package com.tzb.bigdata.spark
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount{
def main(args: Array[String]): Unit = {
//使用开发工具完成Spark WordCount的开发
//local模式
//创建SparkConf对象
//设定Spark计算框架的运行(部署)环境
//app id
val config : SparkConf = new SparkConf().setMaster("local[*]").setAppName("WordCount")
//创建Spark上下文对象
val sc = new SparkContext(config)
// println(sc)
//读取文件,将文件内容一行一行读取出来
// sc.textFile("in/word.txt") //只读一个文件
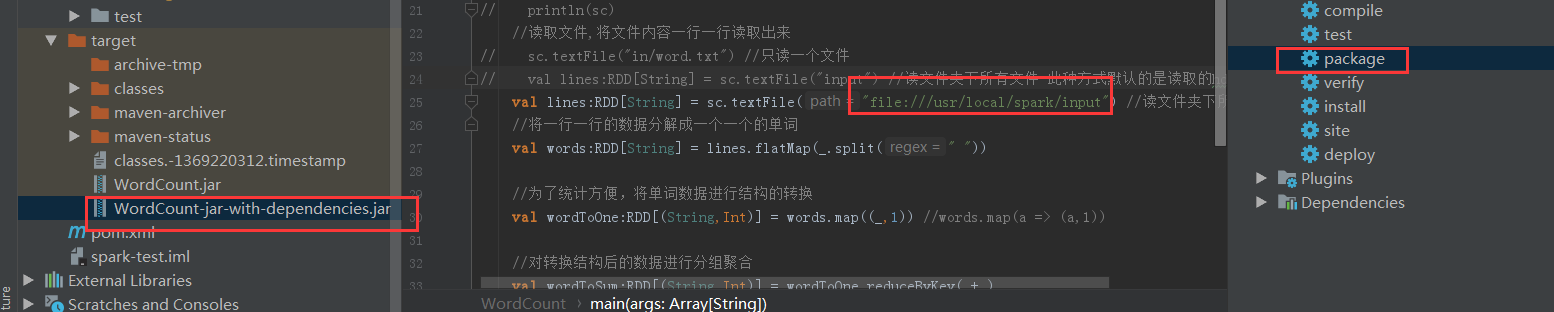
// val lines:RDD[String] = sc.textFile("input") //读文件夹下所有文件 此种方式默认的(当前部署环境)是读取的hdfs的目录
val lines:RDD[String] = sc.textFile("file:///usr/local/spark/input") //读文件夹下所有文件
//将一行一行的数据分解成一个一个的单词
val words:RDD[String] = lines.flatMap(_.split(" "))
//为了统计方便,将单词数据进行结构的转换
val wordToOne:RDD[(String,Int)] = words.map((_,1)) //words.map(a => (a,1))
//对转换结构后的数据进行分组聚合
val wordToSum:RDD[(String,Int)] = wordToOne.reduceByKey(_+_)
//将统计结果采集后打印到控制台
val result:Array[(String,Int)] = wordToSum.collect()
// println(result) //[Lscala.Tuple2;@3bbf9027 tuple元组的数组
result.foreach(println)
}
}
指定读取文件的目录为:
val lines:RDD[String] = sc.textFile("input") 报错:
20/02/02 14:31:23 INFO spark.SparkContext: Created broadcast 0 from textFile at WordCount.scala:24
Exception in thread "main" org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://sparkproject1:9000/user/root/input
at org.apache.hadoop.mapred.FileInputFormat.singleThreadedListStatus(FileInputFormat.java:285)
at org.apache.hadoop.mapred.FileInputFormat.listStatus(FileInputFormat.java:228)
at org.apache.hadoop.mapred.FileInputFormat.getSplits(FileInputFormat.java:304)
at org.apache.spark.rdd.HadoopRDD.getPartitions(HadoopRDD.scala:207)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(MapPartitionsRDD.scala:35)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:239)
at org.apache.spark.rdd.RDD$$anonfun$partitions$2.apply(RDD.scala:237)
at scala.Option.getOrElse(Option.scala:120)
at org.apache.spark.rdd.RDD.partitions(RDD.scala:237)
at org.apache.spark.rdd.MapPartitionsRDD.getPartitions(- 若是指定文件路径为 “file://…”,则读取的是本地目录;
- 未指定默认为HDFS文件系统
修改为:
val lines:RDD[String] = sc.textFile("file:///usr/local/spark/input")执行命令为:
local:
bin/spark-submit
--class com.tzb.bigdata.spark.WordCount
--master local
/usr/local/spark/examples/jars/WordCount-jar-with-dependencies.jar
yarn:
bin/spark-submit
--class com.tzb.bigdata.spark.WordCount
--master yarn
--deploy-mode client
/usr/local/spark/examples/jars/WordCount-jar-with-dependencies.jar
100
//将计算结果输出到log文件
bin/spark-submit
--class com.tzb.bigdata.spark.WordCount
--master yarn
--deploy-mode client
/usr/local/spark/examples/jars/WordCount-jar-with-dependencies.jar >/usr/local/spark/examples/jars/WordCount-jar-with-dependencies.log
100则不报错。
运行结果为:
20/02/02 14:46:48 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 1.0, whose tasks have all completed, from pool
20/02/02 14:46:48 INFO scheduler.DAGScheduler: ResultStage 1 (collect at WordCount.scala:34) finished in 0.294 s
20/02/02 14:46:49 INFO scheduler.DAGScheduler: Job 0 finished: collect at WordCount.scala:34, took 4.355099 s
(scala,2)
(spark,1)
(hadoop,1)
(hello,5)
(world,1)
20/02/02 14:46:49 INFO spark.SparkContext: Invoking stop() from shutdown hook
20/02/02 14:46:49 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHandler{/metrics/json,null}
20/02/02 14:46:49 INFO handler.ContextHandler: stopped o.s.j.s.ServletContextHan
最后
以上就是高高丝袜最近收集整理的关于spark:读取不了本地文件,Spark默认读取(当前部署环境)HDFS文件系统的全部内容,更多相关spark:读取不了本地文件内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复