tesseract-ocr介绍
-
光学字符识别,是指对图片文件中的文字进行分析识别,获取的过程
-
Tesseract - OCR 引擎最先由HP实验室于1985年开始研发,至1995年时已经成为OCR业内最准确的三款识别引擎之一。然而,HP不久便决定放弃OCR业务,Tesseract也从此尘封
-
数年以后,HP 意识到,与其将Tesseract束之高阁,不如贡献给开源软件业,让其重焕新生
-
在2005年,Tesseract 由美国内华达州信息技术研究所获得,并求诸于 Google 对 Tesseract 进行改进、消除Bug、优化工作,Tesseract 由惠普公司宣布开源,从2006年到现在,都由 Google 公司开发维护
java实现
1、maven引入
<dependency>
<groupId>net.java.dev.jna</groupId>
<artifactId>jna</artifactId>
<version>4.1.0</version>
</dependency>
<dependency>
<groupId>net.sourceforge.tess4j</groupId>
<artifactId>tess4j</artifactId>
<version>3.4.0</version>
<exclusions>
<exclusion>
<groupId>com.sun.jna</groupId>
<artifactId>jna</artifactId>
</exclusion>
</exclusions>
</dependency>
2、方法调用
public static void main(String[] args){
//加载待读取图片
File imageFile = new File("C:\Users\Desktop\wenzi.png");
//创建tess对象
ITesseract instance = new Tesseract();
//设置训练文件目录
instance.setDatapath("D:\autotest\tessdata");
//设置训练语言
instance.setLanguage("eng");
//执行转换
try {
//图片转图片流
BufferedImage img = ImageIO.read(imageFile);
// 这里对图片黑白处理,增强识别率.这里先通过截图,截取图片中需要识别的部分
img = ImageHelper.convertImageToGrayscale(img);
// 图片锐化,自己使用中影响识别率的主要因素是针式打印机字迹不连贯,所以锐化反而降低识别率
// img = ImageHelper.convertImageToBinary(img);
// 图片放大5倍,增强识别率(很多图片本身无法识别,放大7倍时就可以轻易识,但是考滤到客户电脑配置低,针式打印机打印不连贯的问题,这里就放大7倍)
img = ImageHelper.getScaledInstance(img, img.getWidth() * 7, img.getHeight() * 7);
String result = instance.doOCR(imageFile);
System.out.println("获取结果:"+result);
} catch (TesseractException | IOException e) {
e.printStackTrace();
}
}
注意:代码中的“D:autotesttessdata”路径为语言训练文件的存储路径
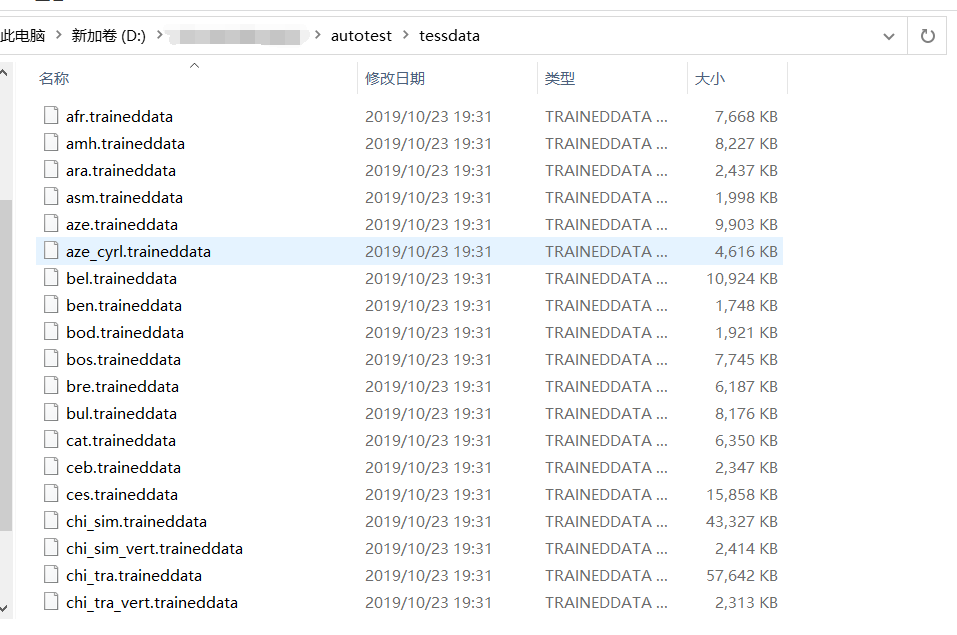
语言训练文件传送门 提取码:a9pm
自定义语言训练文件
除使用上述语言训练文件外,还可以自定义训练文件
- 下载jTessBoxEditor创建语言训练文件,文件传送门 提取码:ol8a
- 文件下载后设置环境变量
- 将文件夹tesseract-ocr路径设置到环境变量中
- 将需要识别的图片文件放至一个文件夹,图片越多识别率会比较高,工作量就会比较大
- 打开下载的 jTessBoxEditor
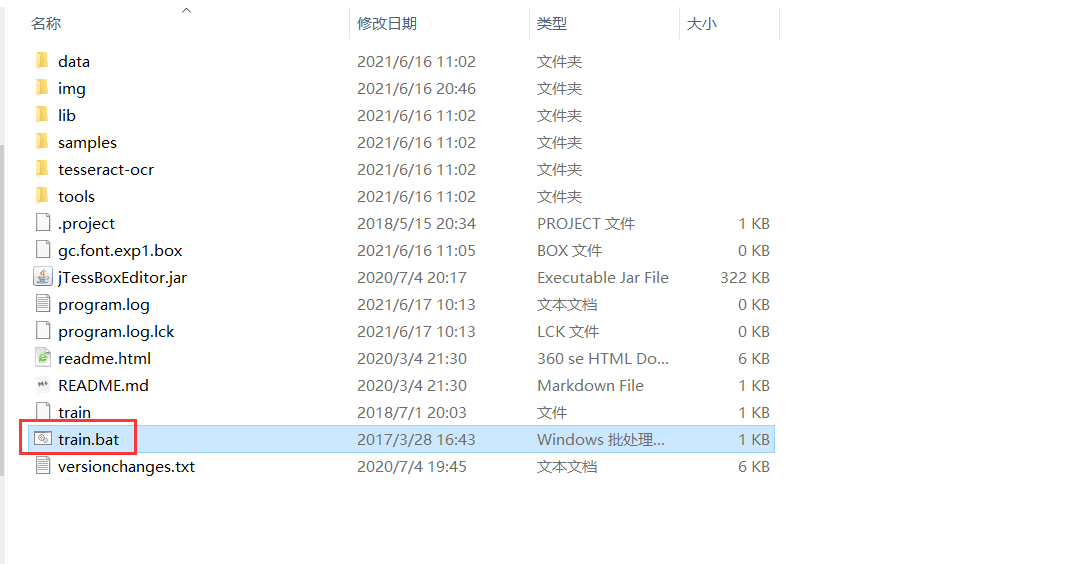
- 合并图片为tiff格式的图片,选择tools下的第一个菜单
- 选中需要识别的图片,命名按照规范命名
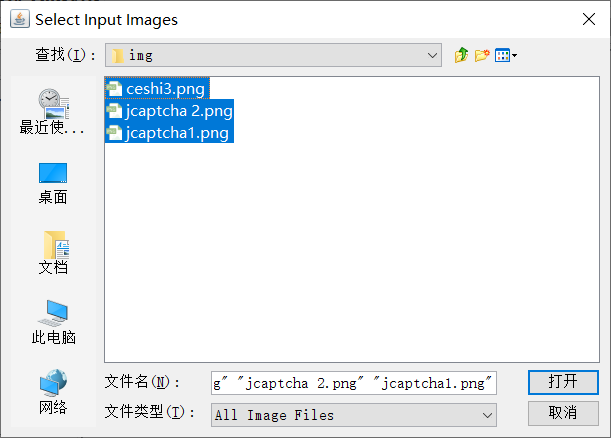
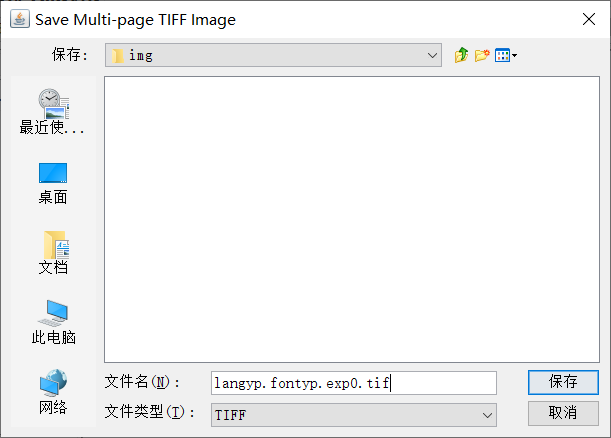
- 打开cmd进入到图片存放目录中,执行命令生成BOX文件
tesseract langyp.fontyp.exp0.tif langyp.fontyp.exp0 -l chi_sim batch.nochop makebox
- 调整字体坐标,调整识别错误的汉字。使用open打开刚才生成的tif文件,根据刚才生成的box文件调整字库。这个步骤才是真正核心的步骤,也是最麻烦的地方,有多个文件记得要翻页每个文件都手动调整
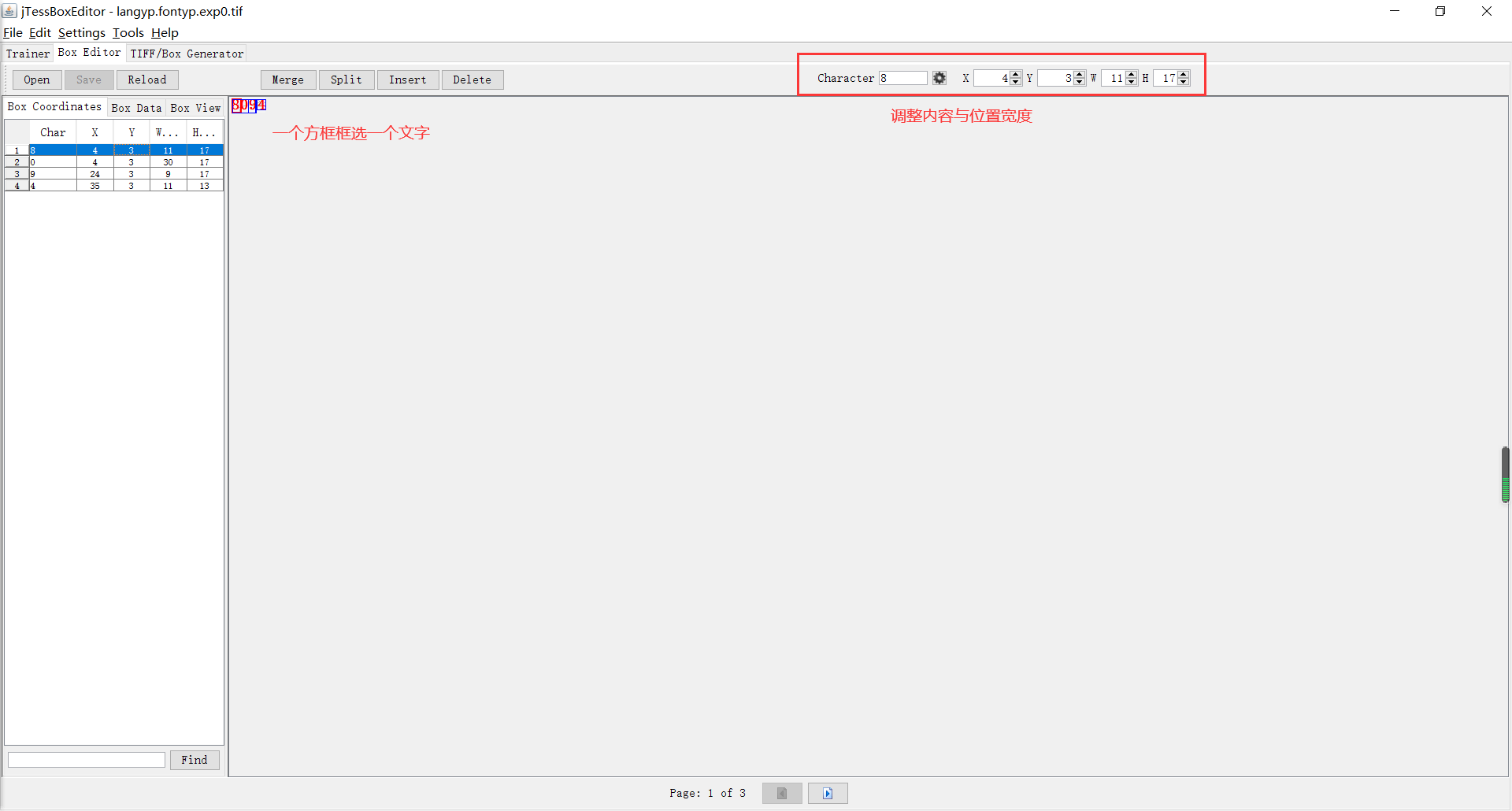
- 新建font_properties文件
tesseract langyp.fontyp.exp0.tif langyp.fontyp.exp0 -l chi_sim nobatch box.train
- 调整完成box文件后,就需要生成tr文件
tesseract langyp.fontyp.exp0.tif langyp.fontyp.exp0 -l chi_sim nobatch box.train
- 生成unicharset文件
unicharset_extractor langyp.fontyp.exp0.box
- 生成shape文件
shapeclustering -F font_properties -U unicharset -O langyp.unicharset langyp.fontyp.exp0.tr
- 生成聚集字符特征文件
mftraining -F font_properties -U unicharset -O langyp.unicharset langyp.fontyp.exp0.tr
- 生成字符正常化特征文件
cntraining langyp.fontyp.exp0.tr
- 重命名把目录下的unicharset、inttemp、pffmtable、shapetable、normproto这五个文件都加上fontyp.
rename normproto fontyp.normproto
rename inttemp fontyp.inttemp
rename pffmtable fontyp.pffmtable
rename unicharset fontyp.unicharset
rename shapetable fontyp.shapetable
- 组合文件,成功后会生成fontyp.traineddata训练文件
combine_tessdata fontyp.
将生成的训练文件放入最开始的tessdata文件夹中,instance.setLanguage(“fontyp”)使用
public static void main(String[] args){
//加载待读取图片
File imageFile = new File("C:\Users\Desktop\wenzi.png");
//创建tess对象
ITesseract instance = new Tesseract();
//设置训练文件目录
instance.setDatapath("D:\autotest\tessdata");
//设置训练语言
instance.setLanguage("fontyp");
//执行转换
try {
//图片转图片流
BufferedImage img = ImageIO.read(imageFile);
// 这里对图片黑白处理,增强识别率.这里先通过截图,截取图片中需要识别的部分
img = ImageHelper.convertImageToGrayscale(img);
// 图片锐化,自己使用中影响识别率的主要因素是针式打印机字迹不连贯,所以锐化反而降低识别率
// img = ImageHelper.convertImageToBinary(img);
// 图片放大5倍,增强识别率(很多图片本身无法识别,放大7倍时就可以轻易识,但是考滤到客户电脑配置低,针式打印机打印不连贯的问题,这里就放大7倍)
img = ImageHelper.getScaledInstance(img, img.getWidth() * 7, img.getHeight() * 7);
String result = instance.doOCR(imageFile);
System.out.println("获取结果:"+result);
} catch (TesseractException | IOException e) {
e.printStackTrace();
}
}
最后
以上就是执着战斗机最近收集整理的关于使用tesseract-ocr实现验证码识别的全部内容,更多相关使用tesseract-ocr实现验证码识别内容请搜索靠谱客的其他文章。








发表评论 取消回复