本篇博文纯粹是作为一个记录,不会讲得太清楚,但是本人亲自运行验证,损失率达到了0.002,还比较满意,毕竟这是我的第一个机器识别程序。
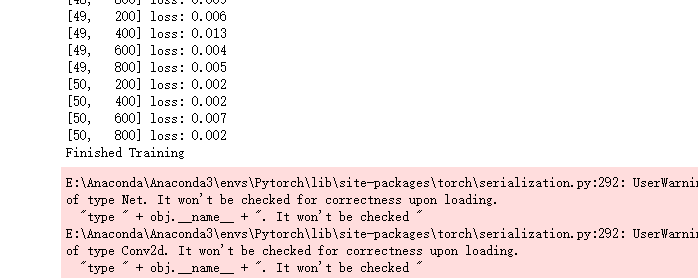
这是训练的损失率
先看看项目目录:
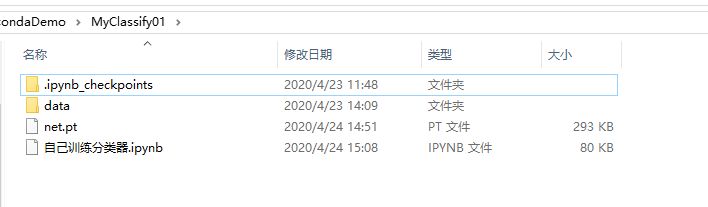
其中net.pt是训练后保存的模型数据,data文件夹下放有训练用的数据和测试数据
训练的数据我是从这里下载的训练数据下载
接下来是训练用到的代码:
import torch
import torchvision
import torchvision.transforms as transforms
import torch.nn as nn
import torch.nn.functional as F
from torch.autograd import Variable
import torch.optim as optim
import matplotlib.pyplot as plt
import numpy as np
def loadtraindata():
# 路径
path = "data/train"
trainset = torchvision.datasets.ImageFolder(path,transform=transforms.Compose([
# 将图片缩放到指定大小(h,w)或者保持长宽比并缩放最短的边到int大小
transforms.Resize((32, 32)),
transforms.CenterCrop(32),
transforms.ToTensor()])
)
trainloader = torch.utils.data.DataLoader(trainset, batch_size=4,shuffle=True, num_workers=2)
return trainloader
# 定义网络,继承torch.nn.Module
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
# 卷积层
self.conv1 = nn.Conv2d(3, 6, 5)
# 池化层
self.pool = nn.MaxPool2d(2, 2)
# 卷积层
self.conv2 = nn.Conv2d(6, 16, 5)
# 全连接层
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
# 2个输出
self.fc3 = nn.Linear(84, 2)
# 前向传播
def forward(self, x):
# F就是torch.nn.functional
x = self.pool(F.relu(self.conv1(x)))
x = self.pool(F.relu(self.conv2(x)))
#view()函数用来改变tensor的形状,
#例如将2行3列的tensor变为1行6列,其中-1表示会自适应的调整剩余的维度
#在CNN中卷积或者池化之后需要连接全连接层,所以需要把多维度的tensor展平成一维
x = x.view(x.size(0), -1)
# 从卷基层到全连接层的维度转换
x = F.relu(self.fc1(x))
x = F.relu(self.fc2(x))
x = self.fc3(x)
return x
def trainandsave():
trainloader = loadtraindata()
# 神经网络结构
net = Net()
# 优化器,学习率为0.001
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9)
# 损失函数也可以自己定义,我们这里用的交叉熵损失函数
criterion = nn.CrossEntropyLoss()
# 训练部分,训练的数据量为5个epoch,每个epoch为一个循环
for epoch in range(50):
# 每个epoch要训练所有的图片,每训练完成200张便打印一下训练的效果(loss值)
# 定义一个变量方便我们对loss进行输出
running_loss = 0.0
# 这里我们遇到了第一步中出现的trailoader,代码传入数据
for i, data in enumerate(trainloader, 0):
# enumerate是python的内置函数,既获得索引也获得数据
# data是从enumerate返回的data,包含数据和标签信息,分别赋值给inputs和labels
inputs, labels = data
# 转换数据格式用Variable
inputs, labels = Variable(inputs), Variable(labels)
# 梯度置零,因为反向传播过程中梯度会累加上一次循环的梯度
optimizer.zero_grad()
# forward + backward + optimize,把数据输进CNN网络net
outputs = net(inputs)
# 计算损失值
loss = criterion(outputs, labels)
# loss反向传播
loss.backward()
# 反向传播后参数更新
optimizer.step()
# loss累加
running_loss += loss.item()
if i % 200 == 199:
# 然后再除以200,就得到这两百次的平均损失值
print('[%d, %5d] loss: %.3f' % (epoch + 1, i + 1, running_loss / 200))
# 这一个200次结束后,就把running_loss归零,下一个200次继续使用
running_loss = 0.0
print('Finished Training')
# 保存神经网络
netScript = torch.jit.script(net)
# 保存整个神经网络的结构和模型参数
torch.jit.save(netScript, 'net.pt')
# 只保存神经网络的模型参数
#torch.jit.save(net.state_dict(), 'net_params.pt')
trainandsave()
这里我们要特别提到向前传播中 x = x.view(x.size(0), -1) 的作用,该方法可以把多维的Tensor数据展成一维的数组,这样才能把卷积池化层连接到全连接层。
此外,训练完成以后要把训练后的模型保存在本地,为了接下来我们可以把模型迁移到Android设备上,这里使用的方法如下:
# 保存神经网络
netScript = torch.jit.script(net)
# 保存整个神经网络的结构和模型参数
torch.jit.save(netScript, 'net.pt')
虽然可以用 torch.save()保存整个网络模型,但是这样是无法再手机上使用的,必须像上面把完整的代码保存下来才能够使用。(两者之间的区别目前我还不是很清楚)
训练完了就可以用测试代码进行测试,如下:
classes = ('男','女')
mbatch_size = 17
def loadtestdata():
path = "data/test"
testset = torchvision.datasets.ImageFolder(path,
transform=transforms.Compose([
transforms.Resize((32, 32)),
transforms.ToTensor()])
)
testloader = torch.utils.data.DataLoader(testset, batch_size=mbatch_size,
shuffle=True, num_workers=2)
return testloader
def reload_net():
trainednet = torch.jit.load('net.pt')
return trainednet
def imshow(img):
img = img / 2 + 0.5
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
def test():
testloader = loadtestdata()
net = reload_net()
dataiter = iter(testloader)
images, labels = dataiter.next()
# nrow是每行显示的图片数量,缺省值为8
imshow(torchvision.utils.make_grid(images,nrow=4))
# 打印前25个GT(test集里图片的标签)
print('真实值: ', " ".join('%5s' % classes[labels[j]] for j in range(mbatch_size)))
outputs = net(Variable(images))
_, predicted = torch.max(outputs.data, 1)
# 预测值
print('预测值: ', " ".join('%5s' % classes[predicted[j]] for j in range(mbatch_size)))
test()
贴一张我测试的结果图:

基本全部预测正确了,如果你想直接使用模型可以前往这里下载https://download.csdn.net/download/zhangdongren/12358579
下一篇文章《Android设备上部署Pytorch,实现性别识别,男女分类》
我们将介绍如何把训练出来的模型迁移到Android设备中,实现拍照识别性别。
最后
以上就是愤怒宝马最近收集整理的关于Pytorch实现性别识别,男女分类的全部内容,更多相关Pytorch实现性别识别内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复