一. 光流法
2. LK光流
2.0 文献阅读
Lucas-Kanade 20 Years On: A Unifying Framework
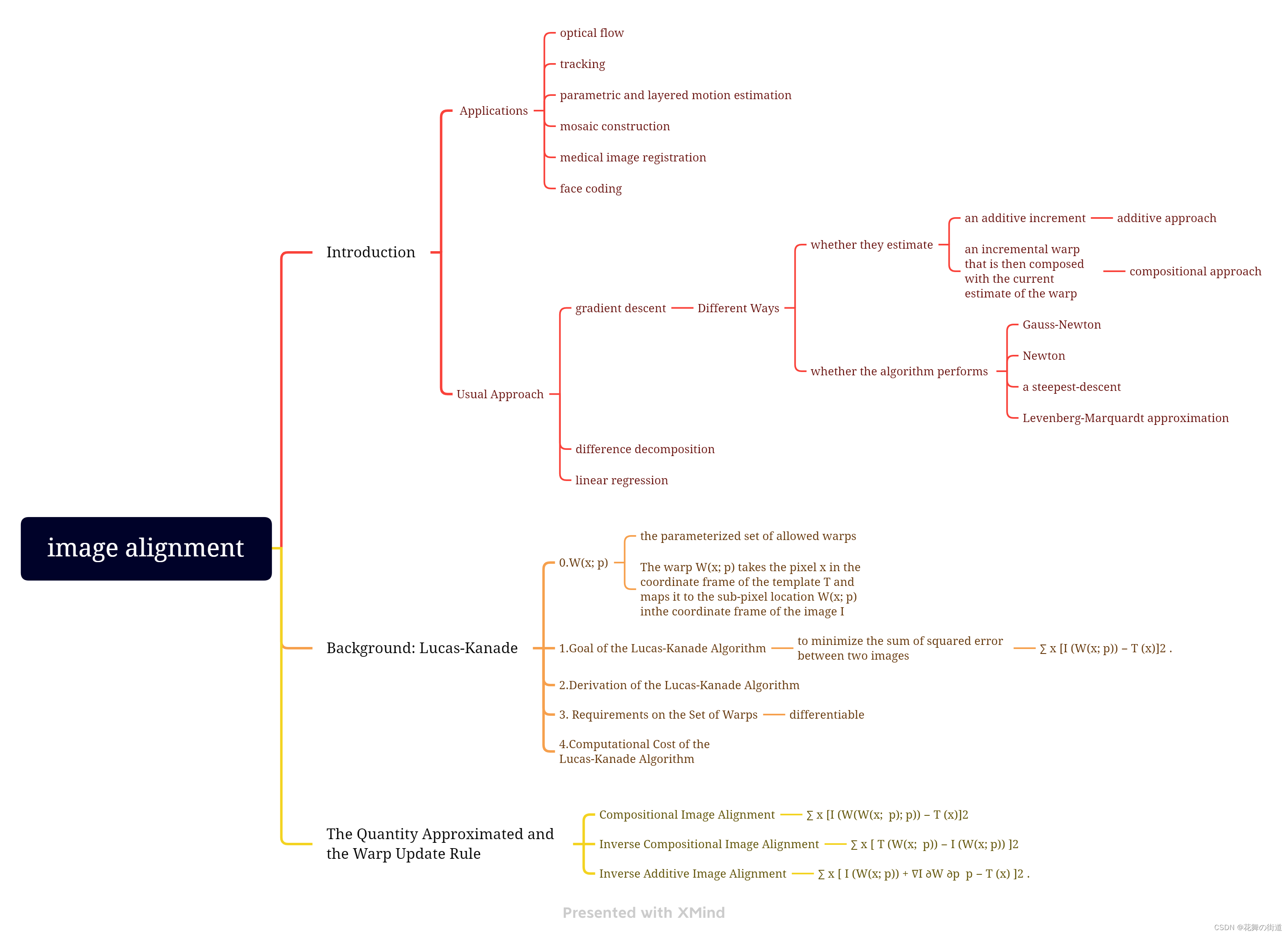
就看了这些,MD英文文献看的太费劲了,算法什么的一点都看不懂。。。。。
还是借鉴以下别人的吧。。。
http://t.csdn.cn/4mzHg
2.1文献综述
1)光流法分类
| 分类 | 实例 | 复杂度 | 应用场景 |
|---|---|---|---|
| Forwards Additive(正向加性) | Lucas-Kanade (1981) | O ( n 2 N + n 3 ) O(n^2N+n^3) O(n2N+n3) | Any warp |
| Forwards Compositional(正向组合) | Shum-Szeliski (2000) | O ( n 2 N + n 3 ) O(n^2N+n^3) O(n2N+n3) | Any semi-group |
| Inverse Additive(逆向加性) | Hager-Belhumeur (1998) | O ( n N + n 3 ) O(nN+n^3) O(nN+n3) | Simple linear 2D + |
| Inverse Compositional(逆向组合) | Baker-Matthews (2001) | O ( n N + n k + k 3 ) O(nN+nk+k^3) O(nN+nk+k3) | Any group |
2)在compositional 中,为什么有时候需要做原始图像的wrap?该wrap 有何物理意义?
算法的目标是有一个模板图像
T
(
x
)
T(x)
T(x) 和一个原始图像 $ I(x)$ ,要求给原始图像做一个wrap变换,并求这个变换函数
W
(
x
;
p
)
W(x;p)
W(x;p) ,使得经过变换候的图像
I
(
W
(
x
;
p
)
)
I(W(x;p))
I(W(x;p)) 与模板图像
T
T
T 之间的差异最小。用数学表达式来描述上边的过程就是:
a
r
g
m
i
n
∑
x
∣
∣
I
(
W
(
x
;
p
)
)
−
T
(
x
)
∣
∣
2
arg;min sum_x||I(W(x;p))-T(x)||^2
argminx∑∣∣I(W(x;p))−T(x)∣∣2
3)forward 和inverse 有何差别?
如果模板中有很多噪声,则应该使用正向算法。如果输入图像中噪声更多,那就采用逆向算法。逆向算法只用计算一次Hessian矩阵,而正向算法需要在每次迭代过程中都计算一遍Hessian矩阵。因此,逆向算法更高效,计算量较小。
正向法在第二个图像 I 2 I_2 I2处求梯度,而逆向法直接用第一个图像 I 1 I_1 I1处的梯度来代替。正向法和逆向法的目标函数也不一样。
2.2 ,2.3光流的实现
1从最小二乘角度来看,每个像素的误差怎么定义?
e
r
r
o
r
=
I
1
(
x
i
,
y
i
)
−
I
2
(
x
i
+
Δ
x
i
,
y
i
+
Δ
y
i
)
error = I_1(x_i, y_i)-I_2(x_i +Delta x_i, y_i+Delta y_i)
error=I1(xi,yi)−I2(xi+Δxi,yi+Δyi)
2误差相对于自变量的导数如何定义?
待估计的变量为 Δ x i Delta x_i Δxi 与 Δ y i Delta y_i Δyi
所以:
∂
e
∂
Δ
x
i
=
−
∂
I
2
∂
Δ
x
i
frac{partial e}{partial Delta x_i} = -frac{partial I_2}{partial Delta x_i}
∂Δxi∂e=−∂Δxi∂I2
∂ e ∂ Δ y i = − ∂ I 2 ∂ Δ y i frac{partial e}{partial Delta y_i} = -frac{partial I_2}{partial Delta y_i} ∂Δyi∂e=−∂Δyi∂I2
因为图像中每个点之间的像素值是离散的,不能直接用微分来求导,这里我们用差分来代替微分求导,所以用中心差分方式来进行求导计算。
f
(
x
+
1
,
y
)
=
I
2
(
x
i
+
Δ
x
i
+
1
,
y
i
+
Δ
y
i
)
f ( x + 1 , y ) = I_2 ( x_i + Δ x_i + 1 , y_i + Δ y_i )
f(x+1,y)=I2(xi+Δxi+1,yi+Δyi)
f ( x − 1 , y ) = I 2 ( x i + Δ x i − 1 , y i + Δ y i ) f ( x − 1 , y ) = I_2 ( x_i + Δ x_i − 1 , y_i + Δ y_i ) f(x−1,y)=I2(xi+Δxi−1,yi+Δyi)
一阶泰勒展开:
f
(
x
+
1
,
y
)
=
f
(
x
,
y
)
+
f
′
(
x
)
,
f
(
x
−
1
,
y
)
=
f
(
x
,
y
)
−
f
′
(
x
)
.
f(x+1,y)=f(x,y)+f'(x),;;f(x−1,y)=f(x,y)−f'(x).
f(x+1,y)=f(x,y)+f′(x),f(x−1,y)=f(x,y)−f′(x).
得:
f
′
(
x
)
=
f
(
x
+
1
,
y
)
−
f
(
x
−
1
,
y
)
2
f'(x)=frac{f(x+1,y)−f(x−1,y)}{2}
f′(x)=2f(x+1,y)−f(x−1,y)
同理:
f
′
(
y
)
=
f
(
x
,
y
+
1
)
−
f
(
x
,
y
−
1
)
2
f'(y)=frac{f(x,y+1)−f(x,y-1)}{2}
f′(y)=2f(x,y+1)−f(x,y−1)
因此:
∂
e
∂
Δ
x
i
=
−
∂
I
2
∂
Δ
x
i
=
−
I
2
(
x
i
+
Δ
x
i
+
1
,
y
i
+
Δ
y
i
)
−
I
2
(
x
i
+
Δ
x
i
−
1
,
y
i
+
Δ
y
i
)
2
frac{partial e}{partial Delta x_i} = -frac{partial I_2}{partial Delta x_i} = -frac{I_2 ( x_i + Δ x_i + 1 , y_i + Δ y_i )- I_2 ( x_i + Δ x_i − 1 , y_i + Δ y_i )}{2}
∂Δxi∂e=−∂Δxi∂I2=−2I2(xi+Δxi+1,yi+Δyi)−I2(xi+Δxi−1,yi+Δyi)
∂ e ∂ Δ y i = − ∂ I 2 ∂ Δ y i = − I 2 ( x i + Δ x i , y i + Δ y i + 1 ) − I 2 ( x i + Δ x i , y i + Δ y i − 1 ) 2 frac{partial e}{partial Delta y_i} = -frac{partial I_2}{partial Delta y_i} = -frac{I_2 ( x_i + Δ x_i , y_i + Δ y_i+1 )-I_2 ( x_i + Δ x_i , y_i + Δ y_i -1)}{2} ∂Δyi∂e=−∂Δyi∂I2=−2I2(xi+Δxi,yi+Δyi+1)−I2(xi+Δxi,yi+Δyi−1)
3代码
void OpticalFlowSingleLevel(
const Mat &img1,
const Mat &img2,
const vector<KeyPoint> &kp1,
vector<KeyPoint> &kp2,
vector<bool> &success,
bool inverse
) {
// parameters
int half_patch_size = 4;
int iterations = 10;
bool have_initial = !kp2.empty();
for (size_t i = 0; i < kp1.size(); i++) {
auto kp = kp1[i];
double dx = 0, dy = 0; // dx,dy need to be estimated
if (have_initial) {
dx = kp2[i].pt.x - kp.pt.x;
dy = kp2[i].pt.y - kp.pt.y;
}
double cost = 0, lastCost = 0;
bool succ = true; // indicate if this point succeeded
// Gauss-Newton iterations
for (int iter = 0; iter < iterations; iter++) {
Eigen::Matrix2d H = Eigen::Matrix2d::Zero();
Eigen::Vector2d b = Eigen::Vector2d::Zero();
cost = 0;
// 检查是否在边缘
if (kp.pt.x + dx <= half_patch_size || kp.pt.x + dx >= img1.cols - half_patch_size ||
kp.pt.y + dy <= half_patch_size || kp.pt.y + dy >= img1.rows - half_patch_size) { // go outside
succ = false;
break;
}
// compute cost and jacobian x和y都是[-4,3]
for (int x = -half_patch_size; x < half_patch_size; x++)
for (int y = -half_patch_size; y < half_patch_size; y++) {
// TODO START YOUR CODE HERE (~8 lines)
double error;
error = GetPixelValue(img1, kp.pt.x + x, kp.pt.y + y) - GetPixelValue(img2, kp.pt.x +x + dx, kp.pt.y + y+ dy);
Eigen::Vector2d J; // Jacobian
if (inverse == false) {
// Forward Jacobian
J = -1.0 * Eigen::Vector2d(
0.5 * (GetPixelValue(img2, kp.pt.x + dx + x + 1, kp.pt.y + dy + y) -
GetPixelValue(img2, kp.pt.x + dx + x - 1, kp.pt.y + dy + y)),
0.5 * (GetPixelValue(img2, kp.pt.x + dx + x, kp.pt.y + dy + y + 1) -
GetPixelValue(img2, kp.pt.x + dx + x, kp.pt.y + dy + y - 1))
);
} else {
// Inverse Jacobian
// NOTE this J does not change when dx, dy is updated, so we can store it and only compute error
J = -1.0 * Eigen::Vector2d(
0.5 * (GetPixelValue(img1, kp.pt.x + dx + x + 1, kp.pt.y + dy + y) -
GetPixelValue(img1, kp.pt.x + dx + x - 1, kp.pt.y + dy + y)),
0.5 * (GetPixelValue(img1, kp.pt.x + dx + x, kp.pt.y + dy + y + 1) -
GetPixelValue(img1, kp.pt.x + dx + x, kp.pt.y + dy + y - 1))
);
}
if (inverse == false || iter == 0){
H += J * J.transpose();
}
b += - J * error;
cost += error * error;
// TODO END YOUR CODE HERE
}
// compute update
// TODO START YOUR CODE HERE (~1 lines)
Eigen::Vector2d update = H.ldlt().solve(b);
// TODO END YOUR CODE HERE
if (isnan(update[0])) {
// sometimes occurred when we have a black or white patch and H is irreversible
cout << "update is nan" << endl;
succ = false;
break;
}
if (iter > 0 && cost > lastCost) {
cout << "cost increased: " << cost << ", " << lastCost << endl;
break;
}
// update dx, dy
dx += update[0];
dy += update[1];
lastCost = cost;
succ = true;
}
success.push_back(succ);
// set kp2
if (have_initial) {
kp2[i].pt = kp.pt + Point2f(dx, dy);
} else {
KeyPoint tracked = kp;
tracked.pt += cv::Point2f(dx, dy);
kp2.push_back(tracked);
}
}
}
第一层循环遍历第一张图的每个关键点与第二张图计算dx与dy
第二层循环高斯牛顿迭代
第三层循环每个关键点的图像块遍历计算雅可比,海森阵等
求解kp2
2.4推广至金字塔
void OpticalFlowMultiLevel(
const Mat &img1,
const Mat &img2,
const vector<KeyPoint> &kp1,
vector<KeyPoint> &kp2,
vector<bool> &success,
bool inverse) {
// parameters
int pyramids = 4; //金字塔层数
double pyramid_scale = 0.3; //倍数0.5
double scales[] = {1.0, 0.3, 0.09, 0.027};
// create pyramids
vector<Mat> pyr1, pyr2; // image pyramids 注意这里是个vector
// TODO START YOUR CODE HERE (~8 lines)
for (int i = 0; i < pyramids; i++)
{
if (i == 0)
{
pyr1.push_back(img1);
pyr2.push_back(img2);
}
else
{
Mat img1_pyr, img2_pyr;
//resize函数改变图像的大小
cv::resize(pyr1[i -1], img1_pyr, cv::Size(pyr1[i - 1].cols * pyramid_scale, pyr1[i - 1].rows * pyramid_scale));
cv::resize(pyr2[i -1], img2_pyr, cv::Size(pyr2[i - 1].cols * pyramid_scale, pyr2[i - 1].rows * pyramid_scale));
pyr1.push_back(img1_pyr);
pyr2.push_back(img2_pyr);
}
}
// TODO END YOUR CODE HERE
// coarse-to-fine LK tracking in pyramids
// 这里的关键:上一层的估计值做下一层的初始值
// TODO START YOUR CODE HERE
vector<KeyPoint> kp1_pyr, kp2_pyr;
for (auto &kp:kp1)
{
auto kp_top = kp;
kp_top.pt *= scales[pyramids -1];
kp1_pyr.push_back(kp_top);
kp2_pyr.push_back(kp_top);
}
for (int level = pyramids -1; level >= 0; level--)
{
success.clear();
OpticalFlowSingleLevel(pyr1[level], pyr2[level], kp1_pyr, kp2_pyr, success, inverse);
if (level > 0)
{
for (auto &kp:kp1_pyr){
kp.pt /= pyramid_scale;
}
for (auto &kp:kp2_pyr){
kp.pt /= pyramid_scale;
}
}
}
for (auto &kp:kp2_pyr)
{
kp2.push_back(kp);
}
// TODO END YOUR CODE HERE
// don't forget to set the results into kp2
}
二. 3直接法
1)单层直接法
算法步骤:
1在参考图像(reference)中随机选取1000个点(cv::RNG),在深度图像(disparity)中得到深度值( d e p t h = f ∗ b d depth = frac{f*b}{d} depth=df∗b,f与b为相机内参,d为视差且最小为一个像素)。将深度信息与随机取到的1000个点存入容器。
2将参考图像的像素提取出来,可以得到像素坐标,由 p 1 = 1 Z 1 K P 1 p_1=frac{1}{Z_1}KP_1 p1=Z11KP1,得 P 1 = Z 1 K − 1 p 1 P_1=Z_1K^{-1}p_1 P1=Z1K−1p1,即将像素坐标转化到相机坐标。第一个相机到第二个相机的变换为R,t,所以当前图像的相机坐标 P 2 = T 21 P 1 P_2 = T_{21} P_1 P2=T21P1 。得到第二张图像的相机坐标后,转换到像素坐标系。
3.求解误差,雅可比矩阵,H与b,得到扰动,然后算得T。
代码实现:
void DirectPoseEstimationSingleLayer(
const cv::Mat &img1,
const cv::Mat &img2,
const VecVector2d &px_ref,
const vector<double> depth_ref,
Sophus::SE3d &T21
) {
// parameters
int half_patch_size = 4;
int iterations = 100;
double cost = 0, lastCost = 0;
int nGood = 0; // good projections 最后求平均误差用这个标记在图像内的点
VecVector2d goodProjection;
for (int iter = 0; iter < iterations; iter++) {
nGood = 0;
goodProjection.clear();
goodProjection.resize(px_ref.size());
// Define Hessian and bias
Matrix6d H = Matrix6d::Zero(); // 6x6 Hessian
Vector6d b = Vector6d::Zero(); // 6x1 bias
for (size_t i = 0; i < px_ref.size(); i++) {
// compute the projection in the second image
// TODO START YOUR CODE HERE
Eigen::Vector3d point_ref = depth_ref[i] * Eigen::Vector3d((px_ref[i][0] - cx)/fx, (px_ref[i][1] - cy)/fy, 1);
Eigen::Vector3d point_cur = T21 * point_ref;
if(point_cur[2] < 0)
{
continue;
}
float u = fx * point_cur[0]/point_cur[2] + cx;
float v = fy * point_cur[1]/point_cur[2] + cy;
if (u < half_patch_size || u > img1.cols - half_patch_size || v < half_patch_size || v > img1.rows - half_patch_size)
{
continue;
}
goodProjection[i] = Eigen::Vector2d(u, v);
double X = point_cur[0];
double Y = point_cur[1];
double Z = point_cur[2];
double Z_2 = Z * Z;
nGood++;
for (int x = -half_patch_size; x < half_patch_size; x++)
{
for (int y = -half_patch_size; y < half_patch_size; y++)
{
double error;
error = GetPixelValue(img1, px_ref[i][0] + x, px_ref[i][1] + y) - GetPixelValue(img2, u + x, v + y);
Matrix26d J_img_pixel;
J_img_pixel(0, 0) = fx * Z_inv;
J_img_pixel(0, 1) = 0;
J_img_pixel(0, 2) = -fx * X * Z_2inv;
J_img_pixel(0, 3) = -fx * X * Y * Z_2inv;
J_img_pixel(0, 4) = fx + fx * X * X * Z_2inv;
J_img_pixel(0, 5) = -fx * Y * Z_inv;
J_img_pixel(1, 0) = 0;
J_img_pixel(1, 1) = fy * Z_inv;
J_img_pixel(1, 2) = -fy * Y * Z_2inv;
J_img_pixel(1, 3) = -fy - fy * Y * Y * Z_2inv;
J_img_pixel(1, 4) = fy * X * Y * Z_2inv;
J_img_pixel(1, 5) = fy * X * Z_inv;
Eigen::Vector2d J_img_descent;
J_img_descent = Eigen::Vector2d(0.5 * (GetPixelValue(img2, u + 1 + x, v + y) - GetPixelValue(img2, u - 1 + x, v + y)),
0.5 * (GetPixelValue(img2, u + x, v + 1 + y) - GetPixelValue(img2, u + x, v - 1 + y)));
Vector6d J = (J_img_descent.transpose() * J_img_pixel).transpose();
J = -J;
H += J * J.transpose();
b += -error * J;
cost += error * error;
}
}
// END YOUR CODE HERE
}
// solve update and put it into estimation
// TODO START YOUR CODE HERE
Vector6d update = H.ldlt().solve(b);
T21 = Sophus::SE3d::exp(update) * T21;
// END YOUR CODE HERE
cost /= nGood;
if (isnan(update[0])) {
// sometimes occurred when we have a black or white patch and H is irreversible
cout << "update is nan" << endl;
break;
}
if (iter > 0 && cost > lastCost) {
cout << "cost increased: " << cost << ", " << lastCost << endl;
break;
}
lastCost = cost;
cout << "cost = " << cost << ", good = " << nGood << endl;
}
cout << "good projection: " << nGood << endl;
cout << "T21 = n" << T21.matrix() << endl;
// in order to help you debug, we plot the projected pixels here
cv::Mat img1_show, img2_show;
cv::cvtColor(img1, img1_show, COLOR_GRAY2BGR);
cv::cvtColor(img2, img2_show, COLOR_GRAY2BGR);
for (auto &px: px_ref) {
cv::rectangle(img1_show, cv::Point2f(px[0] - 2, px[1] - 2), cv::Point2f(px[0] + 2, px[1] + 2),
cv::Scalar(0, 250, 0));
}
/*
for (auto &px: goodProjection) {
cv::rectangle(img2_show, cv::Point2f(px[0] - 2, px[1] - 2), cv::Point2f(px[0] + 2, px[1] + 2),
cv::Scalar(0, 250, 0));
}
cv::imshow("reference", img1_show);
cv::imshow("current", img2_show);
cv::waitKey();
*/
for (size_t i = 0; i < px_ref.size(); ++i){
Eigen::Vector2d p_ref = px_ref[i];
Eigen::Vector2d p_cur = goodProjection[i];
if (p_cur(0) > 0 && p_cur(1) > 0 && p_ref(0) > 0 && p_ref(1) > 0){
cv::rectangle(img2_show, cv::Point2f(p_cur[0] - 2, p_cur[1] - 2),
cv::Point2f(p_cur[0] + 2, p_cur[1] + 2),
cv::Scalar(0, 250, 0));
cv::line(img2_show, cv::Point2f(p_ref(0), p_ref(1)), cv::Point2f(p_cur(0), p_cur(1)), cv::Scalar(0,255,0));
}
}
cv::imshow("reference", img1_show);
cv::imshow("current", img2_show);
cv::waitKey(1000);
}
Tips:1EIGEN_STATIC_ASSERT_SAME_MATRIX_SIZE编译时报这个错误的大概率矩阵或向量维度有误。
2段错误(核心已转储) 执行时报这个错误大概率代码写错了,仔细检查代码。
3运行的效果不太好大概率算法有误,检查算法是否正确。
2)多层直接法
void DirectPoseEstimationMultiLayer(
const cv::Mat &img1,
const cv::Mat &img2,
const VecVector2d &px_ref,
const vector<double> depth_ref,
Sophus::SE3d &T21
) {
// parameters
int pyramids = 4;
double pyramid_scale = 0.5;
double scales[] = {1.0, 0.5, 0.25, 0.125};
// create pyramids
vector<cv::Mat> pyr1, pyr2; // image pyramids
// TODO START YOUR CODE HERE
for (int i = 0; i < pyramids; i++)
{
if (i == 0)
{
pyr1.push_back(img1);
pyr2.push_back(img2);
}
else
{
cv::Mat img1_pyr, img2_pyr;
cv::resize(pyr1[i - 1], img1_pyr, cv::Size(pyr1[i - 1].cols * pyramid_scale, pyr1[i - 1].rows * pyramid_scale));
cv::resize(pyr2[i - 1], img2_pyr, cv::Size(pyr2[i - 1].cols * pyramid_scale, pyr2[i - 1].rows * pyramid_scale));
pyr1.push_back(img1_pyr);
pyr2.push_back(img2_pyr);
}
}
// END YOUR CODE HERE
double fxG = fx, fyG = fy, cxG = cx, cyG = cy; // backup the old values
for (int level = pyramids - 1; level >= 0; level--) {
VecVector2d px_ref_pyr; // set the keypoints in this pyramid level
for (auto &px: px_ref) {
px_ref_pyr.push_back(scales[level] * px);
}
// TODO START YOUR CODE HERE
// scale fx, fy, cx, cy in different pyramid levels
fx = fxG * scales[level];
fy = fyG * scales[level];
cx = cxG * scales[level];
cy = cyG * scales[level];
// END YOUR CODE HERE
DirectPoseEstimationSingleLayer(pyr1[level], pyr2[level], px_ref_pyr, depth_ref, T21);
}
}
三.4*使用光流计算视差
视差图:以图像中任意一幅图为基准,其大小为基准图像的大小,元素值为视差值的图像。
所以给定视差图像disparity,取出其中的像素值为真实视差
估计视差为两张图像之间相同像素点的水平坐标之差。
double AnalyzeDisparityRMSE(const cv::Mat &left_img,
const cv::Mat &right_img,
cv::Mat &img2,
const cv::Mat &disparity_img,
const vector<KeyPoint> &kp1,
const vector<KeyPoint> &kp2,
const vector<bool> &success)
{
int count = 0;
vector<double> disparity_est;
vector<double> cost;
// analyze disparity root mean square error
cv::cvtColor(right_img, img2, COLOR_GRAY2BGR);
for (int i = 0; i < kp2.size(); i++) {
if (success[i]) {
// draw disparity results
cv::circle(img2, kp2[i].pt, 2, cv::Scalar(0, 250, 0), 2);
cv::line(img2, kp1[i].pt, cv::Point2f(kp2[i].pt.x, kp1[i].pt.y), cv::Scalar(0, 250, 0));
// estimated disparity
double dis_est = kp2[i].pt.x - kp1[i].pt.x;
disparity_est.push_back(dis_est);
// ground truth disparity
float u = kp1[i].pt.x;
float v = kp1[i].pt.y;
double disparity_gt = GetPixelValue(disparity_img, u, v);
cost.push_back(dis_est-disparity_gt);
}
}
double sum = accumulate(cost.begin(),cost.end(),0.0);
double error = sum /cost.size();
return error;
}
Ps:突然发现前面的知识有点忘了。。。。。。
最后
以上就是激昂飞鸟最近收集整理的关于视觉SLAM十四讲作业练习(6)的全部内容,更多相关视觉SLAM十四讲作业练习(6)内容请搜索靠谱客的其他文章。








发表评论 取消回复