Prometheus是一个开源的监控系统和告警工具,
- 支持多维数据指标, 可以给一条数据打上多个标签, 在查询时根据这些标签做过滤
- 支持PromQL, 可以非常灵活地查询和汇总需要地数据
- 支持图形界面可视化展示, 如grafana等
Prometheus架构
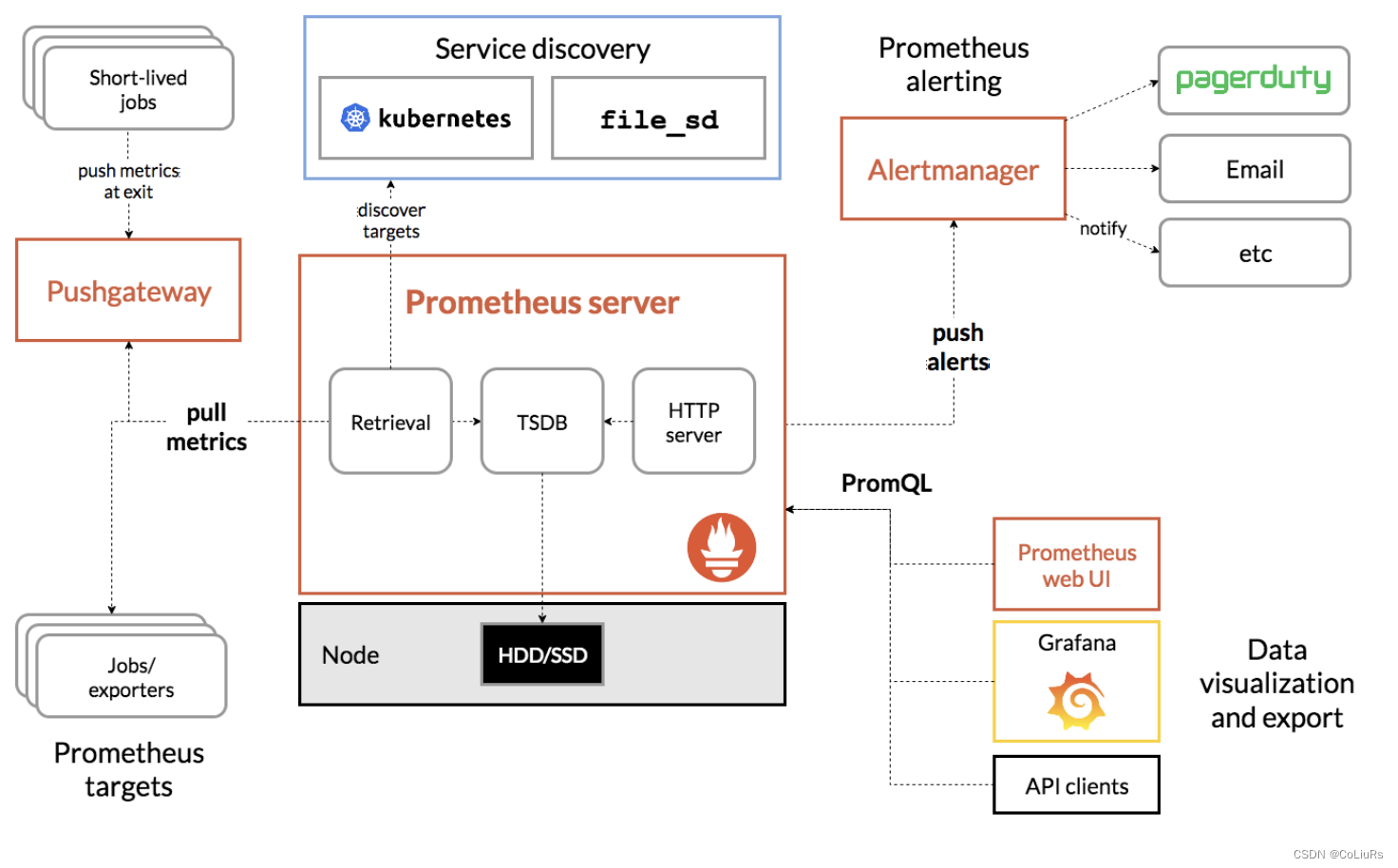
- Prometheus Server 是普罗米修斯的核心服务,提供了对外的HTTP服务以及数据存储, 它将数据存储在时序数据库中.
普罗米修斯支持主动和被动方式收集指标数据, 即我们常说的pull模式和push模式. 普罗米修斯会通过配置job/exporter的方式定时从各个exporter中拉取数据, 在push模式中, 应用通过将数据主动推送到push gateway暂存, 然后Prometheus Server再通过pull模式将数据从push gateway拉取过来并持久化到时序库中. - Alertmanager用于告警,即通过promQL定时查询判断是否到达指定的指标阈值.
- Job exporter是各种各样的数据格式转化器, 通过它将不同格式的业务数据转化为普罗米修斯的标准数据格式.
Prometheus监控业务指标
数据描述
Prometheus的时序指标数据由timestamp、metric name、label、value组成:
- timestamp是毫秒级的时间戳.
- metric name是符合正则[a-zA-Z_:][a-zA-Z0-9_:]*的字符串, 即只包含英文字母和数字及两个特殊符号_:, 不能包含横杆-这样的特殊符号.
- label是一个kv都是string类型的map.
- value是float64.
指标类型
Prometheus定义了4种不同的指标类型(metric type):Counter(计数器)、Gauge(仪表盘)、Histogram(直方图)、Summary(摘要)
Counter
Counter类型的指标其工作方式和计数器一样,只增不减(除非系统发生重置)
我们可以通过counter指标我们可以和容易的了解某个事件产生的速率变化。
例如,通过rate()函数获取HTTP请求量的增长率:
rate(http_requests_total[5m])
Counter类型的计算代码如下,就是简单的加法
func (c *counter) Inc() {
atomic.AddUint64(&c.valInt, 1)
}
Gauge
Gauge类型的指标侧重于反应系统的当前状态。因此这类指标的样本数据可增可减。Gauge类型 是动态的,所以我们用Gauge类型来描述当前系统的状态
func (g *gauge) Dec() {
g.Add(-1)
}
func (g *gauge) Add(val float64) {
for {
oldBits := atomic.LoadUint64(&g.valBits)
newBits := math.Float64bits(math.Float64frombits(oldBits) + val)
if atomic.CompareAndSwapUint64(&g.valBits, oldBits, newBits) {
return
}
}
}
Summary
Summary主用用于统计和分析样本的分布情况。比如某Http请求的响应时间大多数都在100 ms内,而个别请求的响应时间需要5s,那么这中情况下统计指标的平均值就不能反映出真实情况。而如果通过Summary指标我们能立马看响应时间的9分位数,这样的指标才是有意义的。
Summary 是采样点分位图统计。 它也有三种作用:
在客户端对于一段时间内(默认是10分钟)的每个采样点进行统计,并形成分位图。(如:正态分布一样,统计低于60分不及格的同学比例,统计低于80分的同学比例,统计低于95分的同学比例)
- 统计班上所有同学的总成绩(sum)
- 统计班上同学的考试总人数(count)
- 带有度量指标的[basename]的summary 在抓取时间序列数据展示。
- 观察时间的φ-quantiles (0 ≤ φ ≤ 1), 显示为[basename]{分位数=“[φ]”}
- [basename]_sum, 是指所有观察值的总和
- [basename]_count, 是指已观察到的事件计数值
Histogram
Histogram类型的指标同样用于统计和样本分析。与Summary类型的指标相似之处在于Histogram类型的样本同样会反应当前指标的记录的总数(以_count作为后缀)以及其值的总量(以_sum作为后缀)。
Histogram是柱状图,在Prometheus系统中的查询语言中,有三种作用:
- 对每个采样点进行统计(并不是一段时间的统计),打到各个桶(bucket)中
- 对每个采样点值累计和(sum)
- 对采样点的次数累计和(count)
度量指标名称: [basename]的柱状图, 上面三类的作用度量指标名称 - [basename]_bucket{le=“上边界”}, 这个值为小于等于上边界的所有采样点数量
- [basename]_sum
- [basename]_count
Summary 和 Histogram
Summary相比Historygram是按百分位聚合好的直方图, 适合需要知道百分比分布范围的场景, 比如对于 http请求的响应时长, Historygram是侧重在于统计小于1ms的请求有多少个, 1ms~10ms的请求有多少个, 10ms以上的请求有多少个, 而Summary在于统计20%的请求的响应时间是多少, 50%的请求的响应时间是多少, 99%的请求的响应时间是多少. Historygram是计数原始数据, 开销小, 执行查询时有对应的函数计算得到p50, p99, 而Summary是在客户端SDK测做了聚合计算得到指定的百分位, 开销更大一些.
应用指标监控例子
package main
import (
"fmt"
"net/http"
"strconv"
"time"
"github.com/gin-gonic/gin"
"github.com/prometheus/client_golang/prometheus"
"github.com/prometheus/client_golang/prometheus/promauto"
"github.com/prometheus/client_golang/prometheus/promhttp"
)
// 定义指标
var(
// Counter
requestTotal *prometheus.CounterVec
// Summary
requestLatency *prometheus.SummaryVec
// HistogramV
newRequestLatency *prometheus.HistogramVec
)
func init(){
serviceName := "promote_test"
requestTotal = promauto.NewCounterVec(
prometheus.CounterOpts{
Name: fmt.Sprintf("%s_request_total", serviceName),
Help: "Number of requests",
},
[]string{"path", "http_code"},
)
requestLatency = promauto.NewSummaryVec(
prometheus.SummaryOpts{
Name: fmt.Sprintf("%s_request_latency", serviceName),
Help: "Request latency",
},
[]string{"path", "http_code"},
)
newRequestLatency = promauto.NewHistogramVec(
prometheus.HistogramOpts{
Name: fmt.Sprintf("%s_new_request_latency", serviceName),
// 定义的每一个范围
Buckets: []float64{10, 50, 100, 200},
},
[]string{"path", "http_code"},
)
}
func main(){
httpServer()
}
// This function's name is a must. App Engine uses it to drive the requests properly.
func httpServer() {
// Starts a new Gin instance with no middle-ware
server := gin.New()
server.Use(gin.Recovery(), gin.Logger(),metricsMiddlewares())
// Define your handlers
server.GET("/", func(c *gin.Context) {
c.String(http.StatusOK, "Hello World!")
})
server.GET("/ping", func(c *gin.Context) {
c.String(http.StatusOK, "pong")
})
server.GET("/metrics", metrics)
// Handle all requests using net/http
http.Handle("/", server)
err := server.Run("127.0.0.1:8056")
if err!=nil{
panic(err)
}
}
// 暴露指标
func metrics(c *gin.Context) {
h := promhttp.Handler()
h.ServeHTTP(c.Writer, c.Request)
}
// 记录指标
func metricsMiddlewares() gin.HandlerFunc{
return func(c *gin.Context) {
start := time.Now()
c.Next()
duration := float64(time.Since(start)) / float64(time.Second)
path := c.Request.URL.Path
// 请求数加
requestTotal.With(prometheus.Labels{
"path": path,
"http_code": strconv.Itoa(c.Writer.Status()),
}).Inc()
// SummaryVec: 记录本次请求处理时间
requestLatency.With(prometheus.Labels{
"path": path,
"http_code": strconv.Itoa(c.Writer.Status()),
}).Observe(duration)
// HistogramVec: 记录本次请求处理时间
newRequestLatency.With(prometheus.Labels{
"path": path,
"http_code": strconv.Itoa(c.Writer.Status()),
}).Observe(duration)
}
}
结果
# HELP promote_test_new_request_latency
# TYPE promote_test_new_request_latency histogram
promote_test_new_request_latency_bucket{http_code="200",path="/ping",le="10"} 5
promote_test_new_request_latency_bucket{http_code="200",path="/ping",le="50"} 5
promote_test_new_request_latency_bucket{http_code="200",path="/ping",le="100"} 5
promote_test_new_request_latency_bucket{http_code="200",path="/ping",le="200"} 5
promote_test_new_request_latency_bucket{http_code="200",path="/ping",le="+Inf"} 5
promote_test_new_request_latency_sum{http_code="200",path="/ping"} 6.0337e-05
promote_test_new_request_latency_count{http_code="200",path="/ping"} 5
# HELP promote_test_request_latency Request latency
# TYPE promote_test_request_latency summary
promote_test_request_latency_sum{http_code="200",path="/ping"} 6.0337e-05
promote_test_request_latency_count{http_code="200",path="/ping"} 5
# HELP promote_test_request_total Number of requests
# TYPE promote_test_request_total counter
promote_test_request_total{http_code="200",path="/ping"} 5
文档参考
- prometheus的summary和histogram指标的简单理解
- https://prometheus.io/docs/practices/histograms/
最后
以上就是贪玩小鸽子最近收集整理的关于Prometheus监控业务指标Prometheus架构Prometheus监控业务指标文档参考的全部内容,更多相关Prometheus监控业务指标Prometheus架构Prometheus监控业务指标文档参考内容请搜索靠谱客的其他文章。








发表评论 取消回复