文件下载地址:
链接: https://pan.baidu.com/s/1H3v4tej7N3DjvjF6uoy5eA 提取码: 4b7u
"""
事件预测 案例
"""
import numpy as np
import sklearn.preprocessing as sp
import sklearn.model_selection as ms
import sklearn.svm as svm
import sklearn.metrics as sm
import sklearn.naive_bayes as nb
class DigitEncoder:
"""
数字与字符串互转
"""
def fit_transform(self, y):
return y.astype(int)
def transform(self, y):
return y.astype(int)
def inverse_transform(self, y):
return y.astype(str)
# 读取数据集 整理数据集
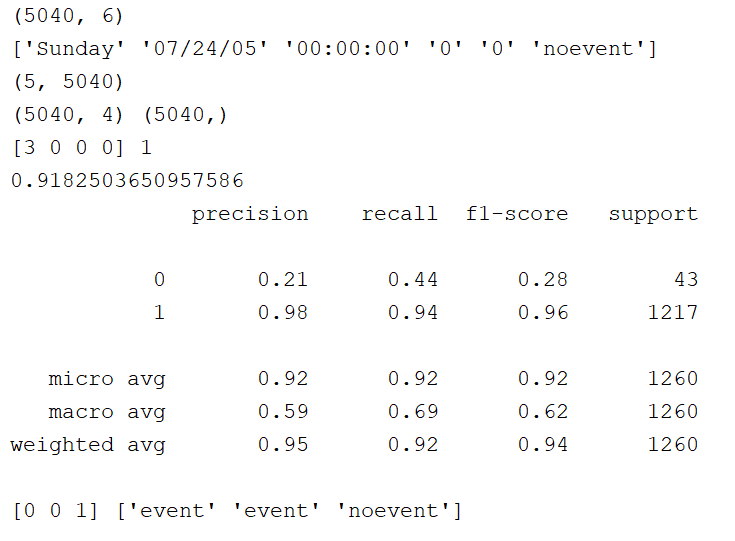
lines = np.loadtxt(r".event.txt", delimiter=',', dtype='str')
print(lines.shape)
print(lines[0])
# 读取数据
# 删除第二列
lines_T = np.delete(lines.T, 1, axis=0)
print(lines_T.shape)
lines_T = np.array(lines_T)
# 整理样本空间 并编码 (对列执行标签编码)
train_x, train_y = [], []
encoders = [] # 标签编码数组
for index, row in enumerate(lines_T):
rowStr = row[index]
if rowStr.isdigit(): # 是否为数字类型
encoder = DigitEncoder()
else:
encoder = sp.LabelEncoder() # 标签编码
if index < (len(lines_T) - 1): # 训练样本 X
train_x.append(encoder.fit_transform(row))
else:
train_y = encoder.fit_transform(row) # 训练样本结果 Y
encoders.append(encoder)
train_x = np.array(train_x).T # 转置
train_y = np.array(train_y)
print(train_x.shape, train_y.shape)
print(train_x[0], train_y[0])
train_x, test_x, train_y, test_y
= ms.train_test_split(train_x, train_y, test_size=0.25, random_state=7)
# 选择模型 训练模型
model = nb.GaussianNB()
# model = svm.SVC(kernel="rbf", degree=3, class_weight="balanced")
# 交叉验证
print(ms.cross_val_score(model, train_x, train_y, cv=3, scoring='accuracy').mean())
model.fit(train_x, train_y)
# 预测
prd_test_y = model.predict(test_x)
# 打印分类报告
print(sm.classification_report(test_y, prd_test_y))
# 真实数据预测
data = [['Tuesday', '13:30:00', '21', '23'],
['Tuesday', '14:30:00', '63', '62'],
['Tuesday', '01:30:00', '3', '2']]
data = np.array(data).T
x = []
for row in range(len(data)):
encoder = encoders[row]
x.append(encoder.transform(data[row]))
x = np.array(x).T
prd_y = model.predict(x)
print(prd_y, encoders[-1].inverse_transform(prd_y))
最后
以上就是无聊香菇最近收集整理的关于python sklearn 分类案例:事件预测的全部内容,更多相关python内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复