处理数据部分 processData
import pandas as pd
import numpy as np
from sklearn.preprocessing import MinMaxScaler, LabelEncoder
from sklearn.model_selection import train_test_split
#带入数据
'''
train.csv
Id,Label,I1,I2,I3,I4,I5,I6,I7,I8,I9,I10,I11,I12,I13,C1,C2,C3,C4,C5,C6,C7,C8,C9,C10,C11,C12,C13,C14,C15,C16,C17,C18,C19,C20,C21,C22,C23,C24,C25,C26
test.csv:
Id,I1,I2,I3,I4,I5,I6,I7,I8,I9,I10,I11,I12,I13,C1,C2,C3,C4,C5,C6,C7,C8,C9,C10,C11,C12,C13,C14,C15,C16,C17,C18,C19,C20,C21,C22,C23,C24,C25,C26
'''
train_df=pd.read_csv('../PNN_data/train.csv')
test_df=pd.read_csv('../PNN_data/test.csv')
print(train_df.shape, test_df.shape)
#### 找出train test的所有的特征
#### (1)将训练集的label取出来 这样训练集中就只剩下 ID +特征 测试集中是Id +特征
#### (2)将修剪后的train 和test进行融合 data:ID +所有的特征
#### (3)将融合后的data中的ID进行删除
train_df.head()
#将数据的label进行合并
label=train_df['Label']
#将train的label赋予label变量后 删去train 中label的内容
del train_df['Label']
data_df = pd.concat((train_df, test_df))
data_df.head()
del data_df['Id']
#### 将数值类型特征与类别特征进行分离
#dense_feas 数值特征 sparse_feas:类别特征
sparse_feas=[col for col in data_df.columns if col[0]=='C']
dense_feas=[col for col in data_df.columns if col[0]=='I']
#### 将类别特征 数值特征的缺失值进行填充
#### 类别特征的缺失值填成‘-1’ 数值型的缺失值填充为0
data_df[sparse_feas] = data_df[sparse_feas].fillna('-1')
data_df[dense_feas] = data_df[dense_feas].fillna(0)
# 进行编码 类别特征编码
#LabelEncoder()对目标标签进行编码,值在0到n_class -1之间
#fit_transform(trainData)对部分数据先拟合fit,找到该part的整体指标,如均值、方差、最大值最小值等等(根据具体转换的目的),然后对该trainData进行转换transform,从而实现数据的标准化、归一化等等
for feat in sparse_feas:
le = LabelEncoder()
data_df[feat] = le.fit_transform(data_df[feat])
#%%
# 数值特征归一化
mms = MinMaxScaler()
data_df[dense_feas] = mms.fit_transform(data_df[dense_feas])
# 分开测试集和训练集
train = data_df[:train_df.shape[0]]
test = data_df[train_df.shape[0]:]
train['Label'] = label
train_set, val_set = train_test_split(train, test_size = 0.1, random_state=2020)
# 这里把特征列汇总一下
train_set.reset_index(drop=True, inplace=True)
val_set.reset_index(drop=True, inplace=True)
train_set.to_csv('../PNN_processData/train_set.csv', index=0)
val_set.to_csv('../PNN_processData/val_set.csv', index=0)
test.to_csv('../PNN_processData/test.csv', index=0)
其中:
train_df: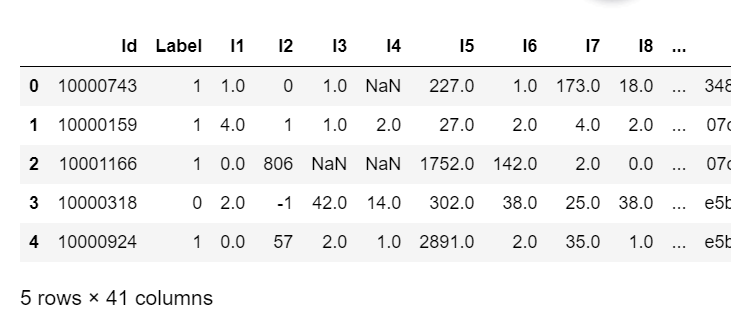
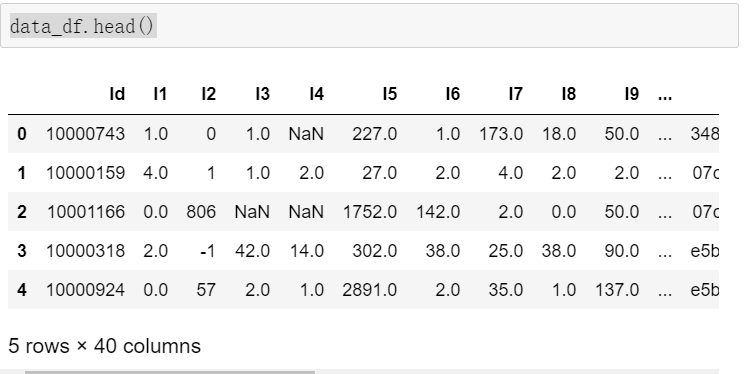
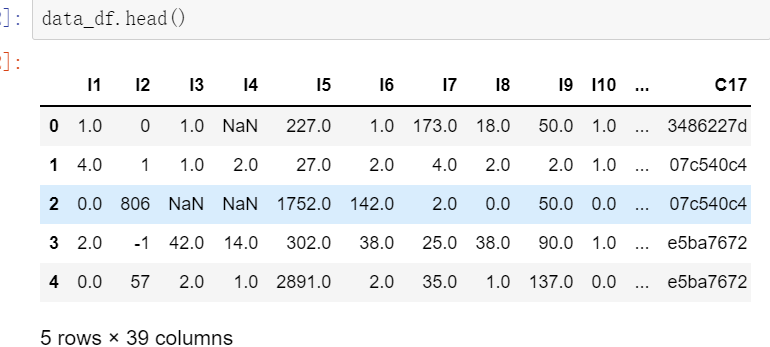

其他的参数就不列举了 大家想看的可以评论邮箱 我会统一发给大家
PNN 模型部分
## Description:
这里我们尝试建立一个PNN网络来完成一个ctr预测的问题。 关于Pytorch的建模流程, 主要有四步:
1. 准备数据
2. 建立模型
3. 训练模型
4. 使用和保存
import datetime
import numpy as np
import pandas as pd
import torch
from torch.utils.data import DataLoader, Dataset, TensorDataset
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
# from torchkeras import summary, Model
from sklearn.metrics import roc_auc_score
import warnings
warnings.filterwarnings('ignore')
#导入数据
'''
train_set:I~C
test_set:I~C
'''
train_set=pd.read_csv('../PNN_processData/train_set.csv')
test_set=pd.read_csv('../PNN_processData/test.csv')
val_set=pd.read_csv('../PNN_processData/val_set.csv')
#离散型的特征进入Embedding层 数值型的特征之间进入下一层
data_df = pd.concat((train_set, val_set, test_set))
#s数值特征一共14个 所以将I1~I14
#离散型特征有26个 所以是C1-C26
dense_feas = ['I'+str(i) for i in range(1, 14)]
sparse_feas = ['C'+str(i) for i in range(1, 27)]
# 定义一个稀疏特征的embedding映射,
# 字典{key: value}, key表示每个稀疏特征,
# value表示数据集data_df对应列的不同取值个数, 作为embedding输入维度
#Pandas nunique() 用于获取唯一值的统计次数
sparse_feas_map = {}
for key in sparse_feas:
sparse_feas_map[key]=data_df[key].nunique()
#封装所有的特征信息
features_info=[dense_feas,sparse_feas,sparse_feas_map]
dl_train_dataset = TensorDataset(torch.tensor(train_set.drop(columns='Label').values).float(), torch.tensor(train_set['Label']).float())
dl_val_dataset = TensorDataset(torch.tensor(val_set.drop(columns='Label').values).float(), torch.tensor(val_set['Label']).float())
dl_train = DataLoader(dl_train_dataset, shuffle=True, batch_size=16)
dl_vaild = DataLoader(dl_val_dataset, shuffle=True, batch_size=16)
a=[256,128,64]
list(zip(a[:-1], a[1:]))
# 定义一个全连接层的神经网络
class DNN(nn.Module):
def __init__(self, hidden_units, dropout=0.):
"""
hidden_units:列表, 每个元素表示每一层的神经单元个数,比如[256, 128, 64],两层网络, 第一层神经单元128个,第二层64,注意第一个是输入维度
dropout: 失活率
"""
super(DNN, self).__init__()
# 下面创建深层网络的代码 由于Pytorch的nn.Linear需要的输入是(输入特征数量, 输出特征数量)格式, 所以我们传入hidden_units,
# 必须产生元素对的形式才能定义具体的线性层, 且Pytorch中线性层只有线性层, 不带激活函数。 这个要与tf里面的Dense区分开。
self.dnn_network = nn.ModuleList([nn.Linear(layer[0], layer[1]) for layer in list(zip(hidden_units[:-1], hidden_units[1:]))])
self.dropout = nn.Dropout(p=dropout)
# 前向传播中, 需要遍历dnn_network, 不要忘了加激活函数
def forward(self, x):
for linear in self.dnn_network:
x = linear(x)
x = F.relu(x)
x = self.dropout(x)
return x
class ProductLayer(nn.Module):
def __init__(self, mode, embed_dim, field_num, hidden_units):
super(ProductLayer, self).__init__()
self.mode = mode
# product层, 由于交叉这里分为两部分, 一部分是单独的特征运算, 也就是上面结构的z部分, 一个是两两交叉, p部分, 而p部分还分为了内积交叉和外积交叉
# 所以, 这里需要自己定义参数张量进行计算
# z部分的w, 这里的神经单元个数是hidden_units[0], 上面我们说过, 全连接层的第一层神经单元个数是hidden_units[1], 而0层是输入层的神经
# 单元个数, 正好是product层的输出层 关于维度, 这个可以看在博客中的分析
self.w_z = nn.Parameter(torch.rand([field_num, embed_dim, hidden_units[0]]))
# p部分, 分内积和外积两种操作
if mode == 'in':
self.w_p = nn.Parameter(torch.rand([field_num, field_num, hidden_units[0]]))
else:
self.w_p = nn.Parameter(torch.rand([embed_dim, embed_dim, hidden_units[0]]))
self.l_b = torch.rand([hidden_units[0], ], requires_grad=True)
def forward(self, z, sparse_embeds):
# lz部分
l_z = torch.mm(z.reshape(z.shape[0], -1), self.w_z.permute((2, 0, 1)).reshape(self.w_z.shape[2], -1).T)# (None, hidden_units[0])
# lp 部分
if self.mode == 'in': # in模式 内积操作 p就是两两embedding先内积得到的[field_dim, field_dim]的矩阵
p = torch.matmul(sparse_embeds, sparse_embeds.permute((0, 2, 1))) # [None, field_num, field_num]
else: # 外积模式 这里的p矩阵是两两embedding先外积得到n*n个[embed_dim, embed_dim]的矩阵, 然后对应位置求和得到最终的1个[embed_dim, embed_dim]的矩阵
# 所以这里实现的时候, 可以先把sparse_embeds矩阵在field_num方向上先求和, 然后再外积
f_sum = torch.unsqueeze(torch.sum(sparse_embeds, dim=1), dim=1) # [None, 1, embed_dim]
p = torch.matmul(f_sum.permute((0, 2,1)), f_sum) # [None, embed_dim, embed_dim]
l_p = torch.mm(p.reshape(p.shape[0], -1), self.w_p.permute((2, 0, 1)).reshape(self.w_p.shape[2], -1).T) # [None, hidden_units[0]]
output = l_p + l_z + self.l_b
return output
#%%
# 下面我们定义真正的PNN网络
# 这里的逻辑是底层输入(类别型特征) -> embedding层 -> product 层 -> DNN -> 输出
class PNN(nn.Module):
def __init__(self, feature_info, hidden_units, mode='in', dnn_dropout=0., embed_dim=10, outdim=1):
"""
DeepCrossing:
feature_info: 特征信息(数值特征, 类别特征, 类别特征embedding映射)
hidden_units: 列表, 全连接层的每一层神经单元个数, 这里注意一下, 第一层神经单元个数实际上是hidden_units[1], 因为hidden_units[0]是输入层
dropout: Dropout层的失活比例
embed_dim: embedding的维度m
outdim: 网络的输出维度
"""
super(PNN, self).__init__()
self.dense_feas, self.sparse_feas, self.sparse_feas_map = feature_info
self.field_num = len(self.sparse_feas)
self.dense_num = len(self.dense_feas)
self.mode = mode
self.embed_dim = embed_dim
# embedding层, 这里需要一个列表的形式, 因为每个类别特征都需要embedding
self.embed_layers = nn.ModuleDict({
'embed_' + str(key): nn.Embedding(num_embeddings=val, embedding_dim=self.embed_dim)
for key, val in self.sparse_feas_map.items()
})
# Product层
self.product = ProductLayer(mode, embed_dim, self.field_num, hidden_units)
# dnn 层
hidden_units[0] += self.dense_num
self.dnn_network = DNN(hidden_units, dnn_dropout)
self.dense_final = nn.Linear(hidden_units[-1], 1)
def forward(self, x):
dense_inputs, sparse_inputs = x[:, :13], x[:, 13:] # 数值型和类别型数据分开
sparse_inputs = sparse_inputs.long() # 需要转成长张量, 这个是embedding的输入要求格式
sparse_embeds = [self.embed_layers['embed_'+key](sparse_inputs[:, i]) for key, i in zip(self.sparse_feas_map.keys(), range(sparse_inputs.shape[1]))]
# 上面这个sparse_embeds的维度是 [field_num, None, embed_dim]
sparse_embeds = torch.stack(sparse_embeds)
sparse_embeds = sparse_embeds.permute((1, 0, 2)) # [None, field_num, embed_dim] 注意此时空间不连续, 下面改变形状不能用view,用reshape
z = sparse_embeds
# product layer
sparse_inputs = self.product(z, sparse_embeds)
# 把上面的连起来, 注意此时要加上数值特征
l1 = F.relu(torch.cat([sparse_inputs, dense_inputs], axis=-1))
# dnn_network
dnn_x = self.dnn_network(l1)
outputs = F.sigmoid(self.dense_final(dnn_x))
outputs = outputs.squeeze(-1)
return output
# 模型的相关设置
def auc(y_pred, y_true):
pred = y_pred.data
y = y_true.data
return roc_auc_score(y, pred) # 计算AUC, 但要注意如果y只有一个类别的时候, 会报错
loss_func = nn.BCELoss()
optimizer = torch.optim.Adam(params=net.parameters(), lr=0.0001)
metric_func = auc
metric_name = 'auc'
#%%
epochs = 6
log_step_freq = 10
dfhistory = pd.DataFrame(columns=["epoch", "loss", metric_name, "val_loss", "val_"+metric_name])
print('Start Training...')
nowtime = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
print('========='*8 + "%s" %nowtime)
for epoch in range(1, epochs+1):
# 训练阶段
net.train()
loss_sum = 0.0
metric_sum = 0.0
step = 1
for step, (features, labels) in enumerate(dl_train, 1):
# 梯度清零
optimizer.zero_grad()
# 正向传播
predictions = net(features)
loss = loss_func(predictions, labels)
try: # 这里就是如果当前批次里面的y只有一个类别, 跳过去
metric = metric_func(predictions, labels)
except ValueError:
pass
# 反向传播求梯度
loss.backward()
optimizer.step()
# 打印batch级别日志
loss_sum += loss.item()
metric_sum += metric.item()
if step % log_step_freq == 0:
print(("[step = %d] loss: %.3f, "+metric_name+": %.3f") %
(step, loss_sum/step, metric_sum/step))
# 验证阶段
net.eval()
val_loss_sum = 0.0
val_metric_sum = 0.0
val_step = 1
for val_step, (features, labels) in enumerate(dl_vaild, 1):
with torch.no_grad():
predictions = net(features)
val_loss = loss_func(predictions, labels)
try:
val_metric = metric_func(predictions, labels)
except ValueError:
pass
val_loss_sum += val_loss.item()
val_metric_sum += val_metric.item()
# 记录日志
info = (epoch, loss_sum/step, metric_sum/step, val_loss_sum/val_step, val_metric_sum/val_step)
dfhistory.loc[epoch-1] = info
# 打印epoch级别日志
print(("nEPOCH = %d, loss = %.3f,"+ metric_name +
" = %.3f, val_loss = %.3f, "+"val_"+ metric_name+" = %.3f")
%info)
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("n"+"=========="*8 + "%s"%nowtime)
print('Finished Training...')
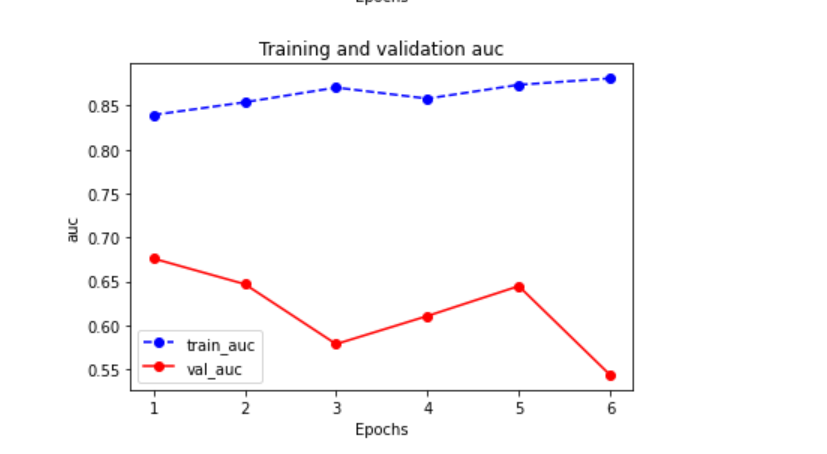
训练的结果如下
Start Training...
========================================================================2022-04-26 09:10:13
[step = 10] loss: 0.456, auc: 0.850
[step = 20] loss: 0.425, auc: 0.795
[step = 30] loss: 0.441, auc: 0.809
[step = 40] loss: 0.438, auc: 0.819
[step = 50] loss: 0.428, auc: 0.822
[step = 60] loss: 0.439, auc: 0.820
[step = 70] loss: 0.433, auc: 0.830
[step = 80] loss: 0.427, auc: 0.837
[step = 90] loss: 0.422, auc: 0.839
EPOCH = 1, loss = 0.422,auc = 0.839, val_loss = 0.443, val_auc = 0.676
================================================================================2022-04-26 09:10:22
[step = 10] loss: 0.380, auc: 0.849
[step = 20] loss: 0.441, auc: 0.842
[step = 30] loss: 0.447, auc: 0.838
[step = 40] loss: 0.433, auc: 0.851
[step = 50] loss: 0.415, auc: 0.858
[step = 60] loss: 0.421, auc: 0.851
[step = 70] loss: 0.418, auc: 0.861
[step = 80] loss: 0.414, auc: 0.848
[step = 90] loss: 0.410, auc: 0.854
EPOCH = 2, loss = 0.410,auc = 0.854, val_loss = 0.473, val_auc = 0.647
================================================================================2022-04-26 09:10:32
[step = 10] loss: 0.413, auc: 0.867
[step = 20] loss: 0.422, auc: 0.875
[step = 30] loss: 0.414, auc: 0.879
[step = 40] loss: 0.390, auc: 0.885
[step = 50] loss: 0.379, auc: 0.888
[step = 60] loss: 0.372, auc: 0.889
[step = 70] loss: 0.378, auc: 0.882
[step = 80] loss: 0.382, auc: 0.874
[step = 90] loss: 0.389, auc: 0.870
EPOCH = 3, loss = 0.389,auc = 0.870, val_loss = 0.457, val_auc = 0.579
================================================================================2022-04-26 09:10:35
[step = 10] loss: 0.351, auc: 0.953
[step = 20] loss: 0.374, auc: 0.913
[step = 30] loss: 0.361, auc: 0.898
[step = 40] loss: 0.355, auc: 0.863
[step = 50] loss: 0.343, auc: 0.853
[step = 60] loss: 0.346, auc: 0.858
[step = 70] loss: 0.361, auc: 0.856
[step = 80] loss: 0.364, auc: 0.865
[step = 90] loss: 0.372, auc: 0.858
EPOCH = 4, loss = 0.372,auc = 0.858, val_loss = 0.466, val_auc = 0.611
================================================================================2022-04-26 09:10:38
[step = 10] loss: 0.301, auc: 0.931
[step = 20] loss: 0.343, auc: 0.897
[step = 30] loss: 0.327, auc: 0.915
[step = 40] loss: 0.320, auc: 0.912
[step = 50] loss: 0.323, auc: 0.915
[step = 60] loss: 0.333, auc: 0.887
[step = 70] loss: 0.345, auc: 0.877
[step = 80] loss: 0.356, auc: 0.873
[step = 90] loss: 0.358, auc: 0.874
EPOCH = 5, loss = 0.358,auc = 0.874, val_loss = 0.456, val_auc = 0.645
================================================================================2022-04-26 09:10:41
[step = 10] loss: 0.360, auc: 0.858
[step = 20] loss: 0.346, auc: 0.858
[step = 30] loss: 0.386, auc: 0.883
[step = 40] loss: 0.433, auc: 0.875
[step = 50] loss: 0.401, auc: 0.888
[step = 60] loss: 0.412, auc: 0.887
[step = 70] loss: 0.405, auc: 0.876
[step = 80] loss: 0.388, auc: 0.878
[step = 90] loss: 0.384, auc: 0.881
EPOCH = 6, loss = 0.384,auc = 0.881, val_loss = 0.488, val_auc = 0.544
================================================================================2022-04-26 09:10:45
Finished Training...
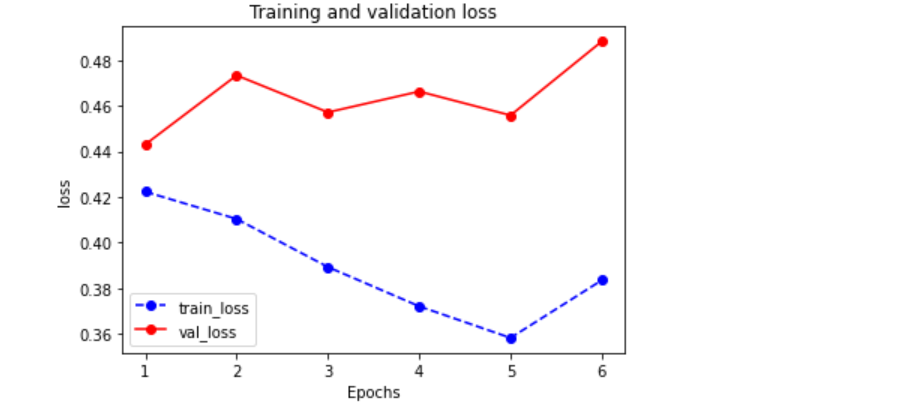
最后
以上就是结实宝马最近收集整理的关于PNN模型 Pytorch代码的全部内容,更多相关PNN模型内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复