Spark+HBase分布式批量上传海量本地图片
- 集群架构
3台PC机都是4G的内存,Master和一个Worker是i5处理器,一个Worker为i3处理器
218.199.92.225
fang-ubuntu(Master)
218.199.92.226
fei-ubuntu(Worker)
218.199.92.227
kun-ubuntu(Worker)软件环境
Ubuntu1604
Hadoop-2.7.2
Spark-1.6.1
Scala-2.10.5
HBase-1.2.4
Java 1.8.0_77
由于有200G的图像数据放在本地数据库,需要上传的HBase数据库中进行处理,考虑到速度的影响,尝试使用Spark分布式批量上传图片数据。
- 集群搭建
由于需要用到HDFS,因此需要搭建Hadoop集群,需要搭建HBase集群,需要搭建Spark集群。可以参考我其余两篇博客
Spark on Yarn集群搭建
http://blog.csdn.net/u010638969/article/details/51283216
HBase-1.2.4分布式集群搭建
http://blog.csdn.net/u010638969/article/details/53257879 - 搭建开发环境
程序是在Intellij Idea中编写,因此需要搭建Spark的开发环境
- 安装scala,sbt插件
- Intellij Idea 中spark项目需要导入 spark-assembly-1.6.1-hadoop-2.6.0
- 导入HBase-1.2.4/lib目录中的jar包
- 编写本地测试程序
本地测试程序代码如下:
import org.apache.hadoop.hbase._
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.{SparkConf, SparkContext}
/**
*Created by fang on 16-11-15.
*Write image data into HBase in distributed mode
*/
object HBaseUpLoadImages {
def main(args: Array[String]): Unit = {
//初始化SparkConf并设置AppName,set Master为 local用来本地测试程序
val sparkConf = new SparkConf().setAppName("HBaseUpLoadImages").setMaster("local")
//初始化SparkContext
val sparkContext = new SparkContext(sparkConf)
//读取本地文件系统中的images图片,创建BinaryRDD imagesRDD
val imagesRDD = sparkContext.binaryFiles("file:///home/hadoop/test/images")
//对每个Partition,将图像数据写入HBase中
imagesRDD.foreachPartition {
iter => {
//创建hbaseConfig
val hbaseConfig = HBaseConfiguration.create()
//写入HBase,需要客户端连接zookeeper
hbaseConfig.set("hbase.zookeeper.property.clientPort", "2181")
hbaseConfig.set("hbase.zookeeper.quorum", "fang-ubuntu,fei-ubuntu,kun-ubuntu")
val connection: Connection = ConnectionFactory.createConnection(hbaseConfig);
val tableName = "imagesTable"
//这里需要表提前创建成功
val table: Table = connection.getTable(TableName.valueOf(tableName))
iter.foreach { imageFile =>
//imageRDD中key为image文件路径,value为图像字节数组
val tempPath = imageFile._1.split("/")
val len = tempPath.length
//获取图片名称
val imageName = tempPath(len-1)
//获取图片数据
val imageBinary:scala.Array[scala.Byte]= imageFile._2.toArray()
val put: Put = new Put(Bytes.toBytes(imageName))
put.addImmutable(Bytes.toBytes("imagePath"), Bytes.toBytes("path"), Bytes.toBytes(imageFile._1))
put.addImmutable(Bytes.toBytes("image"), Bytes.toBytes("img"),imageBinary)
//写入HBase中
table.put(put)
}
connection.close()
}
}
sparkContext.stop()
}
//判断表是否已经存在
def isExistTable(tableName: String, connection: Connection) {
val admin: Admin = connection.getAdmin
admin.tableExists(TableName.valueOf(tableName))
}
//创建表
def createTable(tableName: String, columnFamilys: Array[String], connection: Connection): Unit = {
val admin: Admin = connection.getAdmin
if (admin.tableExists(TableName.valueOf(tableName))) {
println("表" + tableName + "已经存在")
return
} else {
val tableDesc: HTableDescriptor = new HTableDescriptor(TableName.valueOf(tableName))
for (columnFaily <- columnFamilys) {
tableDesc.addFamily(new HColumnDescriptor(columnFaily))
}
admin.createTable(tableDesc)
println("创建表成功")
}
}
//向表中添加数据
def addRow(tableName: String, row: Int, columnFaily: String, column: String, value: String, connection: Connection): Unit = {
val table: Table = connection.getTable(TableName.valueOf(tableName))
val put: Put = new Put(Bytes.toBytes(row))
put.addImmutable(Bytes.toBytes(columnFaily), Bytes.toBytes(column), Bytes.toBytes(value))
table.put(put)
}
}在Intellij Idea中以本地模式运行该程序,查看HBase中的表数据,验证是否图片是否上传成功。
4. 编写集群程序上传海量图片
测试程序编写成功后需要提交到集群中并行上传图片数据
代码需要如下修改:
val sparkConf = new SparkConf().setAppName("HBaseUpLoadImages")
//将程序打成jar包提交到集群中运行
./bin/sparkSubmit --master spark://fang-ubuntu:7077 --class HBaseUpLoadImages ~/Document/HBaseUpLoadImages.jar
5. 测试结果
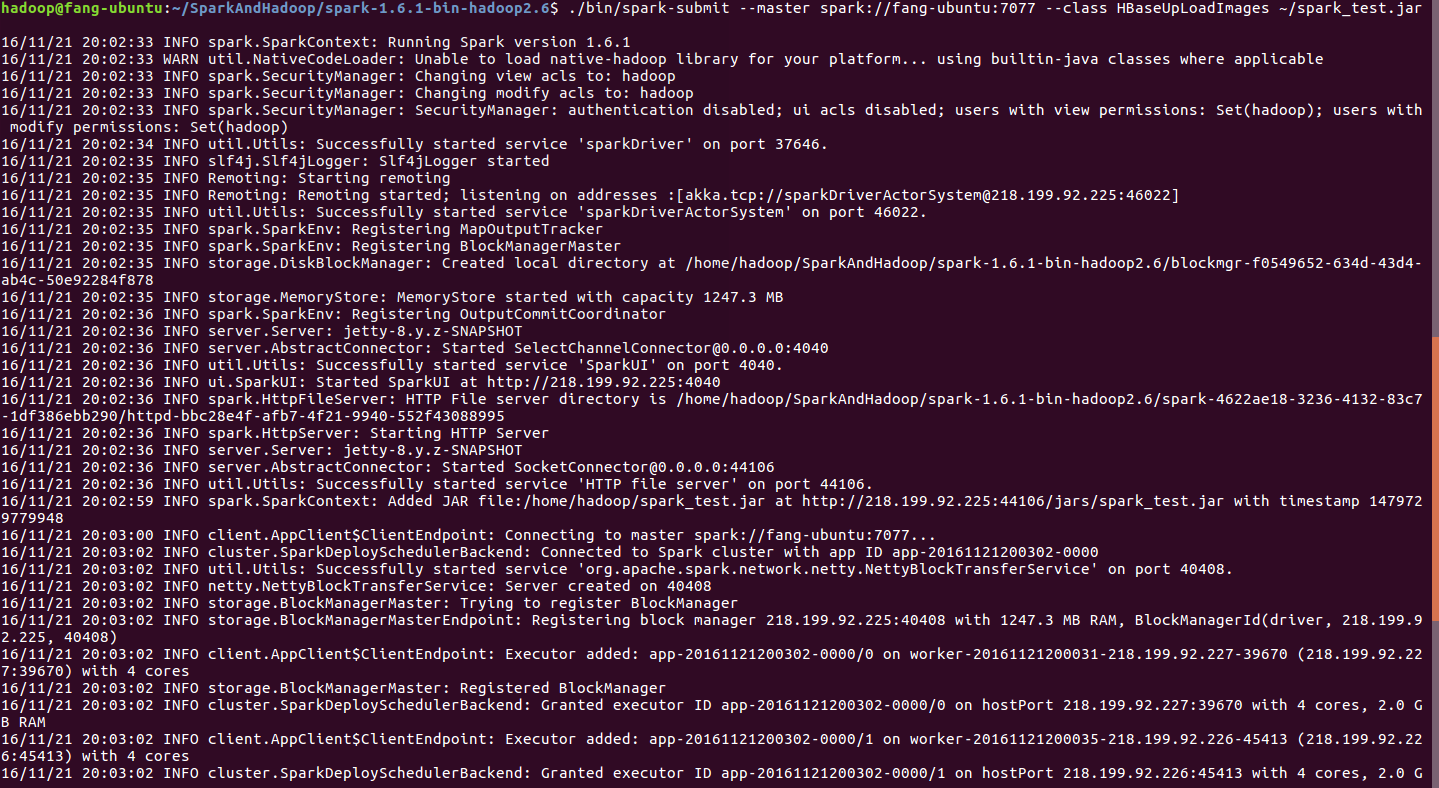
程序提交启动过程界面图
Master节点CPU,内存使用情况
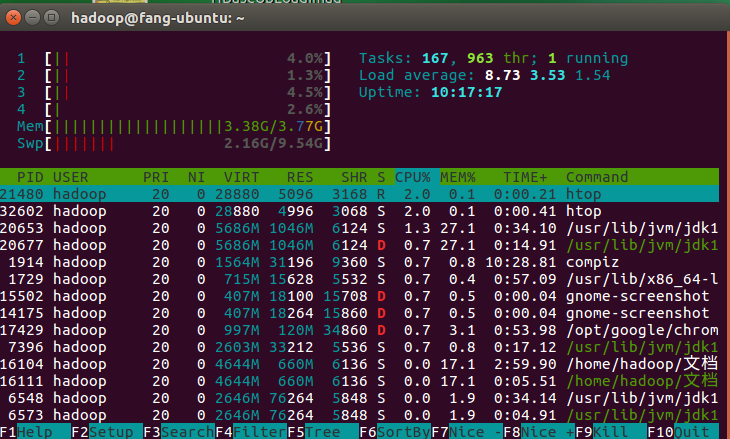
Worker节点CPU,内存使用情况

集群是两个Worker节点,一个Master节点运行
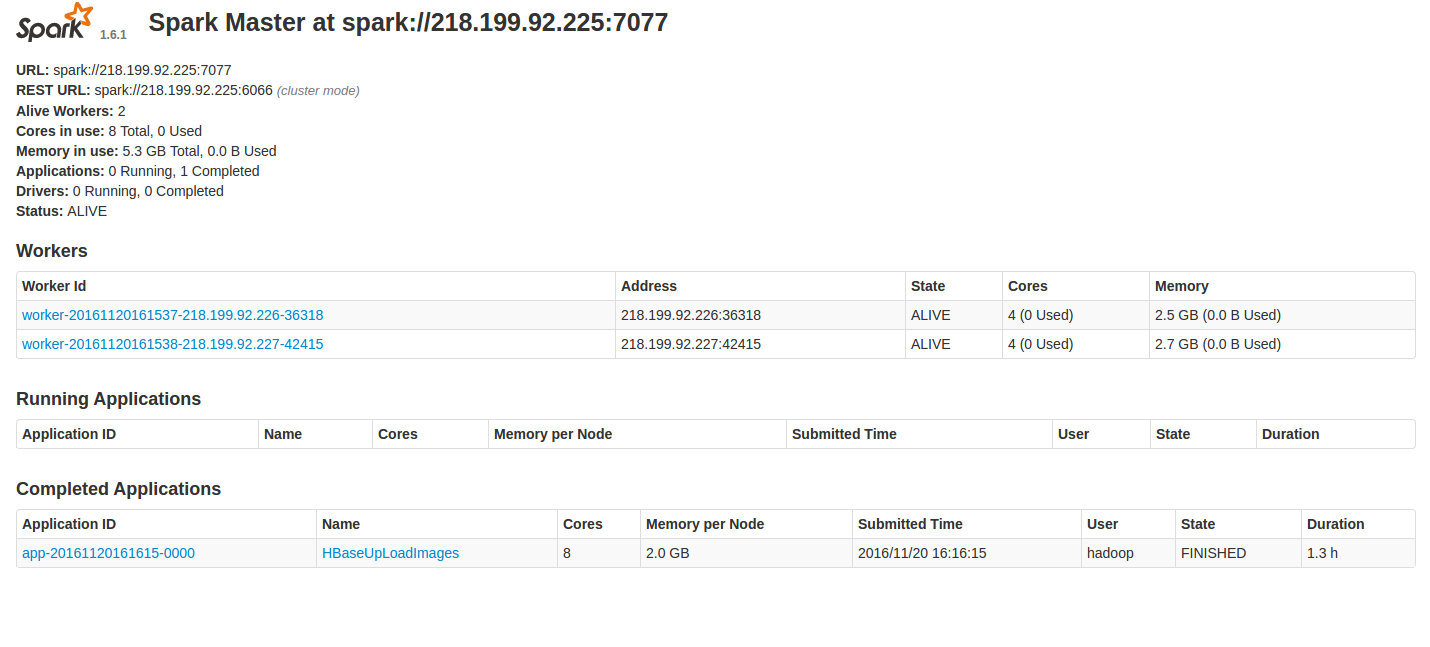
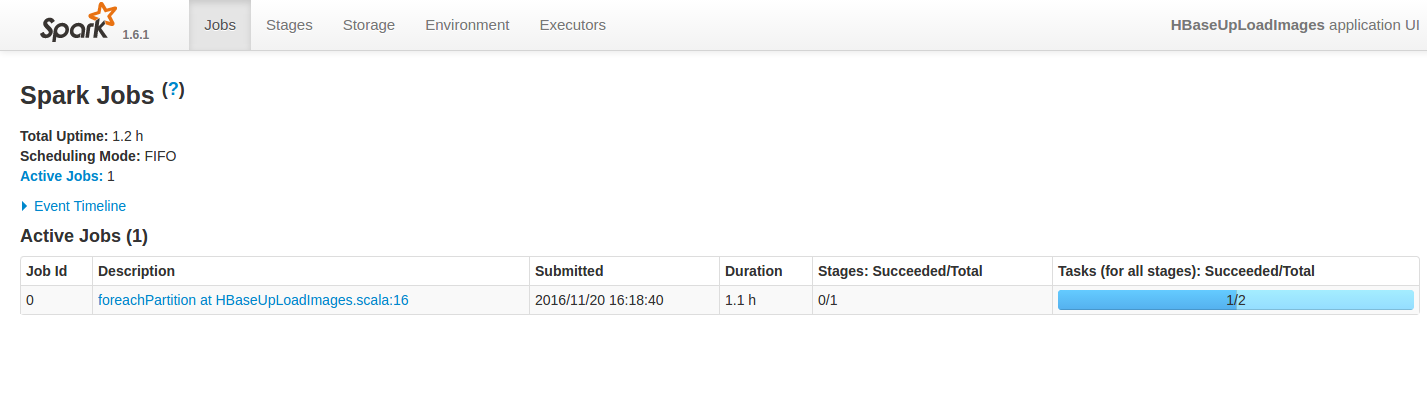
程序先上传6G的图片数据总共有50000多张图片,图中可以看出,程序花了1.1h,因此比较耗时间
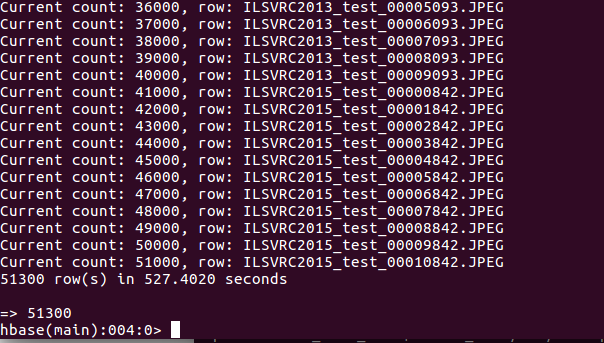
hadoop@fang-ubuntu:~/software/hbase-1.2.4$ ./bin/hbase shell
hbase(main):002:0> count ‘imagesTable’
HBase imagesTable中已经上传了51300张照片
测试中遇到的问题
- 提交作业到集群中运行出现节点失联的问题
刚开始集群配置是fang-ubuntu主节点既是Master又是Worker节点,且设置的SPARK_DRIVER_MEMORY=2G,SPARK_EXECUTOR_MEMORY=1G,导致主节点运行缓慢内存不足,而从节点内存多余,出现节点经常失联,作业未内正常运行。后来主节点只用作Master,且SPARK_EXECUTOR_MEMORY=2G后作业正常结束。 - Worker节点内存配置
Worker节点内存设置为2G,SPARK_EXECUTOR_MEMORY=2G,通过查看节点的内存使用情况,发现都达到瓶颈,且开始使用Swap空间,证明Spark集群对节点的内存要求较高。 - 本地数据文件存放
集群读取的本地文件夹/home/hadoop/test/images中的数据,如果只是Master机器中有数据则Worker节点执行是无法读取到本地文件数据而运行失败,因此,每个Worker节点下该文件夹数据都必须存在。
由于处于刚开始学习,如有错误的地方,欢迎批评指正一起讨论……
最后
以上就是清脆小白菜最近收集整理的关于Spark+HBase分布式上传海量图片数据Spark+HBase分布式批量上传海量本地图片的全部内容,更多相关Spark+HBase分布式上传海量图片数据Spark+HBase分布式批量上传海量本地图片内容请搜索靠谱客的其他文章。








发表评论 取消回复