SoftmaxWithLossLayer 层分析
SoftmaxWithLoss 由两部分组成: 1. softmax 2. loss
Softmax 层
假设batch_size是网络的批处理训练样本数,label_num是样本的类别数(比如Alexnet网络的识别10个类别),softmax层输入大小batch_size*label_num, 网络的期望输出label_num*1,下面开始讲解如何计算softmax:
如果某图片k,其标签是y,输入为向量z,那么经过softmax层,输出为a, 公式如下:
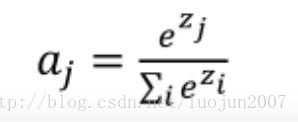
步骤:
- 计算batch_size*label_num数据中的最大值 max_value
- batch_size*label_num数据减去max_value ,batch_size*label_num - max_value。这么做的原因是将数据的分布范围拉宽,便于后面步骤的类别置信度计算
- 计算 exp(z),将上一步的数据映射(*, 1)的值区间
- 计算
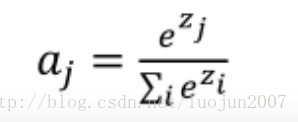 ,得到每个batch_size中label_num个类别的置信概率。
,得到每个batch_size中label_num个类别的置信概率。
Loss 计算
图片i的真实标签假设是0~n-1中的第10类,那么训练的目标是让这类别的输出置信概率为1是最理想的情况。在train的过程中这类的输出置信是 pro[i][10](i是batch_size:指的是第几张图),经过softmax层,可以拿到 大小为batch_size的真实概率数据。然后对batch_size个数据求log,得到熵,然后最小化熵,就是网络训练的目标
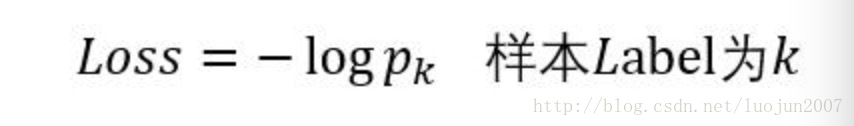
代码实现
本文代码与caffe代码输出完全一致
头文件
#ifndef CAFFE_MY_LOSS_LAYER_HPP_
#define CAFFE_MY_LOSS_LAYER_HPP_
#include <vector>
#include "caffe/blob.hpp"
#include "caffe/layer.hpp"
#include "caffe/proto/caffe.pb.h"
#include "caffe/layers/loss_layer.hpp"
#include "caffe/layers/softmax_layer.hpp"
namespace caffe {
template <typename Dtype>
class MyLossLayer : public LossLayer<Dtype> {
public:
explicit MyLossLayer(const LayerParameter& param)
: LossLayer<Dtype>(param) {}
virtual void LayerSetUp(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Reshape(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual inline const char* type() const { return "MyLoss"; }
virtual inline int ExactNumTopBlobs() const { return 1; }
virtual inline int MinTopBlobs() const { return 1; }
virtual inline int MaxTopBlobs() const { return 2; }
protected:
virtual void Forward_cpu(const vector<Blob<Dtype>*>& bottom,
const vector<Blob<Dtype>*>& top);
virtual void Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom);
vector<vector<Dtype> > prob_; //保存置信度
int label_num; //标签个数
int batch_size; //批大小
};
} // namespace caffe
#endif // CAFFE_MY_LOSS_LAYER_HPP_
源文件,正反向传播
#include <algorithm>
#include <cfloat>
#include <vector>
#include "caffe/layers/my_loss_layer.hpp"
#include "caffe/util/math_functions.hpp"
using namespace std;
namespace caffe {
template <typename Dtype>
void MyLossLayer<Dtype>::LayerSetUp(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
LossLayer<Dtype>::LayerSetUp(bottom, top);
}
template <typename Dtype>
void MyLossLayer<Dtype>::Reshape(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
LossLayer<Dtype>::Reshape(bottom, top);
this->label_num=bottom[0]->channels(); //标签数 ,比如mnist为10
this->batch_size=bottom[0]->num(); //batch大小,比如mnist 一次输入64个
this->prob_=vector<vector<Dtype> >(batch_size,vector<Dtype>(label_num,Dtype(0))); //置信度数组 64*10
}
template <typename Dtype>
void MyLossLayer<Dtype>::Forward_cpu(
const vector<Blob<Dtype>*>& bottom, const vector<Blob<Dtype>*>& top) {
//为了避免数值问题,计算prob_时,先减最大值,再按照softmax公式计算各置信度
for(int i=0;i<batch_size;++i){
//求最大值,并减最大值
Dtype mmax=-10000000;
for(int j=0;j<label_num;++j)
mmax=max<Dtype>(mmax,bottom[0]->data_at(i,j,0,0));
for(int j=0;j<label_num;++j)
prob_[i][j]=bottom[0]->data_at(i,j,0,0)-mmax;
Dtype sum=0.0; //求出分母
for(int j=0;j<label_num;++j)
sum+=exp(prob_[i][j]);
for(int j=0;j<label_num;++j) //计算各个置信度
prob_[i][j]=exp(prob_[i][j])/sum;
}
//根据计算好的置信度,计算loss
Dtype loss=0.0;
const Dtype* label = bottom[1]->cpu_data(); //标签数组 64
for(int i=0;i<batch_size;++i){
int realLabel=static_cast<int>(label[i]); //图片i的真实标签
Dtype tmpProb=prob_[i][realLabel]; //属于真实标签的置信度
loss -= log(max<Dtype>(tmpProb,Dtype(FLT_MIN))); //防止数据溢出问题
}
top[0]->mutable_cpu_data()[0] = loss / batch_size;
}
//反向传播,计算梯度
template <typename Dtype>
void MyLossLayer<Dtype>::Backward_cpu(const vector<Blob<Dtype>*>& top,
const vector<bool>& propagate_down, const vector<Blob<Dtype>*>& bottom) {
if (propagate_down[0]) {
Dtype* bottom_diff = bottom[0]->mutable_cpu_diff();
const Dtype* label = bottom[1]->cpu_data(); //标签
for(int i=0;i<batch_size;++i){
int realLabel=static_cast<int>(label[i]); //图片i的真实标签
for(int j=0;j<label_num;++j){
int offset=bottom[0]->offset(i,j);
if(j==realLabel) //按照公式,如果分量就是真实标签,直接在置信度上减去1,就得到该分量的梯度
bottom_diff[offset]=prob_[i][j]-1;
else //否则,梯度等于置信度
bottom_diff[offset]=prob_[i][j];
}
}
for(int i=0;i<bottom[0]->count();++i) //梯度归一化,除以batch大小
bottom_diff[i]/=batch_size;
}
}
INSTANTIATE_CLASS(MyLossLayer);
REGISTER_LAYER_CLASS(MyLoss);
} // namespace caffe
编译后,运行mnist网络
layer {
name: "my_loss"
type: "MyLoss"
bottom: "ip2"
bottom: "label"
top: "my_loss"
}最后结果:
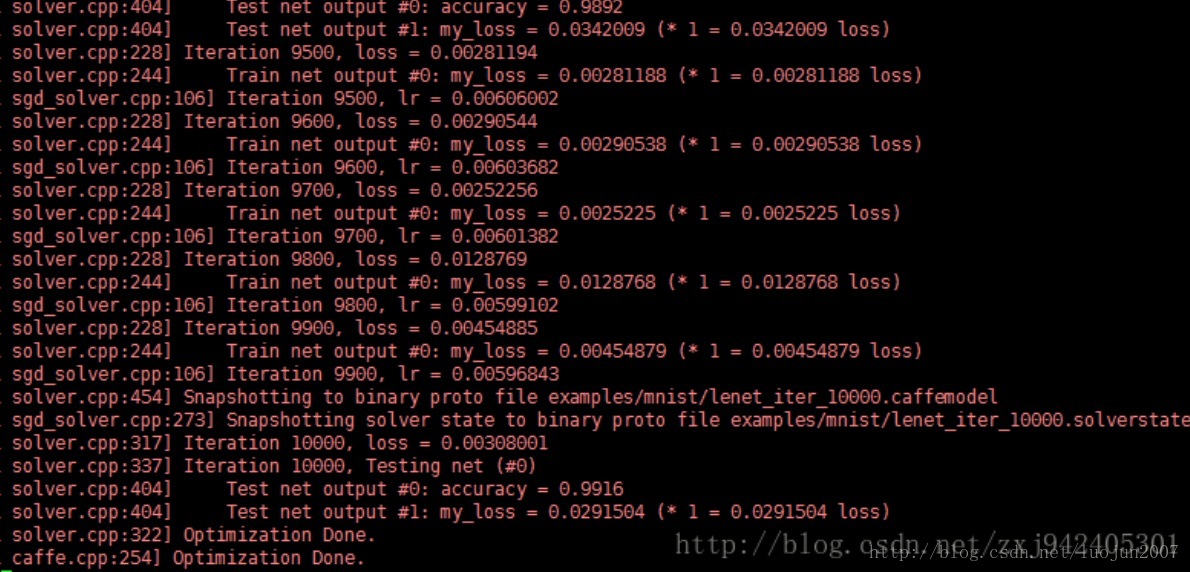
最后
以上就是害怕萝莉最近收集整理的关于SoftmaxWithLossLayer 详细讲解Softmax 层Loss 计算代码实现的全部内容,更多相关SoftmaxWithLossLayer内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复