JLD2库中,group和dataset是什么样的安排,取决于读、写的细节。
一、准备h5材料
using H5JL;
using DelimitedFiles;
using JLD2;
csv_file = "C:\Users\songroom\Desktop\000001.XSHE.csv";
jld_file = "C:\Users\songroom\Desktop\000001.h5";
# readdlm header=true,=>tuple
@time csv_data,~ = DelimitedFiles.readdlm(csv_file,',',header =true);
# @time :6.5 seconds
new_csv = H5JL.drop_array_null(csv_data); #不用管,去空格的
# 从csv=>h5_array
h5_data = H5JL.get_h5_array_from_csv_by_fullcode(new_csv,"000001.XSHG");
println("h5_data::$(size(h5_data))")
#@time h5_data = turn_larger(h5_data,20)
group_dataset_name1 = "1000.XSHG/000001.XSHG";
group_dataset_name2 = "1000.XSHG/000002.XSHG";
# write
@time H5JL.write_h5_data(jld_file,h5_data,group_dataset_name1) # 4.13s
@time H5JL.write_h5_data(jld_file,h5_data,group_dataset_name2) # 4.13s
好了,我们就生成了一个.h5文件。
二、测试JLD2的h5结构
jld_file = "C:\Users\songroom\Desktop\000001.h5";
if isfile(jld_file)
f = JLD2.jldopen(jld_file, "r+")# "r+";
else
f = JLD2.jldopen(jld_file, "w")# "r"; "w"=>覆盖了
end
1、判断文件中的基本属性
julia> isempty(f)
false
julia> f.writable #文件是否可“写”
true
julia> f.written
true
julia> f.compress
false
julia> f.mmaparrays
false
julia> f.n_times_opened
1
2、group名字
julia> keys(f.root_group)
1-element Array{String,1}:
"1000.XSHG"
3、创建新group
julia> JLD2.Group(f, "1001.XSHG")
JLD2.Group
(no datasets)
4、dataset名字
julia> datasets = keys(f["1000.XSHG"])
2-element Array{String,1}:
"000001.XSHG"
"000002.XSHG"
5、dataset取值
julia> f["1000.XSHG"]["000002.XSHG"]
589680×3 Array{Float64,2}:
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.0
⋮
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.0
0.0 0.0 0.0
6、新建dataset、赋值
(1)在“1000.XSHG”下新建000003 空的dataset,但不赋值。
julia> JLD2.Group(f, "1000.XSHG/000003")# no datasets是指下面没有dataset
JLD2.Group
(no datasets)
julia> keys(f.root_group)
1-element Array{String,1}:
"1000.XSHG"
julia> keys(f["1000.XSHG"])
3-element Array{String,1}:
"000001.XSHG"
"000002.XSHG"
"000003"
(2)还有一种方法,新建且赋值:
这种是在老group基础,创建新dataset,并赋值。
julia> f["1000.XSHG/000004"] =4
4
julia> keys(f["1000.XSHG"]) # 查看dataset已经变化
4-element Array{String,1}:
"000001.XSHG"
"000002.XSHG"
"000004"
"000003"
注意:但不能在原有的基础进行修改!
julia> f["1000.XSHG/000004"] =5
ERROR: ArgumentError: a group or dataset named 000004 is already present within this group
(3)另一个创建:要求是新的group!
julia> JLD2.Group(f, "0004.XSHG")["stock1"] = 600
600
7、如何在老的dataset上进行修改赋值、删除dataset、group?
可惜还没实现!
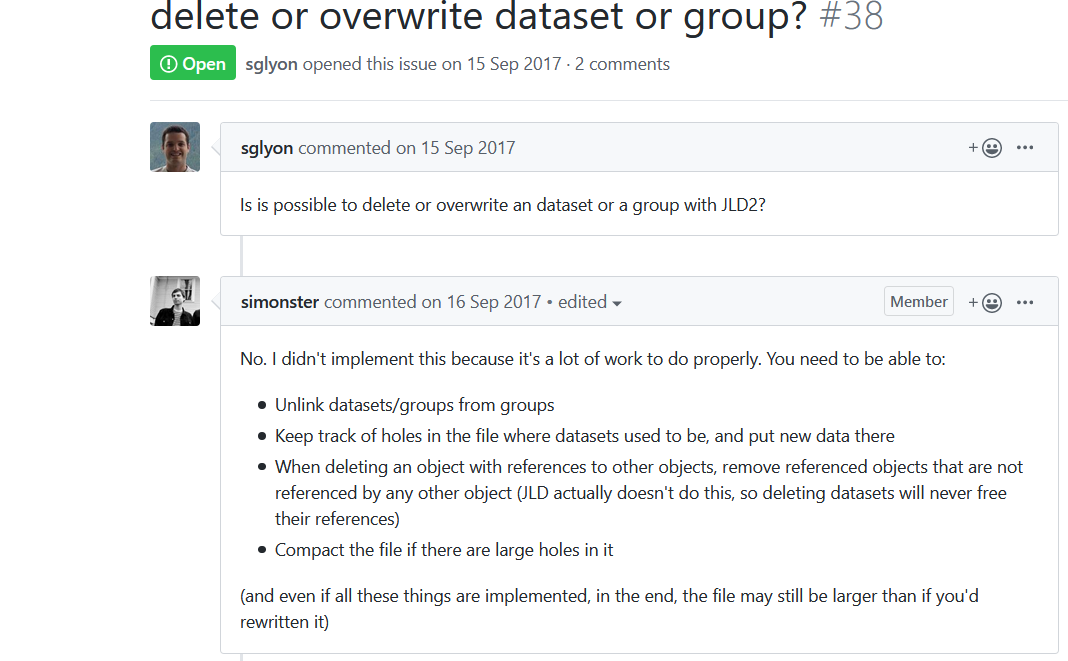 这个就说明,目前阶段,dataset不能重新赋值。如果需要重新赋值,则应先把其中的数据备份下来,删除原文件,再新建!
这个就说明,目前阶段,dataset不能重新赋值。如果需要重新赋值,则应先把其中的数据备份下来,删除原文件,再新建!
8、keys
dataset1 = "1000.XSHG/000001.XSHG"
dataset2 = "1000.XSHG/000002.XSHG"
dataset3 = "1001.XSHG"
haskey(f.root_group, dataset1)
haskey(f.root_group, dataset2)
haskey(f.root_group, dataset3)
最后
以上就是英勇航空最近收集整理的关于Julia : HDF5、JLD2库、group、dataset的全部内容,更多相关Julia内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复