第一步:创建dfs.hosts.exclude配置文件(黑名单)
在主节点执行以下命令:
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim dfs.hosts.exclude
在dfs.hosts.exclude文件中添加要退役的节点主机名)
第二步:编辑namenode所在节点的hdfs-site.xml
在主节点执行以下命令:
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim hdfs-site.xml
添加如下配置:
`<property>`
`<name>`dfs.hosts.exclude`</name>`
`<value>`/export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop/dfs.hosts.exclude`</value>`
`</property>`
第三步:刷新namenode,刷新resourceManager
在主节点执行以下命令:
hdfs dfsadmin -refreshNodes //刷新namenode
yarn rmadmin -refreshNodes //刷新resourceManager
第四步:查看web浏览界面
浏览器访问:
http://node01:50070/dfshealth.html#tab-datanode
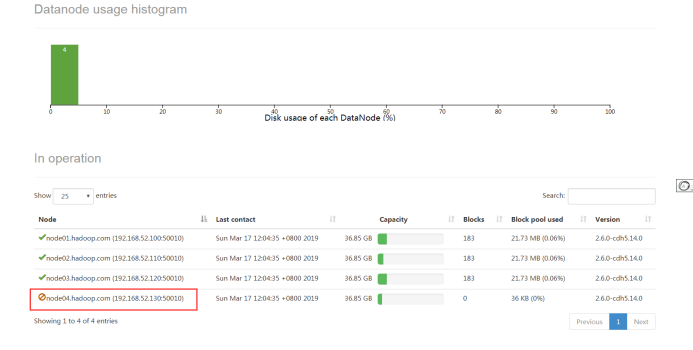 第五步:节点退役完成,停止该节点进程
第五步:节点退役完成,停止该节点进程
等待退役节点状态为decommissioned(所有块已经复制完成),停止该节点及节点资源管理器。注意:如果副本数是3,服役的节点小于等于3,是不能退役成功的,需要修改副本数后才能退役。

在主节点执行以下命令:
cd /export/servers/hadoop-2.6.0-cdh5.14.0
sbin/hadoop-daemon.sh stop datanode
sbin/yarn-daemon.sh stop nodemanager
第六步:从include文件中删除退役节点
在主节点执行以下命令:
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim dfs.hosts
修改dfs.hosts文件内容,删除退役节点
node01
node02
node03
在主节点执行以下命令:
hdfs dfsadmin -refreshNodes //刷新namenode
yarn rmadmin -refreshNodes //刷新resourceManager
第七步:从namenode的slaves文件中删除退役节点
在主节点执行以下命令:
cd /export/servers/hadoop-2.6.0-cdh5.14.0/etc/hadoop
vim slaves
修改slaves文件内容,删除退役节点
node01
node02
node03
第八步:如果数据负载不均衡,执行以下命令进行均衡负载
主节点执行以下命令:
cd /export/servers/hadoop-2.6.0-cdh5.14.0/
sbin/start-balancer.sh //执行负载均衡操作
最后就是大写的
OVER!
最后
以上就是酷炫冬天最近收集整理的关于大数据-hdfs-退役数据旧节点-方法步骤OVER!的全部内容,更多相关大数据-hdfs-退役数据旧节点-方法步骤OVER内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复