ClickHouse基本语法
- 一、基本语法
- 1、DDL基础
- (1)建表指定引擎
- (2)复制表结构建表
- (2)查看建表语句
- (3)查看表结构
- (4)修改表结构
- (5)移动表
- (6)查看数据库下的表
- (7)设置表属性
- 2、DML基础
- (1)插入数据
- (2)更新删除数据
- 3、分区表操作
- 二、查询语法
- 1、with
- (1)定义变量
- (2)调用函数
- (3)子查询
- 2、from 表函数
- (1)from mysql
- (2)from hdfs
- (3)from remote
- (4)from file
- (5)from numbers
- 3、array join
- 4、关联查询
- (一)连接精度
- (1)all
- (2)any
- (3)asof
- 5、with模型
- 三、函数
- 1、 普通函数
- (1)类型转换函数
- (2)日期函数
- (3)条件函数
- (4)其他
- 四、分布式
- 1、环境搭建
- 2、副本概念
- 3、分片概念
- 4、配置zookeeper
- 5、创建副本表
- (1)一个分片 , 多个副本表
- (2)两个分片 , 一个分片有副本一个分片没有副本
- 6、分布式引擎
- (1)配置分片和副本集群
- (2)创建分布式表
- 7、分布式DDL
- 8、分布式协同原理
- (1)insert原理
- (2)Merge原理
- (3)mutation原理
- (4)alter原理
- 五、应用案例
一、基本语法
1、DDL基础
(1)建表指定引擎
CREATE TABLE tb_test1
(
`id` Int8,
`name` String
)
ENGINE = Memory ;
(2)复制表结构建表
不指定引擎,则新表引擎与旧表引擎一致
create table log3 as log2 ;
-- create table tb_name like tb_ds ; -- 不支持
指定引擎
create table tb_log as agg_table engine=TinyLog;
(2)查看建表语句
show create table test_alter1 ;
(3)查看表结构
desc tb_test1 ;
(4)修改表结构
目前只有MergeTree、Merge和Distributed这三类表引擎支持 ALTER修改,所以在进行alter操作的时候注意表的引擎!
mergetree 排序字段、分区字段不能改
添加字段
alter table tb_test2 add column age UInt8 COMMENT '注释';
alter table tb_test2 add column gender String after name ;
删除字段
alter table tb_test2 drop column age ;
修改字段的数据类型
--default 是设置默认值
alter table tb_test2 modify column gender UInt8 default 0 ;
修改 / 添加字段的注释
-- 内部使用的编码默认是UTF8
alter table tb_test2 comment column name '用户名' ;
(5)移动表
在Linux系统中,mv命令的本意是将一个文件从原始位置A移动到目标位置B,但是如果位 置A与位置B相同,则可以变相实现重命名的作用。ClickHouse的RENAME查询就与之有着异曲同工之妙,RENAME语句的完整语法如下所示:
-- 修改表名
rename table tb_test1 to t1 ;
-- 修改多张表名
rename table tb_test2 to t2 , t1 to tt1 ;
-- 移动表到另一数据库中
rename table t2 to test1.t ;
-- 查看数据库下的所有的表
show tables ;
show tables from db_name ;
(6)查看数据库下的表
-- 查看所有的表
show tables ;
-- 查看指定数据库下的所有的表
show tables from db_name ;
show tables in db_name ;
(7)设置表属性
-- 设置列的默认值
create table tb_test3(
id Int8 ,
name String comment '用户名' ,
role String comment '角色' default 'VIP'
)engine = Log ;
┌─name─┬─type───┬─default_type─┬─default_expression─┬
│ id │ Int8 │ │ │
│ name │ String │ │ │
│ role │ String │ DEFAULT │ 'VIP' │
└──────┴────────┴──────────────┴────────────────────┴
insert into tb_test3 (id , name) values(1,'HANGGE') ;
SELECT *
FROM tb_test3 ;
┌─id─┬─name───┬─role─┐
│ 1 │ HANGGE │ VIP │
└────┴────────┴──────┘
2、DML基础
(1)插入数据
插入数据有三种方式:
- 使用VALUES格式的常规语法
INSERT INTO [db.]table [(c1, c2, c3…)] VALUES (v11, v12, v13…), (v21, v22, v23…), … - 将本地数据导入到表中
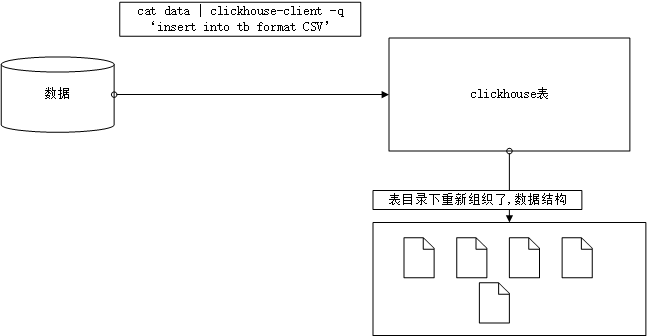
静态数据: cat user.txt
1,zss,23,BJ,M
2,lss,33,NJ,M
3,ww,21,SH,F
create table test_load1(
id UInt8 ,
name String ,
age UInt8 ,
city String ,
gender String
)engine=Log ;
-- 将数据导入到表中
cat user.txt | clickhouse-client -q 'insert into default.test_load1 format CSV' --password
clickhouse-client -q 'insert into default.test_load1 format CSV' < user.txt
上面的两种方式都可以将数据导入到表中
-- 我们还可以执行数据行属性的分割符
clickhouse-client --format_csv_delimiter='-' -q 'insert into default.test_load1 format CSV' < user.txt
- 查询插入
INSERT INTO [db.]table [(c1, c2, c3…)] SELECT …
create table log3 as log2 ;
Insert into log3 select * from log2 ;
create table tb_res engine = Log as select * from tb_ds ;
-- create table tb_name like tb_ds ; -- 不支持
ClickHouse内部所有的数据操作都是面向Block数据块的,所以INSERT查询最终会将数据转换为Block数据块。也正因如此,INSERT语句在单个数据块的写入过程中是具有原子性的。在默认的情况下,每个数据块最多可以写入1048576行数据(由max_insert_block_size参数控制)。也就是说,如果一条INSERT语句写入的数据少于max_insert_block_size行,那么这批数据的写入是具有原子性的,即要么全部成功,要么全部失败。需要注意的是,只有在ClickHouse服务端处理数据的时候才具有这种原子写入的特性,例如使用JDBC或者HTTP接口时。因为max_insert_block_size参数在使用CLI命令行或者INSERT SELECT子句写入时是不生效的。
(2)更新删除数据
[一般不会操作] olap 查询多
如果是MergeTree引擎的表
可以删除分区 重新导入
可以根据条件删除数据 根据条件更新数据 alter table delete/ update where
(mutation操作)
可以使用CK中提供的特殊的引擎实现数据的删除和更新操作 CollapsingMergeTree 、VersionedCollapsingMergeTree
ClickHouse提供了DELETE和UPDATE的能力,这类操作被称为Mutation查询,它可以看作ALTER语句的变种。虽然Mutation能最终实现修改和删除,但不能完全以通常意义上的UPDATE和DELETE来理解,我们必须清醒地认识到它的不同:首先,Mutation语句是一种“很重”的操作,更适用于批量数据的修改和删除;其次,它不支持事务,一旦语句被提交执行,就会立刻对现有数据产生影响,无法回滚;最后, Mutation语句的执行是一个异步的后台过程,语句被提交之后就会立即返回。所以这并不代表具体逻辑已经执行完毕,它的具体执行进度需要通过system.mutations系统表查询。注意数据的修改和删除操作是使用MergeTree家族引擎:
只有MergeTree引擎的数据才能修改
删除整个分区
alter table test_muta drop partition 'SH' ;
条件删除数据
alter table test_muta delete where id=3 ; -- 一定加条件
条件更新数据
ALTER TABLE [db_name.]table_name UPDATE column1 = expr1 [, ...] WHERE filter_expr
ALTER TABLE test_ud
UPDATE name = 'my', job = 'teacher' WHERE id = '2' ;
alter table test_muta update name='李思思' where id=3 ;
3、分区表操作
目前只有MergeTree系列 的表引擎支持数据分区
create table test_partition1(
id String ,
ctime DateTime
)engine=MergeTree()
partition by toYYYYMM(ctime)
order by (id) ;
-- 查看建表语句
show create table test_partition1;
CREATE TABLE default.test_partition1
(
`id` String,
`ctime` DateTime
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(ctime)
ORDER BY id
SETTINGS index_granularity = 8192 -- 索引粒度 稀疏索引
-- 插入数据
insert into test_partition1 values(1,now()) ,(2,'2021-06-11 11:12:13') ;
-- 查看数据
SELECT *
FROM test_partition1 ;
┌─id─┬───────────────ctime─┐
│ 2 │ 2021-06-11 11:12:13 │
└────┴─────────────────────┘
┌─id─┬───────────────ctime─┐
│ 1 │ 2021-05-19 13:38:29 │
└────┴─────────────────────┘
-- 查看表中的分区
ClickHouse内置了许多system系统表,用于查询自身的状态信息。 其中parts系统表专门用于查询数据表的分区信息。
SELECT
name,
table,
partition
FROM system.parts
WHERE table = 'test_partition1' ;
┌─name─────────┬─table───────────┬─partition─┐
│ 202105_1_1_0 │ test_partition1 │ 202105 │
│ 202106_2_2_0 │ test_partition1 │ 202106 │
└──────────────┴─────────────────┴───────────┘
insert into test_partition1 values(1,now()) ,(2,'2021-06-12 11:12:13') ;
┌─name─────────┬─table───────────┬─partition─┐
│ 202105_1_1_0 │ test_partition1 │ 202105 │
│ 202105_3_3_0 │ test_partition1 │ 202105 │
│ 202106_2_2_0 │ test_partition1 │ 202106 │
│ 202106_4_4_0 │ test_partition1 │ 202106 │
└──────────────┴─────────────────┴───────────┘
-- 删除分区
alter table test_partition1 drop partition '202109' ;
删除分区以后 , 分区中的所有的数据全部删除
SELECT
name,
table,
partition
FROM system.parts
WHERE table = 'test_partition1'
┌─name─────────┬─table───────────┬─partition─┐
│ 202106_2_2_0 │ test_partition1 │ 202106 │
│ 202106_4_4_0 │ test_partition1 │ 202106 │
└──────────────┴─────────────────┴───────────┘
SELECT *
FROM test_partition1
┌─id─┬───────────────ctime─┐
│ 2 │ 2021-06-12 11:12:13 │
└────┴─────────────────────┘
┌─id─┬───────────────ctime─┐
│ 2 │ 2021-06-11 11:12:13 │
└────┴─────────────────────┘
-- 复制分区
create table tb_y as tb_x ;
clickHouse支持将A表的分区数据复制到B表,这项特性可以用于快速数据写入、多表间数据同步和备份等场景,它的完整语法如下:
ALTER TABLE B REPLACE PARTITION partition_expr FROM A
ALTER TABLE test_partition2 REPLACE PARTITION '202107' FROM test_partition1 ;
不过需要注意的是,并不是任意数据表之间都能够相互复制,它们还需要满足两个前提 条件:
·两张表需要拥有相同的分区键
·它们的表结构完全相同。
create table test_partition2 as test_partition1 ;
show create table test_partition2 ; -- 查看表2的建表语句
CREATE TABLE default.test_partition2 as test_partition1 ;
│ CREATE TABLE default.test_partition2
(
`id` String,
`ctime` DateTime
)
ENGINE = MergeTree()
PARTITION BY toYYYYMM(ctime)
ORDER BY id
SETTINGS index_granularity = 8192 │ -- 两张表的结构完全一致
-- 复制一张表的分区到另一张表中
SELECT *
FROM test_partition2
┌─id─┬───────────────ctime─┐
│ 2 │ 2021-06-12 11:12:13 │
└────┴─────────────────────┘
┌─id─┬───────────────ctime─┐
│ 2 │ 2021-06-11 11:12:13 │
└────┴─────────────────────┘
┌─id─┬───────────────ctime─┐
│ 2 │ 2021-06-21 11:12:13 │
└────┴─────────────────────┘
----------------------------
alter table test_partition2 replace partition '202106' from test_partition1
alter table test_muta2 replace partition 'BJ' from test_muta ;
SELECT
name,
table,
partition
FROM system.parts
WHERE table = 'test_partition2'
┌─name─────────┬─table───────────┬─partition─┐
│ 202106_2_2_0 │ test_partition2 │ 202106 │
│ 202106_3_3_0 │ test_partition2 │ 202106 │
│ 202106_4_4_0 │ test_partition2 │ 202106 │
└──────────────┴─────────────────┴───────────┘
-- 重置分区数据
如果数据表某一列的数据有误,需要将其重置为初始值,如果设置了默认值那么就是默认值数据,如果没有设置默认值,系统会给出默认的初始值,此时可以使用下面的语句实现:
ALTER TABLE tb_name CLEAR COLUMN column_name IN PARTITION partition_expr ;
注意: 不能重置主键和分区字段
示例:
alter table test_rep clear column name in partition '202105' ;
alter table test_muta clear column name in partition 'BJ' ;
-- 卸载分区
表分区可以通过DETACH语句卸载,分区被卸载后,它的物理数据并没有删除,而是被转移到了当前数据表目录的detached子目录下。而装载分区则是反向操作,它能够将detached子目录下的某个分区重新装载回去。卸载与装载这一对伴生的操作,常用于分区数据的迁移和备份场景
┌─id─┬─name─┬───────────────ctime─┐
│ 1 │ │ 2021-05-19 13:59:49 │
│ 2 │ │ 2021-05-19 13:59:49 │
└────┴──────┴─────────────────────┘
┌─id─┬─name─┬───────────────ctime─┐
│ 3 │ ww │ 2021-04-11 11:12:13 │
└────┴──────┴─────────────────────┘
alter table test_rep detach partition '202105' ;
alter table test_muta detach partition 'BJ' ;
┌─id─┬─name─┬───────────────ctime─┐
│ 3 │ ww │ 2021-04-11 11:12:13 │
└────┴──────┴─────────────────────┘
-- 装载分区
alter table test_rep attach partition '202105' ;
alter table test_muta attach partition 'BJ' ;
┌─id─┬─name─┬───────────────ctime─┐
│ 1 │ │ 2021-05-19 13:59:49 │
│ 2 │ │ 2021-05-19 13:59:49 │
└────┴──────┴─────────────────────┘
┌─id─┬─name─┬───────────────ctime─┐
│ 3 │ ww │ 2021-04-11 11:12:13 │
└────┴──────┴─────────────────────┘
-- 记住,一旦分区被移动到了detached子目录,就代表它已经脱离了ClickHouse的管理,ClickHouse并不会主动清理这些文件。这些分区文件会一直存在,除非我们主动删除或者使用ATTACH语句重新装载
二、查询语法
1、with
with x as (select from ) ,y as(select from) select from x , y …
ClickHouse支持CTE(Common Table Expression,公共表表达式),以增强查询语句的表达
--pow(2,2)是2的2次方
SELECT pow(2, 2)
┌─pow(2, 2)─┐
│ 4 │
└───────────┘
SELECT pow(pow(2, 2), 2)
┌─pow(pow(2, 2), 2)─┐
│ 16 │
└───────────────────┘
在改用CTE的形式后,可以极大地提高语句的可读性和可维护性
with pow(2,2) as a select pow(a,3) ;
(1)定义变量
WITH
1 AS start,
10 AS end
SELECT
id + start,
*
FROM tb_mysql
┌─plus(id, start)─┬─id─┬─name─┬─age─┐
│ 2 │ 1 │ zss │ 23 │
│ 3 │ 2 │ lss │ 33 │
│ 4 │ 3 │ ww │ 44 │
│ 2 │ 1 │ zss │ 23 │
│ 3 │ 2 │ lss │ 33 │
│ 2 │ 1 │ zss │ 23 │
│ 3 │ 2 │ lss │ 33 │
└─────────────────┴────┴──────┴─────┘
(2)调用函数
SELECT *
FROM tb_partition
┌─id─┬─name─┬────────────birthday─┐
│ 1 │ xl │ 2021-05-20 10:50:46 │
│ 2 │ xy │ 2021-05-20 11:17:47 │
└────┴──────┴─────────────────────┘
┌─id─┬─name─┬────────────birthday─┐
│ 3 │ xf │ 2021-05-19 11:11:12 │
└────┴──────┴───────────---------─┘
WITH toDate(birthday) AS bday
SELECT
id,
name,
bday
FROM tb_partition
┌─id─┬─name─┬───────bday─┐
│ 1 │ xl │ 2021-05-20 │
│ 2 │ xy │ 2021-05-20 │
└────┴──────┴────────────┘
┌─id─┬─name─┬───────bday─┐
│ 3 │ xf │ 2021-05-19 │
└────┴──────┴────────────┘
- 练习
WITH
count(1) AS cnt,
groupArray(cdate) AS list
SELECT
name,
cnt,
list
FROM tb_shop2
GROUP BY name
groupArray(x)用于创建一个数组,该数组的元素由聚合函数的参数值组成。数据元素的顺序是不确定的。
groupArray(max_size)(x)在groupArray(x)函数的基础上,限制数组的大小为max_size。
(3)子查询
可以定义子查询 ,但是一定还要注意的是,子查询只能返回一行结果 ,否则会跑出异常
WITH
(
SELECT *
FROM tb_partition
WHERE id = 1
) AS sub
SELECT
*,
sub
FROM tb_partition
┌─id─┬─name─┬────────────birthday─┬─sub────────────────────────────┐
│ 1 │ xl │ 2021-05-20 10:50:46 │ (1,'xl','2021-05-20 10:50:46') │
│ 2 │ xy │ 2021-05-20 11:17:47 │ (1,'xl','2021-05-20 10:50:46') │
└────┴──────┴─────────────────────┴────────────────────────────────┘
┌─id─┬─name─┬────────────birthday─┬─sub────────────────────────────┐
│ 3 │ xf │ 2021-05-19 11:11:12 │ (1,'xl','2021-05-20 10:50:46') │
└────┴──────┴─────────────────────┴────────────────────────────────┘
with (select * from tb_shop2 where name = 'a' and cdate = '2017-03-01') as x select * from tb_shop2 where (name,cdate,money)=x ;
1 子查询的结果必须是一条数据
2 where (id,name,age) = (1,'zss',23)
2、from 表函数
表函数
构建表的函数 , 使用场景: SELECT查询的[FROM)子句。 创建表AS 查询。
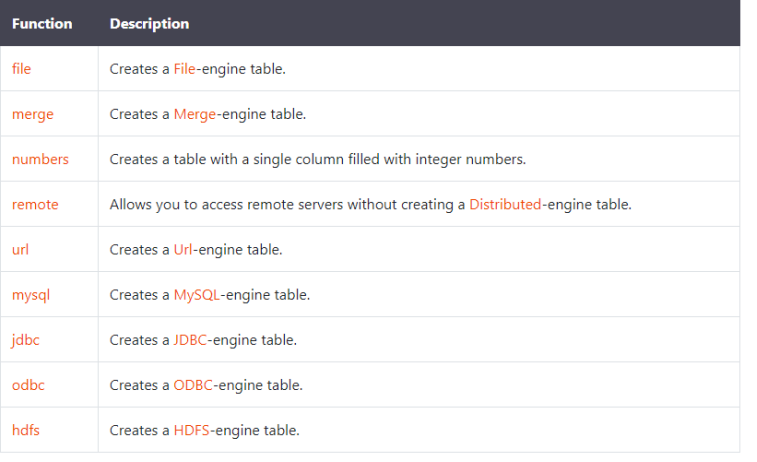
(1)from mysql
从mysql表中加载数据。
mysql('host:port', 'database', 'table', 'user', 'password'[, replace_query, 'on_duplicate_clause'])
select * from mysql('linux1:3306','ck','tb_test1' ,'root' , '123456') ;
(2)from hdfs
从hdfs文件加载数据
hdfs(URI, format, structure)
select * from hdfs('hdfs://doit01:8020/data/user.txt','CSV' ,'id Int8 , name String') ;
(3)from remote
从远程服务器的ClickHouse上加载数据
remote('addresses_expr', db.table[, 'user'[, 'password'], sharding_key])
SELECT *
FROM remote('doit01', 'doit26.tb_person')
(4)from file
去指定的路径下加载本地的数据
select * from file('/ck/user.txt','CSV','id Int8 , name String ,gender String,age UInt8') ;
后面是字段名和字段类型。
需要注意的是:默认加载的是特定的文件夹,数据一定要在指定的文件夹下才会被加载
修改默认的数据加载的文件夹
vi /etc/clickhouse-server/config.xml
/path n下一个
<!-- Directory with user provided files that are accessible by 'file' table function. -->
<user_files_path>/</user_files_path>
重启服务
/etc/init.d/clickhouse-server restart
(5)from numbers
SELECT * FROM numbers(10) ; --从0开始取10个数字
┌─number─┐
│ 0 │
│ 1 │
│ 2 │
│ 3 │
│ 4 │
│ 5 │
│ 6 │
│ 7 │
│ 8 │
│ 9 │
└────────┘
SELECT * FROM numbers(2, 10) ; --从2开始取10个数字
┌─number─┐
│ 2 │
│ 3 │
│ 4 │
│ 5 │
│ 6 │
│ 7 │
│ 8 │
│ 9 │
│ 10 │
│ 11 │
└────────┘
SELECT * FROM numbers(10) limit 3 ;
--查出一年的每一天的日期
SELECT toDate('2020-01-01') + number AS d FROM numbers(365)
3、array join
ARRAY JOIN子句允许在数据表的内部,与数组或嵌套类型的字段进行JOIN操作,从而将一行数组展开为多行。类似于hive中的explode炸裂函数的功能!
CREATE TABLE test_arrayjoin
(
`name` String,
`vs` Array(Int8)
)
ENGINE = Memory ;
insert into test_arrayjoin values('xw',[1,2,3]),('xl',[4,5]),('xk',[1]);
-- 将数组中的数据展开
SELECT
*,
s
FROM test_arrayjoin
ARRAY JOIN vs AS s
┌─name─┬─vs──────┬─s─┐
│ xw │ [1,2,3] │ 1 │
│ xw │ [1,2,3] │ 2 │
│ xw │ [1,2,3] │ 3 │
│ xl │ [4,5] │ 4 │
│ xl │ [4,5] │ 5 │
│ xk │ [1] │ 1 │
└──────┴─────────┴───┘
-- arrayMap 高阶函数,对数组中的每个元素进行操作
SELECT
*,
arrayMap(x->x*2 , vs) vs2
FROM test_arrayjoin ;
SELECT
*,
arrayMap(x -> (x * 2), vs) AS vs2
FROM test_arrayjoin
┌─name─┬─vs──────┬─vs2─────┐
│ xw │ [1,2,3] │ [2,4,6] │
│ xl │ [4,5] │ [8,10] │
│ xk │ [1] │ [2] │
└──────┴─────────┴─────────┘
SELECT
*,
arrayMap(x -> (x * 2), vs) AS vs2 ,
vv1 ,
vv2
FROM test_arrayjoin
array join
vs as vv1 ,
vs2 as vv2 ;
┌─name─┬─vs──────┬─vs2─────┬─vv1─┬─vv2─┐
│ xw │ [1,2,3] │ [2,4,6] │ 1 │ 2 │
│ xw │ [1,2,3] │ [2,4,6] │ 2 │ 4 │
│ xw │ [1,2,3] │ [2,4,6] │ 3 │ 6 │
│ xl │ [4,5] │ [8,10] │ 4 │ 8 │
│ xl │ [4,5] │ [8,10] │ 5 │ 10 │
│ xk │ [1] │ [2] │ 1 │ 2 │
└──────┴─────────┴─────────┴─────┴─────┘
select
id ,
h ,
xx
from
tb_array_join
array join
hobby as h ,
arrayEnumerate(hobby) as xx ;
┌─id─┬─h─────┬─xx─┐
│ 1 │ eat │ 1 │
│ 1 │ drink │ 2 │
│ 1 │ sleep │ 3 │
│ 2 │ study │ 1 │
│ 2 │ sport │ 2 │
│ 2 │ read │ 3 │
└────┴───────┴────┘
┌─id─┬─h─────┬─xx─┐
│ 3 │ eat │ 1 │
│ 3 │ drink │ 2 │
4、关联查询
所有标准 SQL JOIN 支持类型:
- INNER JOIN, only matching rows are returned.
- LEFT OUTER JOIN, non-matching rows from left table are returned in addition to matching rows.
- RIGHT OUTER JOIN, non-matching rows from right table are returned in addition to matching rows.
- FULL OUTER JOIN, non-matching rows from both tables are returned in addition to matching rows.
- CROSS JOIN, produces cartesian product of whole tables, “join keys” are not specified.
JOIN子句可以对左右两张表的数据进行连接,这是最常用的查询子句之一。它的语法包含连接精度和连接类型两部分。
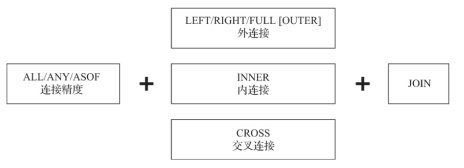
(一)连接精度
连接精度决定了JOIN查询在连接数据时所使用的策略,目前支持ALL、ANY和ASOF三种类型。如果不主动声明,则默认是ALL。可以通过join_default_strictness配置参数修改默认的连接精度类型。
对数据是否连接匹配的判断是通过JOIN KEY进行的,目前只支持等式(EQUAL JOIN)。交叉连接(CROSS JOIN)不需要使用JOIN KEY,因为它会产生笛卡儿积。
交叉连接(CROSS JOIN)后无法跟随on条件,只能用where对连接后的笛卡尔积过滤
-- 准备数据
drop table if exists yg ;
create table yg(
id Int8 ,
name String ,
age UInt8 ,
bid Int8
)engine=Log ;
insert into yg values(1,'AA',23,1) ,
(2,'BB',24,2) ,
(3,'VV',27,1) ,
(4,'CC',13,3) ,
(5,'KK',53,3) ,
(6,'MM',33,3) ;
drop table if exists bm ;
create table bm(
bid Int8 ,
name String
)engine=Log ;
insert into bm values(1,'x'),(2,'Y'),(3,'Z');
drop table if exists gz ;
drop table gz ;
create table gz(
id Int8 ,
jb Int64 ,
jj Int64
)engine=Log ;
insert into gz values (1,1000,2000),(1,1000,2000),(2,2000,1233),(3,2000,3000),(4,4000,1000),(5,5000,2000);
(1)all
如果左表内的一行数据,在右表中有多行数据与之连接匹配,则返回右表中全部连接的数据。而判断连接匹配的依据是左表与右表内的数据,基于连接键(JOIN KEY)的取值完全相等(equal),等同于 left.key=right.key。all是默认的连接精度,相当于普通的join。
SELECT *
FROM yg AS inser
ALL INNER JOIN gz ON yg.id = gz.id ;
SELECT *
FROM yg AS inser
ALL JOIN gz ON yg.id = gz.id ;
SELECT *
FROM yg AS inser
JOIN gz ON yg.id = gz.id ;
┌─id─┬─name─┬─age─┬─bid─┬─gz.id─┬───jb─┬───jj─┐
│ 1 │ AA │ 23 │ 1 │ 1 │ 1000 │ 2000 │
│ 1 │ AA │ 23 │ 1 │ 1 │ 1000 │ 2000 │
│ 2 │ BB │ 24 │ 2 │ 2 │ 2000 │ 1233 │
│ 3 │ VV │ 27 │ 1 │ 3 │ 2000 │ 3000 │
│ 4 │ CC │ 13 │ 3 │ 4 │ 4000 │ 1000 │
│ 5 │ KK │ 53 │ 3 │ 5 │ 5000 │ 2000 │
└────┴──────┴─────┴─────┴───────┴──────┴──────┘
(2)any
如果左表内的一行数据,在右表中有多行数据与之连接匹配,则仅返回右表中第一行连接的数据。ANY与ALL判断连接匹配的依据相同。
SELECT *
FROM yg
ANY INNER JOIN gz ON yg.id = gz.id
┌─id─┬─name─┬─age─┬─bid─┬─gz.id─┬───jb─┬───jj─┐
│ 1 │ AA │ 23 │ 1 │ 1 │ 1000 │ 2000 │
│ 2 │ BB │ 24 │ 2 │ 2 │ 2000 │ 1233 │
│ 3 │ VV │ 27 │ 1 │ 3 │ 2000 │ 3000 │
│ 4 │ CC │ 13 │ 3 │ 4 │ 4000 │ 1000 │
│ 5 │ KK │ 53 │ 3 │ 5 │ 5000 │ 2000 │
└────┴──────┴─────┴─────┴───────┴──────┴──────┘
(3)asof
asof连接精度允许在 on 之后加多条两表连接判断语句
drop table if exists emp1 ;
create table emp1(
id Int8 ,
name String ,
ctime DateTime
)engine=Log ;
insert into emp1 values(1,'AA','2021-01-03 00:00:00'),
(1,'AA','2021-01-02 00:00:00'),
(2,'CC','2021-01-01 00:00:00'),
(3,'DD','2021-01-01 00:00:00'),
(4,'EE','2021-01-01 00:00:00');
drop table if exists emp2 ;
create table emp2(
id Int8 ,
name String ,
ctime DateTime
)engine=Log ;
insert into emp2 values(1,'aa','2021-01-02 00:00:00'),
(1,'aa','2021-01-02 00:00:00'),
(2,'cc','2021-01-01 00:00:00'),
(3,'dd','2021-01-01 00:00:00');
-- ASOF inner join
SELECT *
FROM emp2
ASOF INNER JOIN emp1 ON (emp1.id = emp2.id) AND (emp1.ctime > emp2.ctime)
┌─id─┬─name─┬───────────────ctime─┬─emp1.id─┬─emp1.name─┬──────────emp1.ctime─┐
│ 1 │ aa │ 2021-01-02 00:00:00 │ 1 │ AA │ 2021-01-03 00:00:00 │
│ 1 │ aa │ 2021-01-02 00:00:00 │ 1 │ AA │ 2021-01-03 00:00:00 │
└────┴──────┴─────────────────────┴─────────┴───────────┴─────────────────────┘
5、with模型
查询立方体模型
根据聚合维度 提前计算好所有的组合可能性进行聚合
- With cube
with cube 语法是将所有的维度进行group by的结果组合。
一个具有N维的数据模型,做完Cube操作,能产生2的N次方种聚合方式。
即3个字段的聚合,会有2的3次方的组合方式。 - With rollup
各维度组合,但是不能跳跃维度查询,前一维度为null后一位维度必须为null,前一维度取非null时,下一维度随意 - With totals
正常 group by 得到结果后,再加一条总数
drop table is exists tb_with ;
create table tb_with(
id UInt8 ,
vist UInt8,
province String ,
city String ,
area String
)engine=MergeTree()
order by id ;
insert into tb_with values(1,12,'山东','济南','历下') ;
insert into tb_with values(2,12,'山东','济南','历下') ;
insert into tb_with values(3,12,'山东','济南','天桥') ;
insert into tb_with values(4,12,'山东','济南','天桥') ;
insert into tb_with values(5,88,'山东','青岛','黄岛') ;
insert into tb_with values(6,88,'山东','青岛','黄岛') ;
insert into tb_with values(7,12,'山西','太原','小店') ;
insert into tb_with values(8,12,'山西','太原','小店') ;
insert into tb_with values(9,112,'山西','太原','尖草坪') ;
SELECT
province,
city,
area,
sum(vist)
FROM tb_with
GROUP BY
province,
city,
area
WITH CUBE ;
┌─province─┬─city─┬─area───┬─sum(vist)─┐
│ 山东 │ 青岛 │ 黄岛 │ 176 │
│ 山东 │ 济南 │ 天桥 │ 24 │
│ 山西 │ 太原 │ 尖草坪 │ 112 │
│ 山东 │ 济南 │ 历下 │ 24 │
│ 山西 │ 太原 │ 小店 │ 24 │
└──────────┴──────┴────────┴───────────┘
┌─province─┬─city─┬─area─┬─sum(vist)─┐
│ 山东 │ 青岛 │ │ 176 │
│ 山东 │ 济南 │ │ 48 │
│ 山西 │ 太原 │ │ 136 │
└──────────┴──────┴──────┴───────────┘
┌─province─┬─city─┬─area───┬─sum(vist)─┐
│ 山东 │ │ 历下 │ 24 │
│ 山东 │ │ 天桥 │ 24 │
│ 山西 │ │ 尖草坪 │ 112 │
│ 山西 │ │ 小店 │ 24 │
│ 山东 │ │ 黄岛 │ 176 │
└──────────┴──────┴────────┴───────────┘
┌─province─┬─city─┬─area─┬─sum(vist)─┐
│ 山西 │ │ │ 136 │
│ 山东 │ │ │ 224 │
└──────────┴──────┴──────┴───────────┘
┌─province─┬─city─┬─area───┬─sum(vist)─┐
│ │ 济南 │ 历下 │ 24 │
│ │ 济南 │ 天桥 │ 24 │
│ │ 太原 │ 尖草坪 │ 112 │
│ │ 青岛 │ 黄岛 │ 176 │
│ │ 太原 │ 小店 │ 24 │
└──────────┴──────┴────────┴───────────┘
┌─province─┬─city─┬─area─┬─sum(vist)─┐
│ │ 青岛 │ │ 176 │
│ │ 济南 │ │ 48 │
│ │ 太原 │ │ 136 │
└──────────┴──────┴──────┴───────────┘
┌─province─┬─city─┬─area───┬─sum(vist)─┐
│ │ │ 天桥 │ 24 │
│ │ │ 小店 │ 24 │
│ │ │ 黄岛 │ 176 │
│ │ │ 历下 │ 24 │
│ │ │ 尖草坪 │ 112 │
└──────────┴──────┴────────┴───────────┘
┌─province─┬─city─┬─area─┬─sum(vist)─┐
│ │ │ │ 360 │
└──────────┴──────┴──────┴───────────┘
SELECT
province,
city,
area,
sum(vist)
FROM tb_with
GROUP BY
province,
city,
area
WITH ROLLUP;
┌─province─┬─city─┬─area───┬─sum(vist)─┐
│ 山东 │ 青岛 │ 黄岛 │ 176 │
│ 山东 │ 济南 │ 天桥 │ 24 │
│ 山西 │ 太原 │ 尖草坪 │ 112 │
│ 山东 │ 济南 │ 历下 │ 24 │
│ 山西 │ 太原 │ 小店 │ 24 │
└──────────┴──────┴────────┴───────────┘
┌─province─┬─city─┬─area─┬─sum(vist)─┐
│ 山东 │ 青岛 │ │ 176 │
│ 山东 │ 济南 │ │ 48 │
│ 山西 │ 太原 │ │ 136 │
└──────────┴──────┴──────┴───────────┘
┌─province─┬─city─┬─area─┬─sum(vist)─┐
│ 山西 │ │ │ 136 │
│ 山东 │ │ │ 224 │
└──────────┴──────┴──────┴───────────┘
┌─province─┬─city─┬─area─┬─sum(vist)─┐
│ │ │ │ 360 │
└──────────┴──────┴──────┴───────────┘
SELECT
province,
city,
area,
sum(vist)
FROM tb_with
GROUP BY
province,
city,
area
WITH TOTALS;
┌─province─┬─city─┬─area───┬─sum(vist)─┐
│ 山东 │ 青岛 │ 黄岛 │ 176 │
│ 山东 │ 济南 │ 天桥 │ 24 │
│ 山西 │ 太原 │ 尖草坪 │ 112 │
│ 山东 │ 济南 │ 历下 │ 24 │
│ 山西 │ 太原 │ 小店 │ 24 │
└──────────┴──────┴────────┴───────────┘
Totals:
┌─province─┬─city─┬─area─┬─sum(vist)─┐
│ │ │ │ 360 │
└──────────┴──────┴──────┴───────────┘
三、函数
ClickHouse主要提供两类函数—普通函数和聚合函数。普通函数由IFunction接口定义,拥有数十种函数实现,例如FunctionFormatDateTime、FunctionSubstring等。除了一些常见的函数 ( 诸如四则运算、日期转换等 ) 之外,也不乏一些非常实用的函数,例如网址提取函数、IP地址脱敏函数等。普通函数是没有状态的,函数效果作用于每行数据之上。当然,在函数具体执行的过程中,并不会一行一行地运算,而是采用向量化的方式直接作用于一整列数据。聚合函数由IAggregateFunction接口定义,相比无状态的普通函数,聚合函数是有状态的。以COUNT聚合函数为例,其AggregateFunctionCount的状态使用整UInt64记录。聚合函数的状态支持序列化与反序列化,所以能够在分布式节点之间进行传输,以实现增量计算。
1、 普通函数
(1)类型转换函数
toInt8(expr)— Results in theInt8data type.toInt16(expr)— Results in theInt16data type.toInt32(expr)— Results in theInt32data type.toInt64(expr)— Results in theInt64data type.toInt128(expr)— Results in theInt128data type.toInt256(expr)— Results in theInt256data type.
SELECT toInt64(nan), toInt32(32), toInt16('16'), toInt8(8.8);
┌─────────toInt64(nan)─┬─toInt32(32)─┬─toInt16('16')─┬─toInt8(8.8)─┐
│ -9223372036854775808 │ 32 │ 16 │ 8 │
└──────────────────────┴─────────────┴───────────────┴─────────────┘
-
toUInt(8|16|32|64|256)OrZero
-
toUInt(8|16|32|64|256)OrNull
-
toFloat(32|64)
-
toFloat(32|64)OrZero
-
toFloat(32|64)OrNull
-
toDate
-
toDateOrZero
-
toDateOrNull
-
toDateTime
-
toDateTimeOrZero
-
toDateTimeOrNull
-
toDecimal(32|64|128|256)
toString
now() AS now_local,
toString(now(), 'Asia/Yekaterinburg') AS now_yekat;
┌───────────now_local─┬─now_yekat───────────┐
│ 2016-06-15 00:11:21 │ 2016-06-15 02:11:21 │
└─────────────────────┴─────────────────────┘
- CAST(x, T)
Arguments
- `x` — Any type.
- `T` — Destination type. String
**Returned value**
SELECT
'2016-06-15 23:00:00' AS timestamp,
CAST(timestamp AS DateTime) AS datetime,
CAST(timestamp AS Date) AS date,
CAST(timestamp, 'String') AS string,
CAST(timestamp, 'FixedString(22)') AS fixed_string;
┌─timestamp───────────┬────────────datetime─┬───────date─┬─string──────────────┬─fixed_string──────────
│ 2016-06-15 23:00:00 │ 2016-06-15 23:00:00 │ 2016-06-15 │ 2016-06-15 23:00:00 │ 2016-06-15 23:00:00000 │
└─────────────────────┴─────────────────────┴────────────┴─────────────────────┴───────────────────────
(2)日期函数
SELECT
toDateTime('2016-06-15 23:00:00') AS time,
toDate(time) AS date_local,
toDate(time, 'Asia/Yekaterinburg') AS date_yekat,
toString(time, 'US/Samoa') AS time_samoa
┌────────────────time─┬─date_local─┬─date_yekat─┬─time_samoa──────────┐
│ 2016-06-15 23:00:00 │ 2016-06-15 │ 2016-06-16 │ 2016-06-15 09:00:00 │
└─────────────────────┴────────────┴────────────┴─────────────────────┘
- toDate
- toYear
- toMonth
- toHour
- toMinute
- toSecond
- toUnixTimestamp
- date_trunc 将时间截断 date_trunc(unit, value[, timezone])
second
minute
hour
day
week
month
quarter
year
SELECT now(), date_trunc('hour', now());
┌───────────────now()─┬─date_trunc('hour', now())─┐
│ 2021-05-21 13:52:42 │ 2021-05-21 13:00:00 │
└─────────────────────┴───────────────────────────┘
- date_add
date_add(unit, value, date)
second
minute
hour
day
week
month
quarter
year
SELECT date_add(YEAR, 3, toDate('2018-01-01'));
date_diff('unit', startdate, enddate, [timezone])
- date_diff
- date_sub
- timestamp_add
- timestamp_sub
- toYYYYMM
- toYYYYMMDD
- toYYYYMMDDhhmmss
- formatDateTime
| %C | year divided by 100 and truncated to integer (00-99) | 20 |
|---|---|---|
| %d | day of the month, zero-padded (01-31) | 02 |
| %D | Short MM/DD/YY date, equivalent to %m/%d/%y | 01/02/18 |
| %e | day of the month, space-padded ( 1-31) | 2 |
| %F | short YYYY-MM-DD date, equivalent to %Y-%m-%d | 2018-01-02 |
| %G | four-digit year format for ISO week number, calculated from the week-based year [defined by the ISO 860 standard, normally useful only with %V | 2018 |
| %g | two-digit year format, aligned to ISO 8601, abbreviated from four-digit notation | 18 |
| %H | hour in 24h format (00-23) | 22 |
| %I | hour in 12h format (01-12) | 10 |
| %j | day of the year (001-366) | 002 |
| %m | month as a decimal number (01-12) | 01 |
| %M | minute (00-59) | 33 |
| %n | new-line character (‘’) | |
| %p | AM or PM designation | PM |
| %Q | Quarter (1-4) | 1 |
| %R | 24-hour HH:MM time, equivalent to %H:%M | 22:33 |
| %S | second (00-59) | 44 |
| %t | horizontal-tab character (’) | |
| %T | ISO 8601 time format (HH:MM:SS), equivalent to %H:%M:%S | 22:33:44 |
| %u | ISO 8601 weekday as number with Monday as 1 (1-7) | 2 |
| %V | ISO 8601 week number (01-53) | 01 |
| %w | weekday as a decimal number with Sunday as 0 (0-6) | 2 |
| %y | Year, last two digits (00-99) | 18 |
| %Y | Year | 2018 |
| %% | a % sign | % |
SELECT formatDateTime(now(), '%D')
┌─formatDateTime(now(), '%D')─┐
│ 05/21/21 │
└─────────────────────────────┘
- FROM_UNIXTIME
SELECT FROM_UNIXTIME(423543535)
┌─FROM_UNIXTIME(423543535)─┐
│ 1983-06-04 10:58:55 │
└──────────────────────────┘
(3)条件函数
- if(exp1 , exp2,exp3)
- multiIf() 相当于case
drop table if exists tb_if;
create table if not exists tb_if(
uid Int16,
name String ,
gender String
)engine = TinyLog ;
insert into tb_if values(1,'zss1','M') ;
insert into tb_if values(2,'zss2','M') ;
insert into tb_if values(3,'zss3','F') ;
insert into tb_if values(4,'zss4','O') ;
insert into tb_if values(5,'zss5','F') ;
--------单条件判断---------
SELECT
*,
if(gender = 'M', '男', '女')
FROM tb_if
┌─uid─┬─name─┬─gender─┬─if(equals(gender, 'M'), '男', '女')─┐
│ 1 │ zss1 │ M │ 男 │
│ 2 │ zss2 │ M │ 男 │
│ 3 │ zss3 │ F │ 女 │
│ 4 │ zss4 │ O │ 女 │
│ 5 │ zss5 │ F │ 女 │
-------------------------------------------------------------
-------多条件判断----------
SELECT
*,
multiIf(gender = 'M', '男', gender = 'F', '女', '保密') AS sex
FROM tb_if
┌─uid─┬─name─┬─gender─┬─sex──┐
│ 1 │ zss1 │ M │ 男 │
│ 2 │ zss2 │ M │ 男 │
│ 3 │ zss3 │ F │ 女 │
│ 4 │ zss4 │ O │ 保密 │
│ 5 │ zss5 │ F │ 女 │
└─────┴──────┴────────┴──────┘
(4)其他
visitParamExtractRaw('{"abc":"\n\u0000"}', 'abc') = '"\n\u0000"';
visitParamExtractRaw('{"abc":{"def":[1,2,3]}}', 'abc') = '{"def":[1,2,3]}';
select JSONExtract('{"a":"hello","b":"tom","c":12}', 'Tuple(String,String,UInt8)') as kn;
-- 元组函数
select tupleElement((1,2,3,4,66),5);
-- BitMap 函数
-- bitmapBuild
SELECT
bitmapBuild([1, 2, 3, 4, 5]) AS res,
toTypeName(res)
┌─res─┬─toTypeName(bitmapBuild([1, 2, 3, 4, 5]))─┐
│ │ AggregateFunction(groupBitmap, UInt8) │
└─────┴──────────────────────────────────────────┘
-- bitmapToArray
SELECT bitmapToArray(bitmapBuild([1, 2, 3, 4, 5])) AS res;
-- bitmapSubsetInRange
SELECT bitmapToArray(bitmapSubsetInRange(bitmapBuild([0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 100, 200, 500]), toUInt32(30), toUInt32(200))) AS res
┌─res───────────────┐
│ [30,31,32,33,100] │
└───────────────────┘
-- bitmapContains
SELECT bitmapContains(bitmapBuild([1, 5, 7, 9]), toUInt32(9)) AS res
┌─res─┐
│ 1 │
└─────┘
-- bitmapHasAny 有任意一个元素
SELECT bitmapHasAny(bitmapBuild([1, 2, 3]), bitmapBuild([3, 4, 5])) AS res
┌─res─┐
│ 1 │
└─────
-- bitmapHasAll 有任意一个元素
-- bitmapMin
-- bitmapMax
-- bitmapAnd 交集
-- bitmapOr 并集
-- bitmapAndnot差集
四、分布式
集群是副本和分片的基础,它将ClickHouse的服务拓扑由单节点延 伸到多个节点,但它并不像Hadoop生态的某些系统那样,要求所有节点组成一个单一的大集群。ClickHouse的集群配置非常灵活,用户既可以将所有节点组成一个单一集群,也可以按照业务的诉求,把节点划分为多个小的集群。在每个小的集群区域之间,它们的节点、分区和副本数量可以各不相同
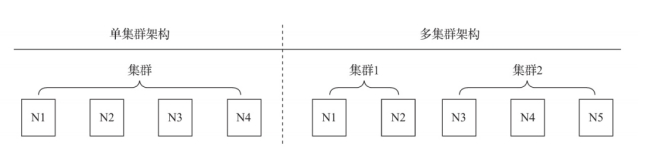
另一种是从功能作用层面区分,使用副本的主要目的是防止数据丢失,增加数据存储的冗余;而使用分片的主要目的是实现数据的水平切分。
1、环境搭建
- 在集群的每个节点上安装ck服务
- 修改 /etc/clickhouse-server/config.xml 配置文件,使其支持远程连接
<listen_host>::<listen_host> - 重启服务
/etc/init.d/clickhouse-server restart - 配置zookeeper 正常启动
在页面请求http://linux1:8123/play测试连接
2、副本概念
如果在*MergeTree的前面增加Replicated的前缀,则能够组合成一个新的变种引擎,即Replicated-MergeTree复制表!

只有使用了ReplicatedMergeTree复制表系列引擎,才能应用副本的能力(后面会介绍另一种副本的实现方式)。或者用一种更为直接的方式理解,即使用ReplicatedMergeTree的数据表就是副本。 ReplicatedMergeTree是MergeTree的派生引擎,它在MergeTree的 基础上加入了分布式协同的能力。
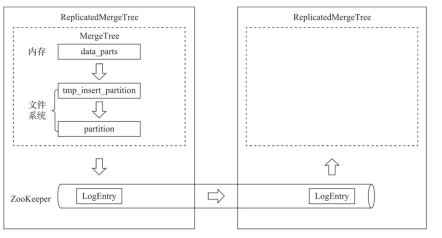
在MergeTree中,一个数据分区由开始创建到全部完成,会历经两类存储区域。
(1)内存:数据首先会被写入内存缓冲区。
(2)本地磁盘:数据接着会被写入tmp临时目录分区,待全部完成后再将临时目录重命名为正式分区。
ReplicatedMergeTree在上述基础之上增加了ZooKeeper的部分,它会进一步在ZooKeeper内创建一系列的监听节点,并以此实现多个实例之间的通信。在整个通信过程中,ZooKeeper并不会涉及表数据的传输。
- 依赖ZooKeeper:在执行INSERT和ALTER查询的时候,ReplicatedMergeTree需要借助ZooKeeper的分布式协同能力,以实现多个副本之间的同步。但是在查询副本的时候,并不需要使用 ZooKeeper。
- 表级别的副本:副本是在表级别定义的,所以每张表的副本配置都可以按照它的实际需求进行个性化定义,包括副本的数量,以及副本在集群内的分布位置等。
- 多主架构(Multi Master):可以在任意一个副本上执行INSERT和ALTER查询,它们的效果是相同的。这些操作会借助ZooKeeper的协同能力被分发至每个副本以本地形式执行。
- Block数据块:在执行INSERT命令写入数据时,会依据 max_insert_block_size的大小(默认1048576行)将数据切分成若干个Block数据块。所以Block数据块是数据写入的基本单元,并且具有 写入的原子性和唯一性。
- 原子性:在数据写入时,一个Block块内的数据要么全部写入成功,要么全部失败。
- 唯一性:在写入一个Block数据块的时候,会按照当前Block数据块的数据顺序、数据行和数据大小等指标,计算Hash信息摘要并记录在案。在此之后,如果某个待写入的Block数据块与先前已被写入的 Block数据块拥有相同的Hash摘要(Block数据块内数据顺序、数据大小和数据行均相同),则该Block数据块会被忽略。这项设计可以预防由异常原因引起的Block数据块重复写入的问题。
3、分片概念
通过引入数据副本,虽然能够有效降低数据的丢失风险(多份存储),并提升查询的性能(分摊查询、读写分离),但是仍然有一个问题没有解决,那就是数据表的容量问题。到目前为止,每个副本自 身,仍然保存了数据表的全量数据。所以在业务量十分庞大的场景中,依靠副本并不能解决单表的性能瓶颈。想要从根本上解决这类问题,需要借助另外一种手段,即进一步将数据水平切分,也就是我们将要介绍的数据分片。ClickHouse中的每个服务节点都可称为一个shard(分片)。从理论上来讲,假设有N(N>=1)张数据表A,分布在N个ClickHouse服务节点,而这些数据表彼此之间没有重复数据,那么就可以说数据表A拥有N个分片。然而在工程实践中,如果只有这些分片表,那么整个 Sharding(分片)方案基本是不可用的。对于一个完整的方案来说,还需要考虑数据在写入时,如何被均匀地写至各个shard,以及数据在查询时,如何路由到每个shard,并组合成结果集。所以,ClickHouse 的数据分片需要结合Distributed表引擎一同使用。
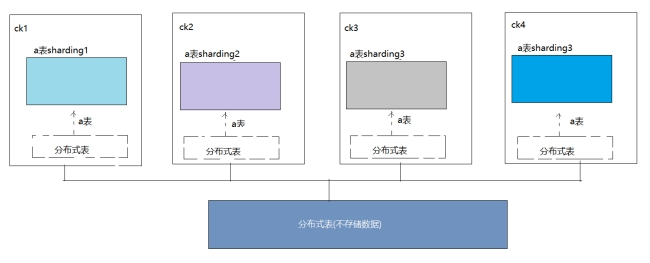
Distributed表引擎自身不存储任何数据,它能够作为分布式表的一层透明代理,在集群内部自动开展数据的写入、分发、查询、路由等工作。
4、配置zookeeper
需要在每台CK的节点上配置ZK的位置
ClickHouse使用一组zookeeper标签定义相关配置,默认情况下,在全局配置config.xml中定义即可。但是各个副本所使用的Zookeeper 配置通常是相同的,为了便于在多个节点之间复制配置文件,更常见的做法是将这一部分配置抽离出来,独立使用一个文件保存。
vi /etc/clickhouse-server/config.xml
<zookeeper>
<node index="1">
<host>linux1</host>
<port>2181</port>
</node>
<node index="2">
<host>linux2</host>
<port>2181</port>
</node>
<node index="3">
<host>linux3</host>
<port>2181</port>
</node>
</zookeeper>
将配置文件同步到其他集群节点!!
scp config.xml linux02:$PWD
scp config.xml linux03:$PWD
重启服务
/etc/init.d/clickhouse-server restart
ClickHouse在它的系统表中,颇为贴心地提供了一张名为zookeeper的代理表。通过这张表,可以使用SQL查询的方式读取远端ZooKeeper内的数据。有一点需要注意,在用于查询的SQL语句中,必须指定path条件。
5、创建副本表
在创建副本表以前, 首先要启动集群中的zookeeper。
由于增加了数据的冗余存储,所以降低了数据丢失的风险;其次,由于副本采用了多主架构,所以每个副本实例都可以作为数据读、写的入口,这无疑分摊了节点的负载。
在使用单使用副本功能的时候 , 我们对CK集群不需要任何的配置就可以实现数据的多副本存储!只需要在建表的时候指定engine和ZK的位置即可
ENGINE = ReplicatedMergeTree('zk_path', 'replica_name')
engine=ReplicatedMergeTree('/clickhouse/tables/01/tb_demo1', 'linux01')
-- /clickhouse/tables/{shard}/table_name
-- /clickhouse/tables/ 是约定俗成的路径固定前缀,表示存放数据表的根路径。
-
{shard}表示分片编号,通常用数值替代,例如01、02、03。一张数据表可以有多个分片,而每个分片都可以拥有自己的副本。
-
table_name表示数据表的名称,为了方便维护,通常与物理表的名字相同(虽然ClickHouse并不强制要求路径中的表名称和物理表名相同);而replica_name的作用是定义在ZooKeeper中创建的副本名称,该名称是区分不同副本实例的唯一标识。一种约定成俗的命名方式是使用所在服务器的域名称。
-
对于zk_path而言,同一张数据表的同一个分片的不同副本,应该定义相同的路径;
-
而对于replica_name而言,同一张数据表的同一个分片的不同副本,应该定义不同的名称
建表时必须在各自指定服务器节点上建
在任何一台节点上,插入数据, 在其他节点上的副本都能同步数据
(1)一个分片 , 多个副本表
-- lixnu01 机器
create table tb_demo1 (
id Int8 ,
name String)engine=ReplicatedMergeTree('/clickhouse/tables/01/tb_demo1', 'linux01')
order by id ;
-- lixnu02 机器
create table tb_demo1 (
id Int8 ,
name String)engine=ReplicatedMergeTree('/clickhouse/tables/01/tb_demo1', 'linux02')
order by id ;
-- lixnu03 机器
create table tb_demo1 (
id Int8 ,
name String)engine=ReplicatedMergeTree('/clickhouse/tables/01/tb_demo1', 'linux03')
order by id ;
查看zookeeper中的内容
[zk: localhost:2181(CONNECTED) 0] ls /
[a, zookeeper, clickhouse, DNS, datanode1, server1, hbase]
[zk: localhost:2181(CONNECTED) 1] ls /clickhouse
[tables, task_queue]
[zk: localhost:2181(CONNECTED) 2] ls /clickhouse/tables
[01]
[zk: localhost:2181(CONNECTED) 3] ls /clickhouse/tables/01
[tb_demo1]
[zk: localhost:2181(CONNECTED) 4] ls /clickhouse/tables/01/tb_demo1
[metadata, temp, mutations, log, leader_election, columns, blocks, nonincrement_block_numbers, replicas, quorum, block_numbers]
[zk: localhost:2181(CONNECTED) 5] ls /clickhouse/tables/01/tb_demo1/replicas
[linux02, linux03, linux01]
SELECT *
FROM system.zookeeper
WHERE path = '/' ;
(2)两个分片 , 一个分片有副本一个分片没有副本
在哪个分片上插入数据,数据就在那个分片上,另一个分片上查不出来
-- lixnu01 机器
create table tb_demo2 (
id Int8 ,
name String)engine=ReplicatedMergeTree('/clickhouse/tables/01/tb_demo2', 'linux01')
order by id ;
-- lixnu02 机器
create table tb_demo2 (
id Int8 ,
name String)engine=ReplicatedMergeTree('/clickhouse/tables/01/tb_demo2', 'linux02')
order by id ;
-- lixnu03 机器
create table tb_demo2 (
id Int8 ,
name String)engine=ReplicatedMergeTree('/clickhouse/tables/02/tb_demo2', 'linux03')
order by id ;
6、分布式引擎
要使用分布式引擎也需要先将zookeeper配置好。其本质还是借助zookeeper通信。
Distributed表引擎是分布式表的代名词,它自身不存储任何数据,而是作为数据分片的透明代理,能够自动路由数据至集群中的各个节点,所以Distributed表引擎需要和其他数据表引擎一起协同工作。
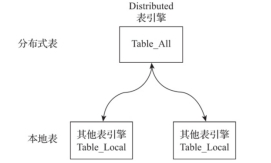
一般使用分布式表的目的有两种,
-
一种是表存储多个副本并且有大量的并发操作,我们可以使用分布式表来分摊请求压力解决并发问题
-
一种是表特别大有多个切片组成 ,并且每切片数据也可以存储数据副本
-
本地表:通常以_local为后缀进行命名。本地表是承接数据的载体,可以使用非Distributed的任意表引擎,一张本地表对应了一个数据分片
-
分布式表:通常以_all为后缀进行命名。分布式表只能使用Distributed表引擎,它与本地表形成一对多的映射关系,日后将通过分布式表代理操作多张本地表。
ENGINE = Distributed(cluster, database, table [,sharding_key])
-
cluster:集群名称,与集群配置中的自定义名称相对应。在对分布式表执行写入和查询的过程中,它会使用集群的配置信息来找到相应的host节点。
-
database和table:分别对应数据库和表的名称,分布式表使用这组配置映射到本地表。
-
sharding_key:分片键,选填参数。在数据写入的过程中,分布式表会依据分片键的规则,将数据分布到各个host节点的本地表。
(1)配置分片和副本集群
vi /etc/clickhouse-server/config.xml
依照下面的样例,根据自己的需求配置。注意一个主机只使用一次
<!-- 搜索remote_servers -->
<remote_servers>
<cluster1>
<!-- 集群名为cluster1 整个集群中每个表有三个分片,分别在lx01 lx02 lx03上 -->
<shard>
<replica>
<host>linux01</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>linux02</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>linux03</host>
<port>9000</port>
</replica>
</shard>
</cluster1>
<cluster2>
<!-- 集群名为cluster2 一个切片 三个副本 -->
<shard>
<replica>
<host>linux01</host>
<port>9000</port>
</replica>
<replica>
<host>linux02</host>
<port>9000</port>
</replica>
<replica>
<host>linux03</host>
<port>9000</port>
</replica>
</shard>
</cluster2>
<!--集群三 多个分片 保留副本 注意一个主机只使用一次 -->
<cluster3>
<shard>
<replica>
<host>doit01</host>
<port>9000</port>
</replica>
<replica>
<host>doit02</host>
<port>9000</port>
</replica>
</shard>
<shard>
<replica>
<host>doit03</host>
<port>9000</port>
</replica>
<replica>
<host>doit04</host>
<port>9000</port>
</replica>
</shard>
</cluster3>
</remote_servers>
(2)创建分布式表
先在配置好的集群上创建本地表,再创建分布式表
-- 创建本地表
create table tb_demo4 on cluster cluster2(
id Int8 ,
name String
)engine=MergeTree()
order by id ;
-- 创建分布式表
create table demo4_all on cluster cluster2 engine=Distributed('cluster2','default','tb_demo4',id) as tb_demo4 ;
注意:往分布式表中添加数据 ,三个副本表都会有数据, 而往某个服务器本地表中添加数据,只是当前服务器本地表与分布式表会有数据,其他服务器上的本地表与分布式表都不会有数据
-
表只有1个分片,有多个副本的时候 , 可以不使用分布式表
-
有多个分片的时候使用分布式表,给分片分配数据 ,防止数据倾斜
7、分布式DDL
ClickHouse支持集群模式,一个集群拥有1到多个节点。CREATE、ALTER、DROP、RENMAE及TRUNCATE这些DDL语句,都支持分布式执行。这意味着,如果在集群中任意一个节点上执行DDL语句,那么集群中的 每个节点都会以相同的顺序执行相同的语句。这项特性意义非凡,它就如同批处理命令一样,省去了需要依次去单个节点执行DDL的烦恼。将一条普通的DDL语句转换成分布式执行十分简单,只需加上ON CLUSTER cluster_name声明即可。例如,执行下面的语句后将会对 ch_cluster集群内的所有节点广播这条DDL语句:
-- 建表 on cluster cluster1
create table tb_demo3 on cluster cluster1(
id Int8 ,
name String
)engine=MergeTree()
order by id ;
-- 删除集群中所有的本地表或者是分布式表
drop table if exists tb_demo3 on cluster cluster1;
-- 修改集群中的表结构
alter table t3 on cluster cluster1 add column age Int8 ;
8、分布式协同原理
副本协同的核心流程主要有INSERT、MERGE、MUTATION和ALTER四种,分别对应了数据写入、分区合并、数据修改和元数据修改。INSERT和ALTER查询是分布式执行的。借助 ZooKeeper的事件通知机制,多个副本之间会自动进行有效协同,但是它们不会使用ZooKeeper存储任何分区数据。而其他查询并不支持分布式执行,包括SELECT、CREATE、DROP、RENAME和ATTACH。例如,为了创建多个副本,我们需要分别登录每个ClickHouse节点。接下来,会依次介绍上述流程的工作机理。为了便于理解,我们先来整体认识一下各个流程的介绍方法。
(1)insert原理
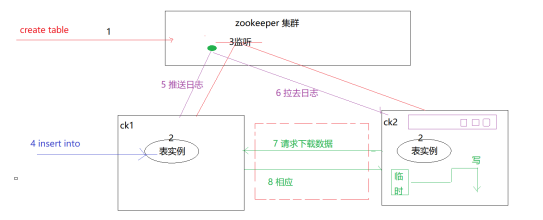
(2)Merge原理
无论MERGE操作从哪个副本发起,其合并计划都会交由主副本来制定,和insert一样
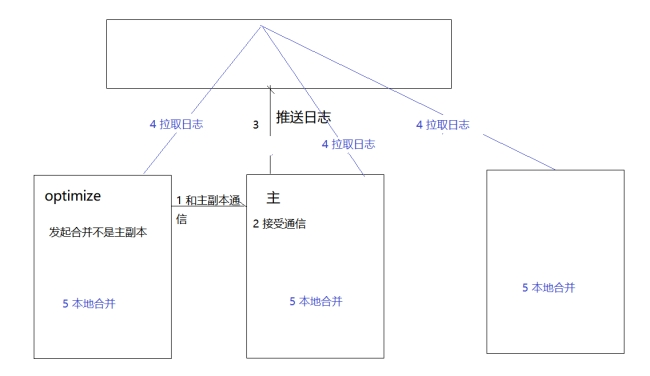
(3)mutation原理
alter table x update name=zss where
alter table x delete where
当对ReplicatedMergeTree执行ALTER DELETE或者ALTER UPDATE操作的时候,即会进入MUTATION部分的逻辑,它的核心流程如图
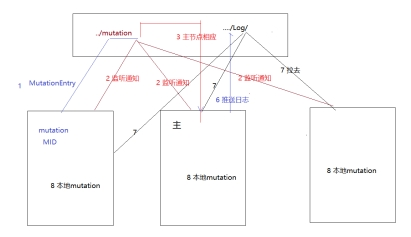
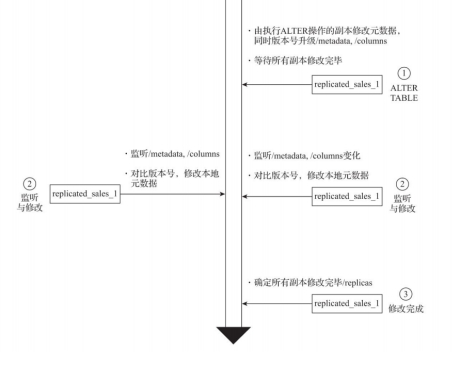
(4)alter原理
当对ReplicatedMergeTree执行ALTER操作进行元数据修改的时候,即会进入ALTER部
分的逻辑,例如增加、删除表字段等。
五、应用案例
最后
以上就是沉默含羞草最近收集整理的关于ClickHouse基本语法一、基本语法二、查询语法三、函数四、分布式五、应用案例的全部内容,更多相关ClickHouse基本语法一、基本语法二、查询语法三、函数四、分布式五、应用案例内容请搜索靠谱客的其他文章。








发表评论 取消回复