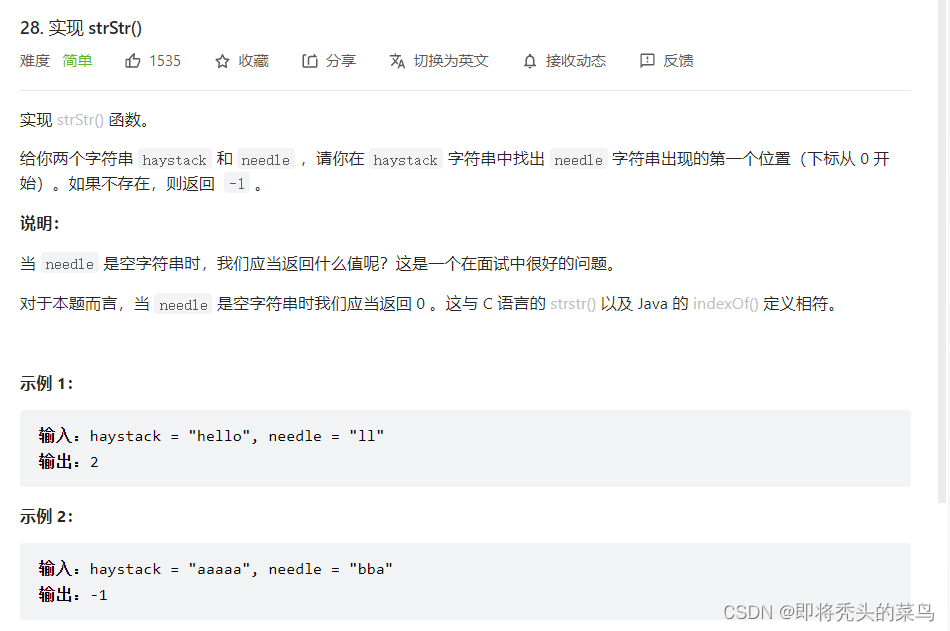
二、实现strStr()
思路
我这里的想法很粗暴,就是让字符串 needle 与字符串 haystack 的所有长度为 m 的子串都匹配一次,匹配失败就break,进行下一次匹配。都匹配就返回-1。
public int strStr(String haystack, String needle) {
int haylen = haystack.length();
int needlen = needle.length();
for (int i = 0; i + haylen <= needlen; i++) {
boolean flag = true;
for (int j = 0; j < haylen; j++) {
if (haystack.charAt(i + j) != needle.charAt(j)) {
flag = false;
break;
}
}
if (flag) {
return i;
}
}
return -1;
}
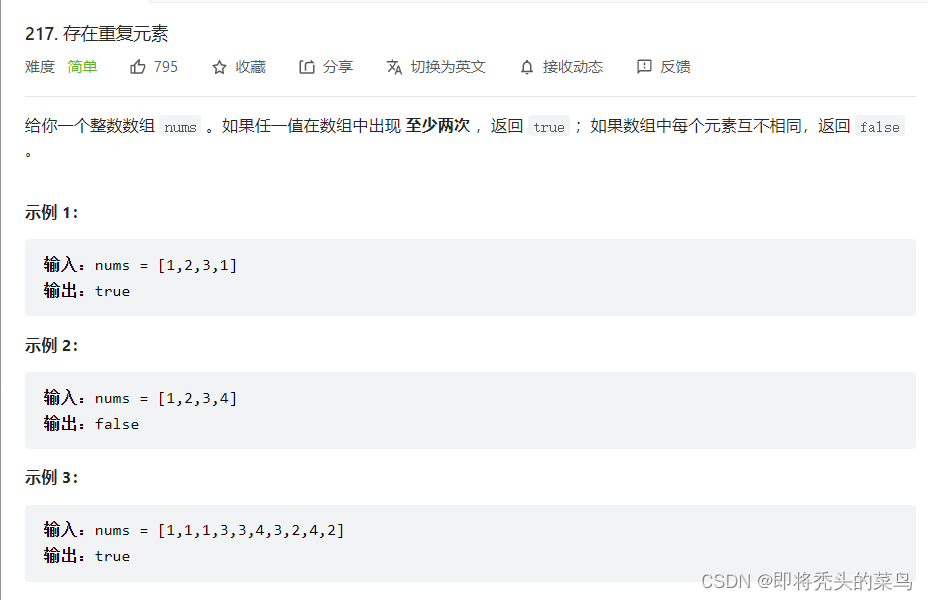
三、存在重复元素
第一种方法
直接对数组排序,然后判断相邻元素是否相等。
public boolean containsDuplicate(int[] nums) {
Arrays.sort(nums);
for (int i = 0; i < nums.length - 1; i++) {
if (nums[i] == nums[i+1]) {
return true;
}
}
return false;
}第二种方法
利用哈希的思想,因为set里面不允许出现重复的元素,所以直接遍历数组,看数组元素是否以及再set集合中。
public boolean containsDuplicate(int[] nums) {
Set<Integer> set = new HashSet<>();
for (int x : nums) {
if (!set.add(x)) {
return true;
}
}
return false;
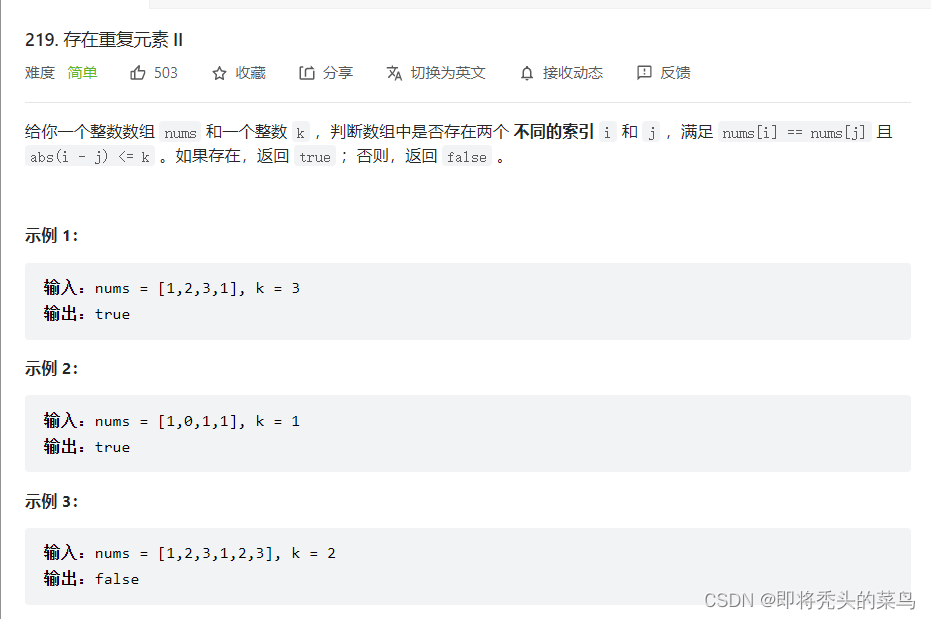
}四、存在重复元素Ⅱ
思路
这个题和上面那个题没什么不同,也是用哈希的思想,还是利用set,因为一个哈希集合里面最多存在k个元素,如果有重复出现的值,那么就说明再k的距离范围内,存在重复的元素。
public boolean containsNearbyDuplicate(int[] nums, int k) {
HashSet<Integer> set = new HashSet<>();
for(int i = 0; i < nums.length; i++) {
if(set.contains(nums[i])) {
return true;
}
set.add(nums[i]);
if(set.size() > k) {
set.remove(nums[i - k]);
}
}
return false;
}
五、链表的中间节点
思路
快慢指针,用两个指针 slow与 fast 一起遍历链表。slow 一次走一步,fast 一次走两步。那么当 fast 到达链表的末尾时,slow 必然位于中间。
public ListNode middleNode(ListNode head) {
ListNode fast = head;
ListNode slow = head;
while (fast != null && fast.next != null) {
slow = slow.next;
fast = fast.next.next;
}
return slow;
}最后
以上就是无辜寒风最近收集整理的关于力扣+牛客--刷题记录 二、实现strStr() 三、存在重复元素四、存在重复元素Ⅱ五、链表的中间节点的全部内容,更多相关力扣+牛客--刷题记录 二、实现strStr() 三、存在重复元素四、存在重复元素Ⅱ五、链表内容请搜索靠谱客的其他文章。








发表评论 取消回复