我是靠谱客的博主 爱撒娇小馒头,这篇文章主要介绍【已解决】关于IDEA中 Driver 出现Exception in thread ";main"; java.lang.NullPointerException问题,现在分享给大家,希望可以做个参考。
在学习hive过程中,按照mapreduce编程规范,分别编写Mapper,Reducer,Driver,在编写Driver后运行报错了,花了两天,找到了解决方案(裂开.JPG)。
代码:
package com.miao;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class WCDriver {
public static void main(String[] args) throws Exception {
// 1 创建一个配置对象
Configuration conf = new Configuration();
// 2 通过配置对象获取一个job对象
Job job = Job.getInstance(conf);
// 3 设置job的jar包
job.setJarByClass(WCDriver.class);
// 4 设置job的mapper类,reduce类
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
// 5 设置mapper的keyout和valueout
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 6 设置最终输出数据的keyout和valueout
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 7 设置输入数据的路径和输出数据的路径---
FileInputFormat.setInputPaths(job,new Path(args[0])); // 也可以写死路径
//注意输出目录不能事先存在,必须设置一个不存在的目录,框架会自行创建,否则就会报错
FileOutputFormat.setOutputPath(job,new Path(args[1])); // 也可以写死路径
// 8 向yarn或者本地yarn模拟器提交任务
boolean res = job.waitForCompletion(true);
System.out.println("是否成功:"+res);
}
}
报错:
Exception in thread "main" java.lang.NullPointerException
原因:
在设置路径时那儿没有指定路径,或者指定了已经存在的路径。
解决:
1.点击此处去设置传输文件的保存路径
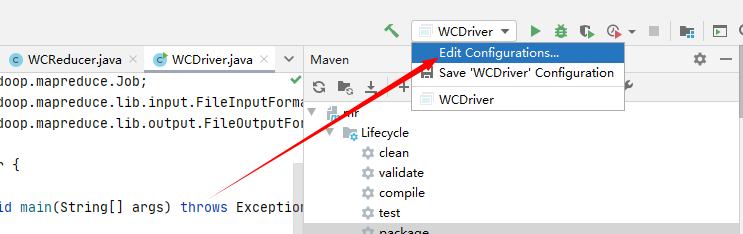
2.编辑路径(前一个为原本文本文档的路径,第二个为IDEA上要传的文件所要传到电脑本机的路径,我这里选择同样传到E盘的将会被IDEA自动新建的名为abc的文件夹里)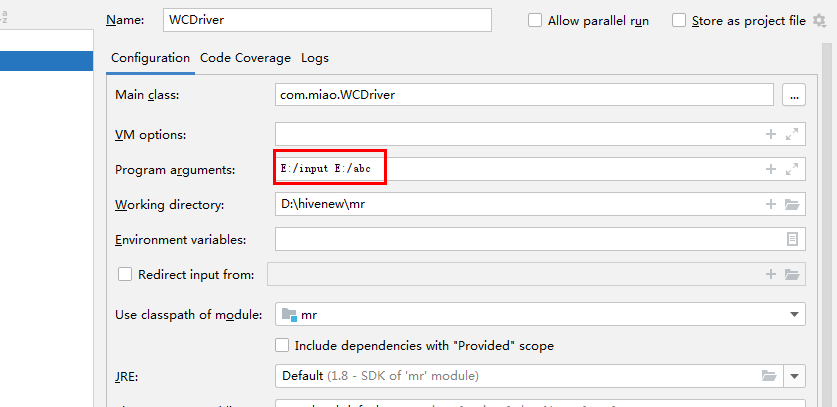
3.然后运行你的Driver.java,就会成功了。(如果上传的文件夹路径是电脑存在的,依旧会报错,所以设置路径时一定需要取一个电脑里没有的文件夹名字!)
orz 报错时搜遍全网,找了两天都没看到解决这个的帖子,记录一下。
当然我是学这个的菜逼,还是很多不懂。。
最后
以上就是爱撒娇小馒头最近收集整理的关于【已解决】关于IDEA中 Driver 出现Exception in thread ";main"; java.lang.NullPointerException问题的全部内容,更多相关【已解决】关于IDEA中内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复