项目需要将富文本内容导出word,
最开始百度,找到poi导出,综合之后 就有了以下代码
public void exportWord(Integer id,HttpServletResponse response) throws Exception {
ByteArrayInputStream bais = null;
OutputStream ostream = response.getOutputStream();
try {
TBrCaseDoc doc = tBrCaseDocMapper.selectByPrimaryKey(id);
String content = "<html><body>"+doc.getContent()+"</body></html>";
bais = new ByteArrayInputStream(content.getBytes("utf-8"));
//生成word
POIFSFileSystem poifs = new POIFSFileSystem();
DirectoryEntry directory = poifs.getRoot();
directory.createDocument("exportWord", bais);
//输出文件
response.setCharacterEncoding("utf-8");
//设置word格式
String title = new String((doc.getTitle()+".docx").getBytes("utf-8"),"ISO8859-1");//解决标题中文变成下划线的问题
response.setContentType("application/msword");
response.setHeader("Content-disposition", "attachment;filename="+title);
poifs.writeFilesystem(ostream);
}catch(Exception e){
//异常处理
e.printStackTrace();
}finally {
if(bais!=null){
bais.close();
}
if(ostream!=null){
ostream.close();
}
}
初次测试成功之后就没管了,

后来正式和前端对接测试的时候发现,带有样式的导出有问题。
前端编辑是这样的

导出变成这样

无奈继续百度,都没有找到解决方案,但是偶然看到一个
“直接html文件把后缀改成doc”
于是试了一下,还成功了
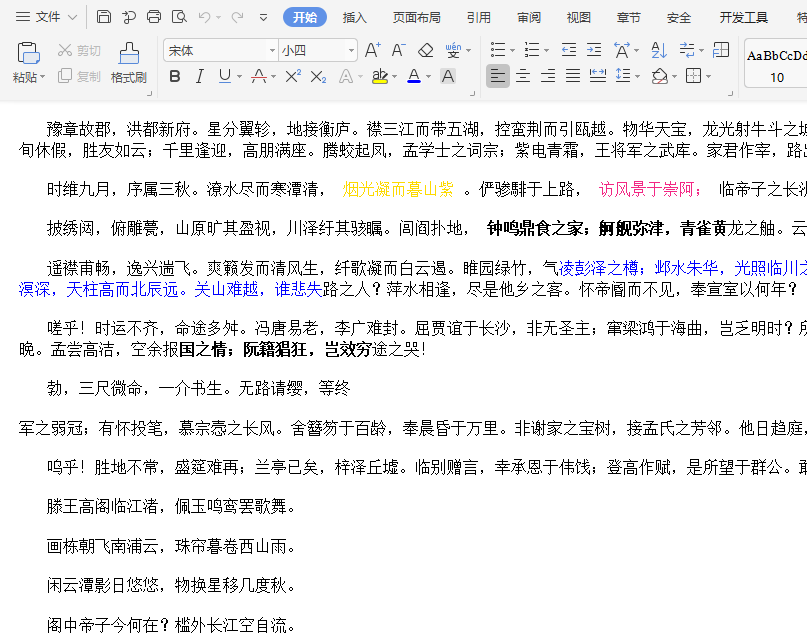
只是视图模式默认是web,貌似还差点,于是继续百度word默认打开模式
感谢这位老铁的解决方案
https://blog.csdn.net/yiyelanxin/article/details/78466872
于是修改代码为
String wordHtmlHead = "<html xmlns:v="urn:schemas-microsoft-com:vml" xmlns:o="urn:schemas-microsoft-com:office:office"n" +
"xmlns:w="urn:schemas-microsoft-com:office:word" xmlns:m="http://schemas.microsoft.com/office/2004/12/omml"n" +
"xmlns="http://www.w3.org/TR/REC-html40"><head>n" +
" <!--[if gte mso 9]><xml><w:WordDocument><w:View>Print</w:View><w:TrackMoves>false</w:TrackMoves><w:TrackFormatting/><w:ValidateAgainstSchemas/><w:SaveIfXMLInvalid>false</w:SaveIfXMLInvalid><w:IgnoreMixedContent>false</w:IgnoreMixedContent><w:AlwaysShowPlaceholderText>false</w:AlwaysShowPlaceholderText><w:DoNotPromoteQF/><w:LidThemeOther>EN-US</w:LidThemeOther><w:LidThemeAsian>ZH-CN</w:LidThemeAsian><w:LidThemeComplexScript>X-NONE</w:LidThemeComplexScript><w:Compatibility><w:BreakWrappedTables/><w:SnapToGridInCell/><w:WrapTextWithPunct/><w:UseAsianBreakRules/><w:DontGrowAutofit/><w:SplitPgBreakAndParaMark/><w:DontVertAlignCellWithSp/><w:DontBreakConstrainedForcedTables/><w:DontVertAlignInTxbx/><w:Word11KerningPairs/><w:CachedColBalance/><w:UseFELayout/></w:Compatibility><w:BrowserLevel>MicrosoftInternetExplorer4</w:BrowserLevel><m:mathPr><m:mathFont m:val="Cambria Math"/><m:brkBin m:val="before"/><m:brkBinSub m:val="--"/><m:smallFrac m:val="off"/><m:dispDef/><m:lMargin m:val="0"/> <m:rMargin m:val="0"/><m:defJc m:val="centerGroup"/><m:wrapIndent m:val="1440"/><m:intLim m:val="subSup"/><m:naryLim m:val="undOvr"/></m:mathPr></w:WordDocument></xml><![endif]-->n" +
"</head>";
@ResponseBody
@RequestMapping("/word")
public void exportWord(Integer id,HttpServletResponse response) throws Exception {
OutputStream ostream = response.getOutputStream();
try {
TBrCaseDoc doc = tBrCaseDocMapper.selectByPrimaryKey(id);
String content = wordHtmlHead+"<body>"+doc.getContent()+"</body></html>";
response.setCharacterEncoding("utf-8");
response.setContentType("application/msword");
response.setHeader("Content-disposition", "attachment;filename="+new String((doc.getTitle()+".docx").getBytes("utf-8"),"ISO8859-1"));
ostream.write(content.getBytes("utf-8"));
ostream.flush();
}catch(Exception e){
//异常处理
e.printStackTrace();
}finally {
if(ostream!=null){
ostream.close();
}
}
}
效果图
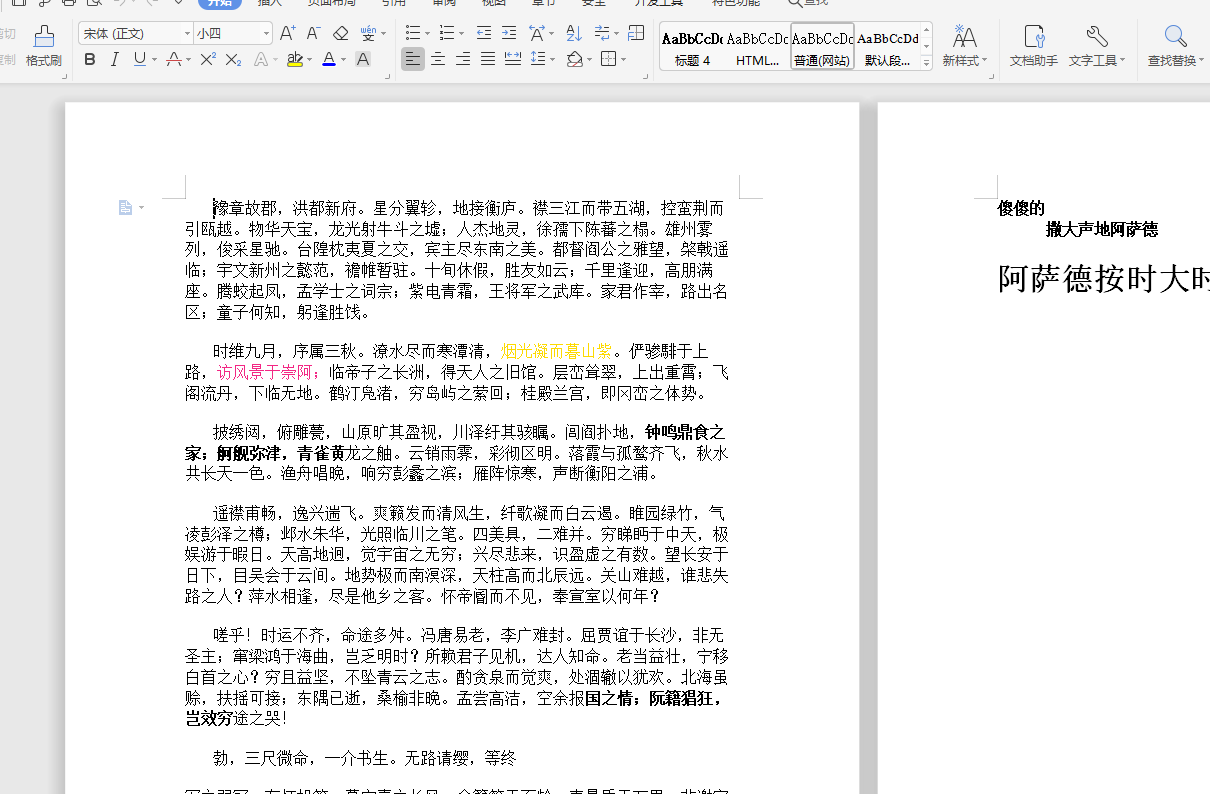
嗯,完美解决,,,(除了没解决图片问题,不过项目需求就是简单的公告文书导出,没有图片,那就不管了,感觉直接插入base64 应该可以,没试过)
最后
以上就是不安电灯胆最近收集整理的关于java html转word的坑 poi样式丢失还乱码的全部内容,更多相关java内容请搜索靠谱客的其他文章。
本图文内容来源于网友提供,作为学习参考使用,或来自网络收集整理,版权属于原作者所有。








发表评论 取消回复