@[TOC] 第三章 paddlepaddle实践
第三章学习笔记
# 定义reader
# 定义buf_size和batch_size大小
buf_size = 1000
batch_size = 256
# 训练集reader
train_reader = fluid.io.batch(
reader=paddle.reader.shuffle(
reader=read_data(TRAIN_SET),
buf_size=buf_size
),
batch_size=batch_size
)
# 测试集reader
test_reader = fluid.io.batch(
reader=paddle.reader.shuffle(
reader=read_data(TEST_SET),
buf_size=buf_size
),
batch_size=batch_size
)
# 定义飞桨动态图工作环境
with fluid.dygraph.guard():
# 实例化模型
# Softmax分类器
model = SoftmaxRegression('catornocat')
# 开启模型训练模式
model.train()
# 使用Adam优化器
# 学习率为0.01
opt = fluid.optimizer.Adam(learning_rate=0.01, parameter_list=model.parameters())
# 迭代次数设为200
EPOCH_NUM = 200
这里的EPOCH_NUM是经历了多少代,
主要是下面这段代码自己琢磨了很长时间
首先贴张图
这张图我是从别的博客上面的截图,
博客接链,可以看下这篇文章

上面的代码定义了EPOCH_NUM=200
buf_size=1000,这个可以理解为开辟的内存空间,
batch_size=256,
看了上面的截图,就能理解这个batch_size的意思了,这个意思是所有的训练集样本分批处理,分了多少批呢,不知道,只知道一批里面包含的样本数量是256个,也就是256张图片,所以没必要定义多少批,只是定义一批是多少就行,最后一批是多少张图片就看训练集有多少张图了
比如:训练集有257张图片,设置的batch_size=256,那么就分成了两批,第一批是256张图,第二批是1张图,
这本书第三章paddle实现里面的代码,猫的训练集有209张图片,所以就分了一批,
import paddle
import paddle.fluid as fluid
from paddle.fluid.dygraph import Linear
from the_functions import *
from the_third_regression import *
import numpy as np
# 按间距中的绿色按钮以运行脚本。
if __name__ == '__main__':
#加载数据
np.set_printoptions(threshold=np.inf)
TRAIN_SET,TEST_SET,DATA_DIM,CLASSES=get_data()
#print(TRAIN_SET)
#定义reader
#定义内存大小和批次数量
buf_size=500
#批次的尺寸是256,也就是一批里面又256条数据,但是这个数据集一共209条数据,所以就一个批次
batch_size=120
#训练集reader生成器
#这个可以理解为输入输出io的batch(训练集数据,批次大小为256)把1000条数据打乱,再256一批的训练
train_reader = fluid.io.batch(
reader=paddle.reader.shuffle(
reader=read_data(TRAIN_SET),
buf_size=buf_size
),
batch_size=batch_size
)
print(train_reader)
print(type(train_reader))
# 测试集reader,测试集数据生成器
test_reader = fluid.io.batch(
reader=paddle.reader.shuffle(
reader=read_data(TEST_SET),
buf_size=buf_size
),
batch_size=batch_size
)
#定义飞桨动态图工作环境
with fluid.dygraph.guard():
model=SoftmaxRegression('catornocat')
model.train()
#定义优化器Adam
opt=fluid.optimizer.Adam(learning_rate=0.01,parameter_list=model.parameters())
EPOCH_NUM=3
with fluid.dygraph.guard():
costs=[]
print('train_reader的类型是:',type(train_reader()))
for pass_num in range(EPOCH_NUM):
print('第{}次'.format(pass_num))
#print(pass_num)
#定义内层循环,训练集大概是500条数据,分成了两批
for batch_id,data in enumerate(train_reader()):
#调整数据shape使之适合模型
print('batch_id为{},'.format(batch_id))
images=np.array([x[0].reshape(DATA_DIM) for x in data],np.float32)
print(images.shape)
比如上面这个代码,我把批的大小改成了120,经历代数是3,打印出来第几次 批次号如下图
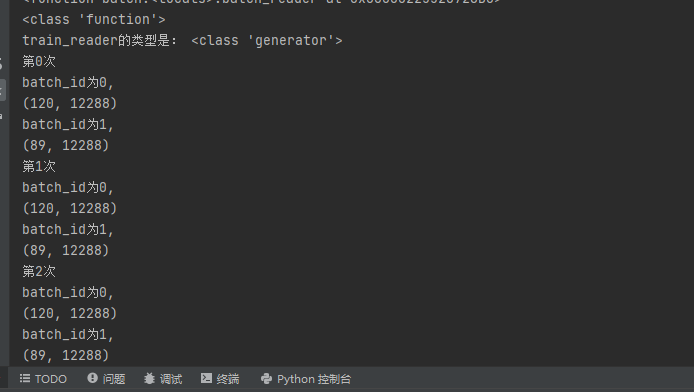
可以看出每个所有数据的大循环都是209条数据,120一批次,分成了两个批次,一个是120条数据,第二批次是89条数据,
with fluid.dygraph.guard():
# 记录每次的损失值,用于绘图
costs = []
# 定义外层循环
for pass_num in range(EPOCH_NUM):
# 定义内层循环
for batch_id,data in enumerate(train_reader()):
# 调整数据shape使之适合模型
images = np.array([x[0].reshape(DATA_DIM) for x in data],np.float32)
labels = np.array([x[1] for x in data]).astype('int64').reshape(-1,1)
# 将numpy数据转为飞桨动态图variable形式
image = fluid.dygraph.to_variable(images)
label = fluid.dygraph.to_variable(labels)
# 前向计算
predict = model(image)
# 计算损失
# 使用交叉熵损失函数
loss = fluid.layers.cross_entropy(predict,label)
avg_loss = fluid.layers.mean(loss)
# 计算精度
# acc = fluid.layers.accuracy(predict,label)
# 绘图
costs.append(avg_loss.numpy()[0])
draw_line(costs, 0.01)
# 反向传播
avg_loss.backward()
# 最小化loss,更新参数
opt.minimize(avg_loss)
# 清除梯度
model.clear_gradients()
# 保存模型文件到指定路径
fluid.save_dygraph(model.state_dict(), 'catornocat')
最后
以上就是小巧黑米最近收集整理的关于飞桨paddlepaddle深度学习实战——学习笔记(第三章飞桨实践)第三章学习笔记的全部内容,更多相关飞桨paddlepaddle深度学习实战——学习笔记(第三章飞桨实践)第三章学习笔记内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复