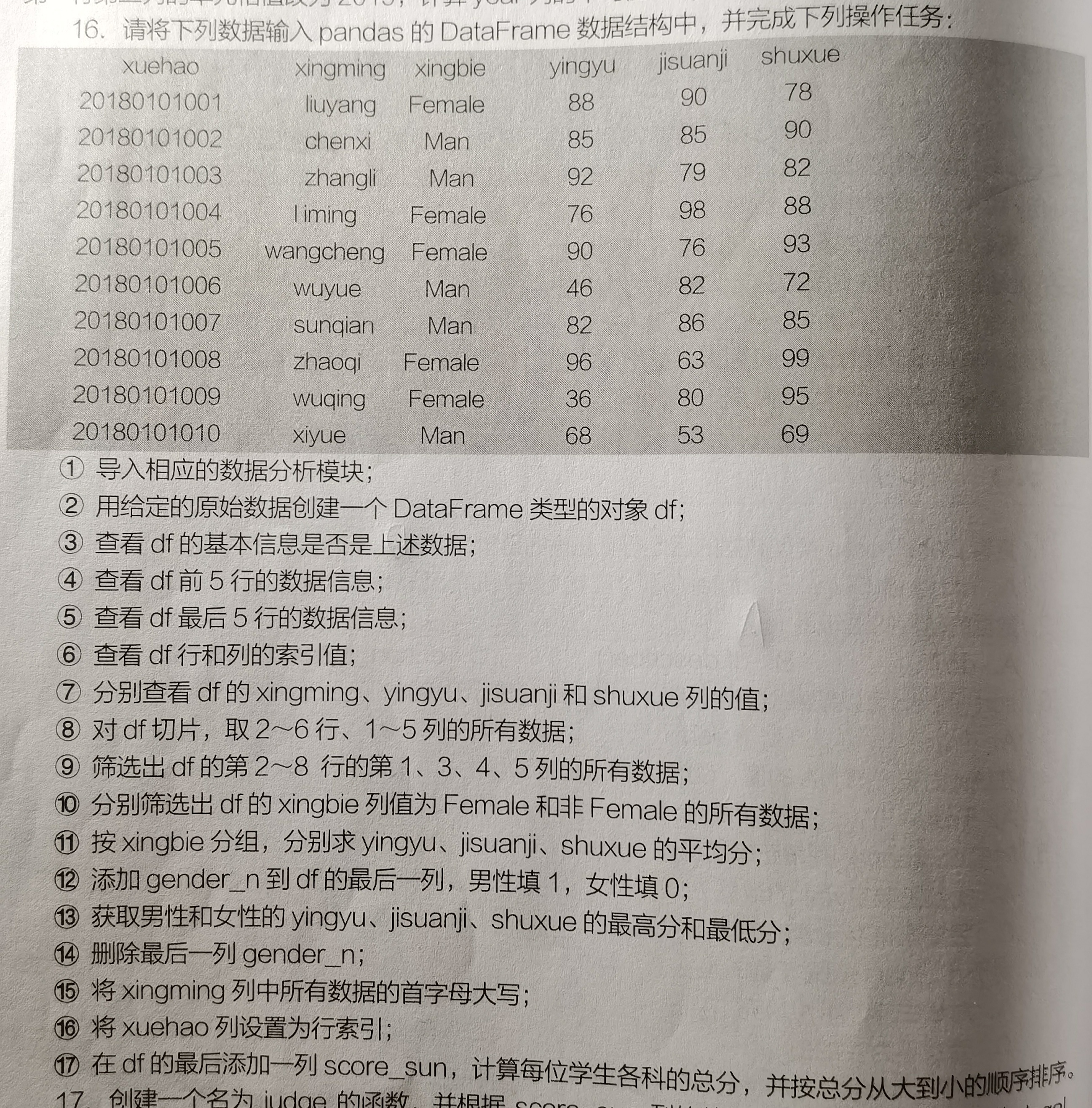
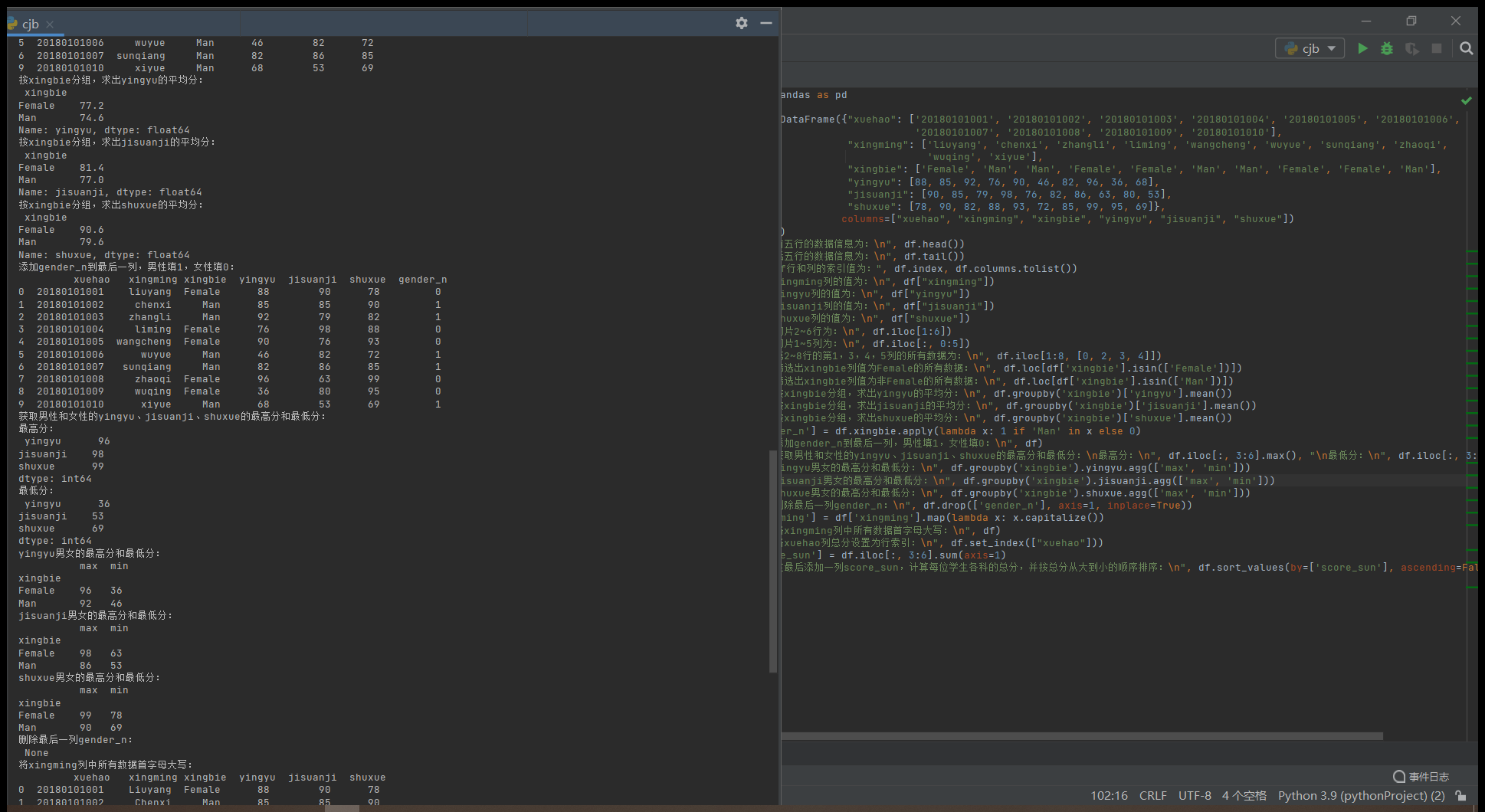
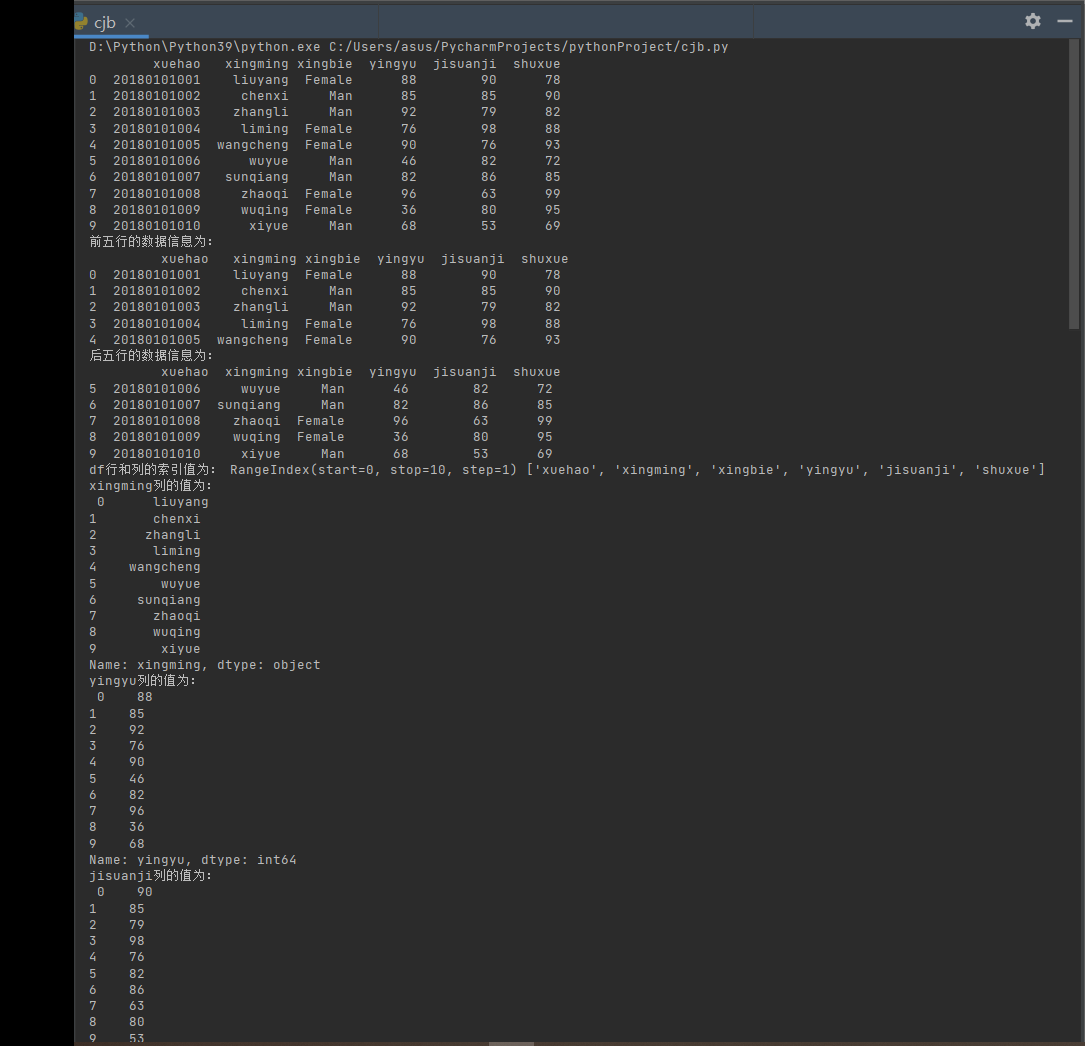
创建dateframe数据结构,并完成以下操作任务,详细题目如下图所示:
import pandas as pd
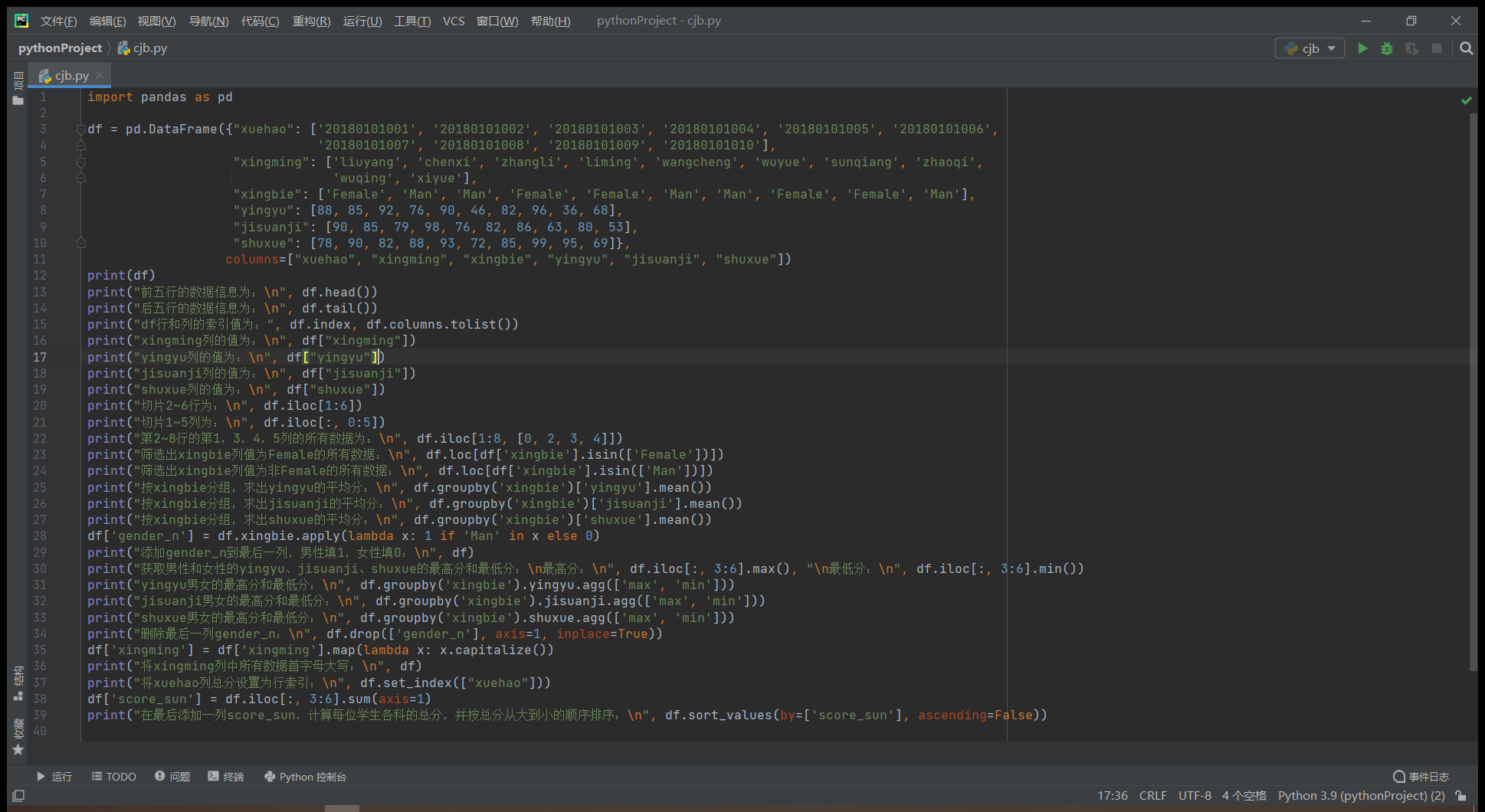
df = pd.DataFrame({"xuehao": ['20180101001', '20180101002', '20180101003', '20180101004', '20180101005', '20180101006',
'20180101007', '20180101008', '20180101009', '20180101010'],
"xingming": ['liuyang', 'chenxi', 'zhangli', 'liming', 'wangcheng', 'wuyue', 'sunqiang', 'zhaoqi',
'wuqing', 'xiyue'],
"xingbie": ['Female', 'Man', 'Man', 'Female', 'Female', 'Man', 'Man', 'Female', 'Female', 'Man'],
"yingyu": [88, 85, 92, 76, 90, 46, 82, 96, 36, 68],
"jisuanji": [90, 85, 79, 98, 76, 82, 86, 63, 80, 53],
"shuxue": [78, 90, 82, 88, 93, 72, 85, 99, 95, 69]},
columns=["xuehao", "xingming", "xingbie", "yingyu", "jisuanji", "shuxue"])
print(df)
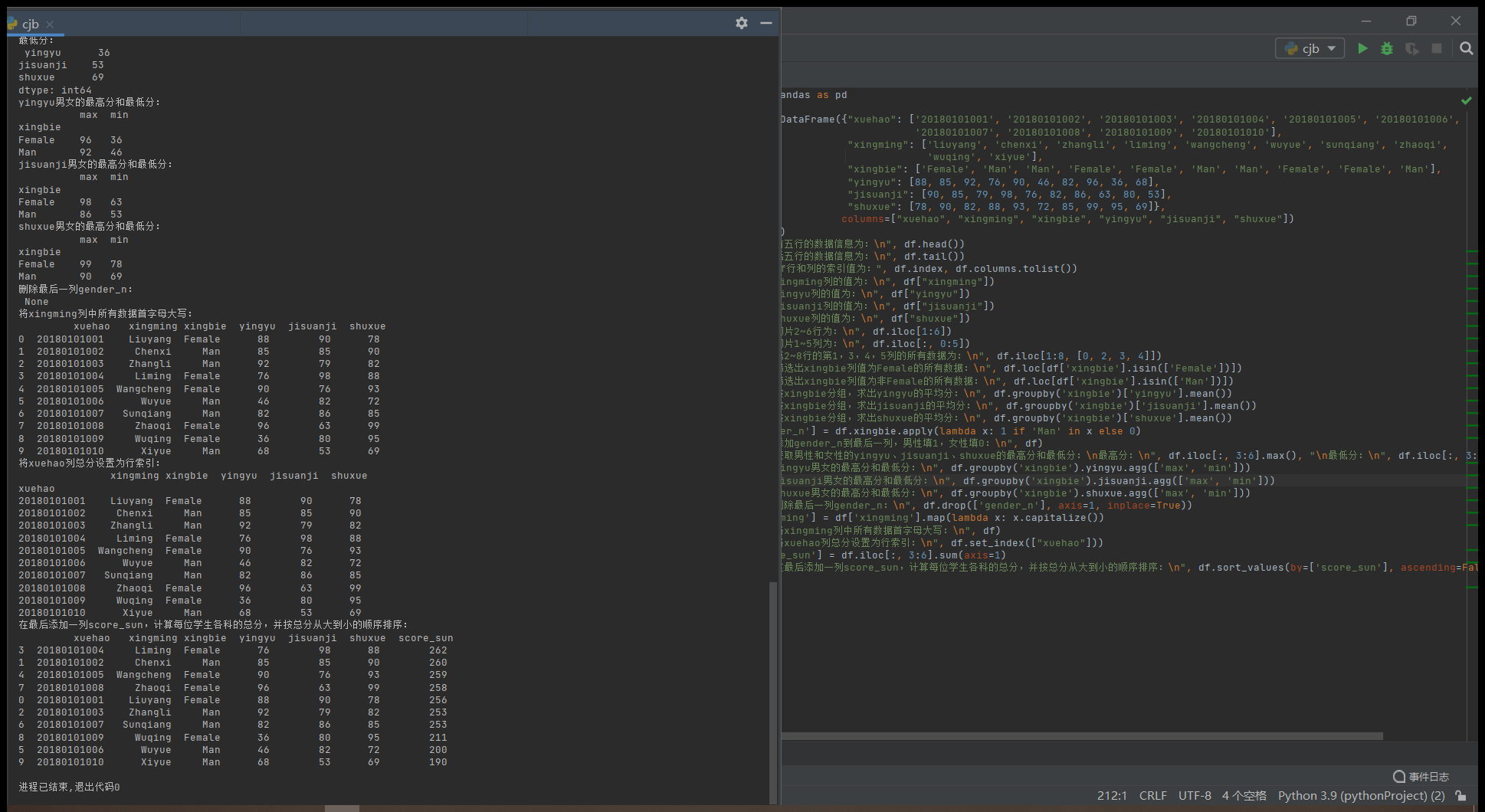
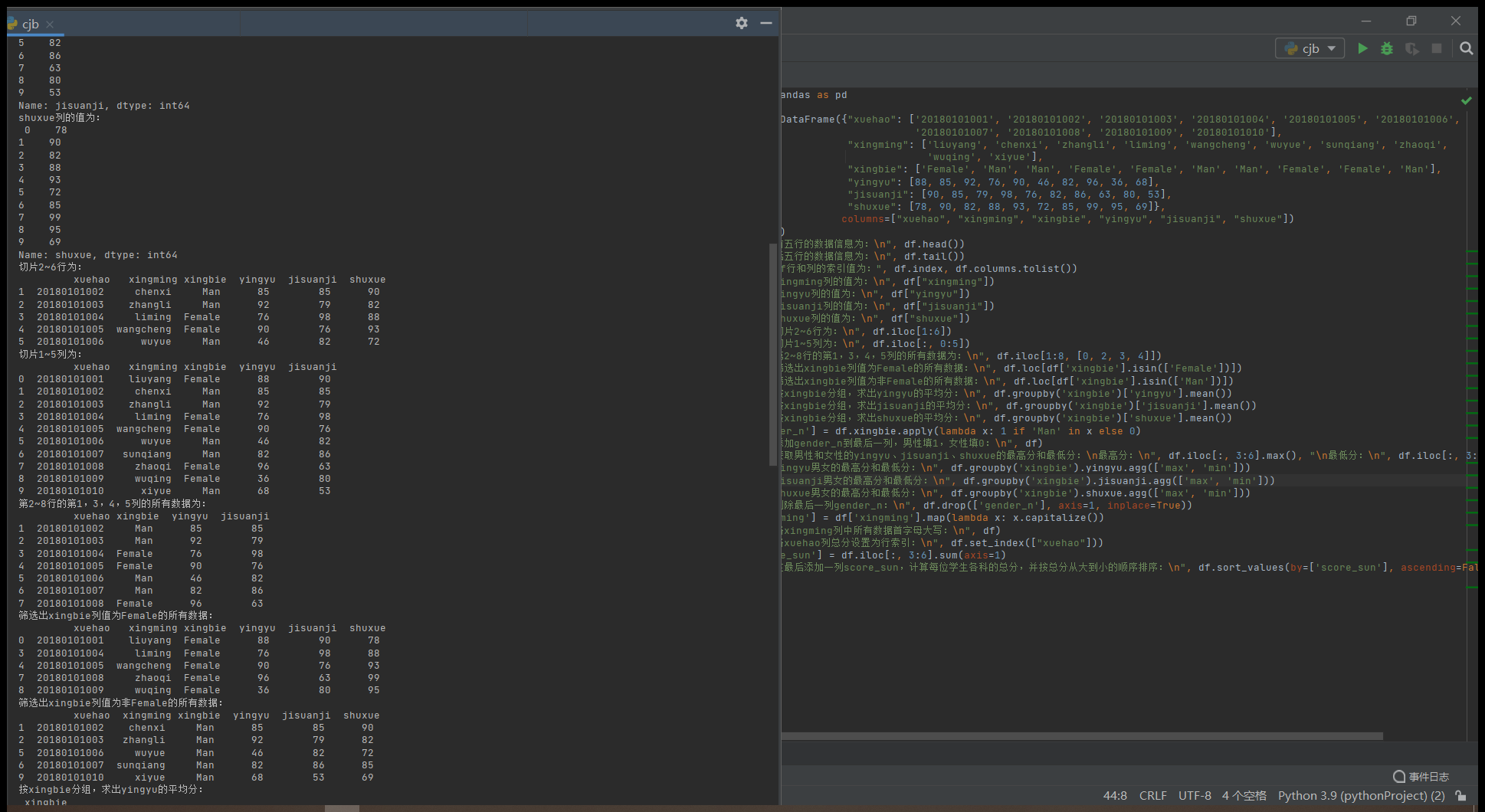
print("前五行的数据信息为:n", df.head())
print("后五行的数据信息为:n", df.tail())
print("df行和列的索引值为:", df.index, df.columns.tolist())
print("xingming列的值为:n", df["xingming"])
print("yingyu列的值为:n", df["yingyu"])
print("jisuanji列的值为:n", df["jisuanji"])
print("shuxue列的值为:n", df["shuxue"])
print("切片2~6行为:n", df.iloc[1:6])
print("切片1~5列为:n", df.iloc[:, 0:5])
print("第2~8行的第1,3,4,5列的所有数据为:n", df.iloc[1:8, [0, 2, 3, 4]])
print("筛选出xingbie列值为Female的所有数据:n", df.loc[df['xingbie'].isin(['Female'])])
print("筛选出xingbie列值为非Female的所有数据:n", df.loc[df['xingbie'].isin(['Man'])])
print("按xingbie分组,求出yingyu的平均分:n", df.groupby('xingbie')['yingyu'].mean())
print("按xingbie分组,求出jisuanji的平均分:n", df.groupby('xingbie')['jisuanji'].mean())
print("按xingbie分组,求出shuxue的平均分:n", df.groupby('xingbie')['shuxue'].mean())
df['gender_n'] = df.xingbie.apply(lambda x: 1 if 'Man' in x else 0)
print("添加gender_n到最后一列,男性填1,女性填0:n", df)
print("获取男性和女性的yingyu、jisuanji、shuxue的最高分和最低分:n最高分:n", df.iloc[:, 3:6].max(), "n最低分:n", df.iloc[:, 3:6].min())
print("yingyu男女的最高分和最低分:n", df.groupby('xingbie').yingyu.agg(['max', 'min']))
print("jisuanji男女的最高分和最低分:n", df.groupby('xingbie').jisuanji.agg(['max', 'min']))
print("shuxue男女的最高分和最低分:n", df.groupby('xingbie').shuxue.agg(['max', 'min']))
print("删除最后一列gender_n:n", df.drop(['gender_n'], axis=1, inplace=True))
df['xingming'] = df['xingming'].map(lambda x: x.capitalize())
print("将xingming列中所有数据首字母大写:n", df)
print("将xuehao列总分设置为行索引:n", df.set_index(["xuehao"]))
df['score_sun'] = df.iloc[:, 3:6].sum(axis=1)
print("在最后添加一列score_sun,计算每位学生各科的总分,并按总分从大到小的顺序排序:n", df.sort_values(by=['score_sun'], ascending=False))
最后
以上就是激情鲜花最近收集整理的关于创建dateframe数据结构,并完成以下操作任务,详细题目如图所示。的全部内容,更多相关创建dateframe数据结构内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复