文章目录
- 1. LRU 基于哈希表和双向链表的LRU算法实现
- 2. LFU(LinkedHashSet)
- 3. LRU与LFU的区别
1. LRU 基于哈希表和双向链表的LRU算法实现
缓存看这篇
LinkedHashMap的LRUCache实现
首先看一种简单的实现方式:
class LRUCache extends LinkedHashMap<Integer, Integer>{
private int capacity;
public LRUCache(int capacity) {
super(capacity, 0.75F, true);
this.capacity = capacity;
}
public int get(int key) {
return super.getOrDefault(key, -1);
}
public void put(int key, int value) {
super.put(key, value);
}
@Override
protected boolean removeEldestEntry(Map.Entry<Integer, Integer> eldest) {
return size() > capacity;
}
}
其底层就是一个hashmap加双向链表的形式。
那么我们的设计思路是,使用哈希表存储 key,值为链表中的节点,节点中存储值,双向链表来记录节点的顺序,头部为最近访问节点。
LRU算法中有两种基本操作:
get(key):查询key对应的节点,如果key存在,将节点移动至链表头部。
set(key, value): 设置key对应的节点的值。如果key不存在,则新建节点,置于链表开头。如果链表长度超标,则将处于尾部的最后一个节点去掉。如果节点存在,更新节点的值,同时将节点置于链表头部。
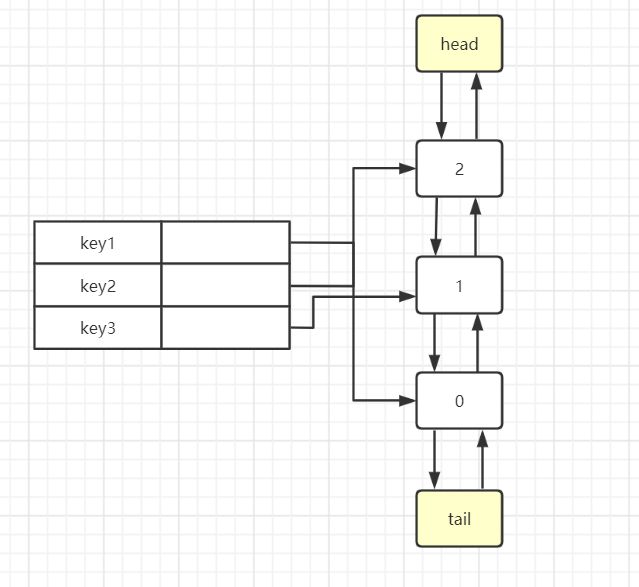
首先定义一个双向的链表结构:
public class LinkedList<T> {
LinkedList prev;
LinkedList next;
T value;
public LinkedList(T t) {
this.value = t;
}
public LinkedList() {
}
}
再在我们的cache体中定义在维护双向链表所必须的api:
public class LRU<K, V> {
private LinkedList<V> head = new LinkedList<V>();
private LinkedList<V> tail = new LinkedList<V>();
}
//移除双向链表中的结点
private void remove(LinkedList node) {
LinkedList prev = node.prev;
LinkedList next = node.next;
prev.next = next;
next.prev = prev;
}
//移除最后一个
private void removeLast() {
// 缓存页已满,移除 页尾元素
//获取 前前一个元素的指针
LinkedList temp = tail.prev.prev;
tail.prev = temp;
temp.next = tail;
}
//将结点插入头结点
private void addFirst(LinkedList node) {
//把新来的结点插入头结点
LinkedList temp = head.next;
head.next = node;
node.prev = head;
node.next = temp;
temp.prev = node;
}
随后就是整体的实现了,所作的缓存操作基本上就是命中就移除已经命中的缓存,在加入,就算是重复的也会重新创建一个结点进入头部位置:
public class LRU<K, V> {
private LinkedList<V> head = new LinkedList<V>();
private LinkedList<V> tail = new LinkedList<V>();
private int capacity;
//队列 size
private int size = 0;
private HashMap<K, LinkedList<V>> map;
public LRU(int capacity) {
this.capacity = capacity;
this.map = new HashMap<K, LinkedList<V>>(capacity);
head.next = tail;
tail.prev = head;
}
public static void main(String[] args) {
LRU<String, String> cache = new LRU<>(4);
cache.put("123", "123");
cache.put("125", "125");
cache.put("124", "124");
cache.put("123", "123 new");
cache.put("126", "126");
cache.put("126", "126 new");
cache.put("126", "126 new -v2");
cache.put("125", "125 new");
}
public void put(K k, V v) {
if (size < capacity) {
//缓存未满
if (map.containsKey(k)) {
//重复命中
remove(map.get(k));
size--;
}
LinkedList<V> node = new LinkedList<>(v);
map.put(k, node);
addFirst(node);
size++;
} else {
//缓存已满 未重复命中
if (!map.containsKey(k)) {
//将索引从map中移除 存在可优化部分,因为移除需要遍历hash表
//可将key value放入链表中,损失部分性能来提升运行效率
removeFromMap((V) tail.prev.value);
removeLast();
} else {
//重复命中 将已存在元素移到第一个
//先删除再添加
remove(map.get(k));
}
LinkedList<V> node = new LinkedList<>(v);
map.put(k, node);
addFirst(node);
}
// print();
}
private void remove(LinkedList node) {
LinkedList prev = node.prev;
LinkedList next = node.next;
prev.next = next;
next.prev = prev;
}
private void removeFromMap(V v) {
Iterator<Map.Entry<K, LinkedList<V>>> it = map.entrySet().iterator();
while (it.hasNext()) {
Map.Entry<K, LinkedList<V>> entry = it.next();
if (entry.getValue().value == v || entry.getValue().equals(v)) {
it.remove();// 使用迭代器的remove()方法删除元素
}
}
}
public V get(K k) {
if (map.containsKey(k)) {
//如果包含这个key 就将这个key插入到头部
LinkedList<V> cur = map.get(k);
remove(cur);
addFirst(cur);
print();
return cur.value;
} else {
//不包含 就return null
print();
return null;
}
}
public void print() {
LinkedList next = head;
while (next != null) {
if (next.value != null) {
System.out.println(next.value);
}
next = next.next;
}
System.out.println("------------------------");
}
private void removeLast() {
// 缓存页已满,移除 页尾元素
//获取 前前一个元素的指针
LinkedList temp = tail.prev.prev;
tail.prev = temp;
temp.next = tail;
}
private void addFirst(LinkedList node) {
//把新来的结点插入头结点
LinkedList temp = head.next;
head.next = node;
node.prev = head;
node.next = temp;
temp.prev = node;
}
}
测试结果如下:
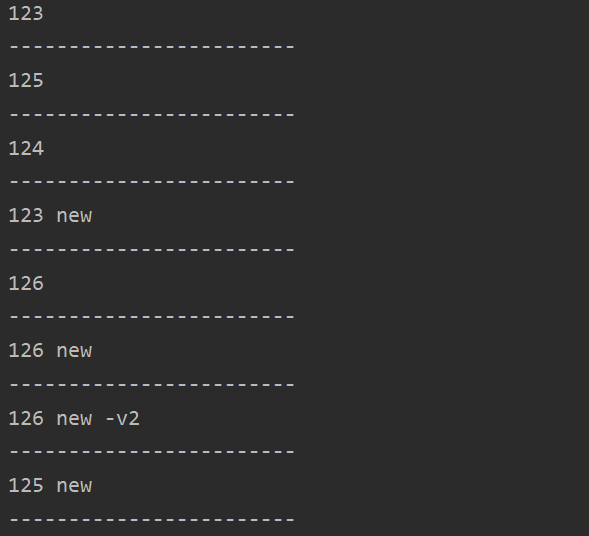
页表容量为2时:
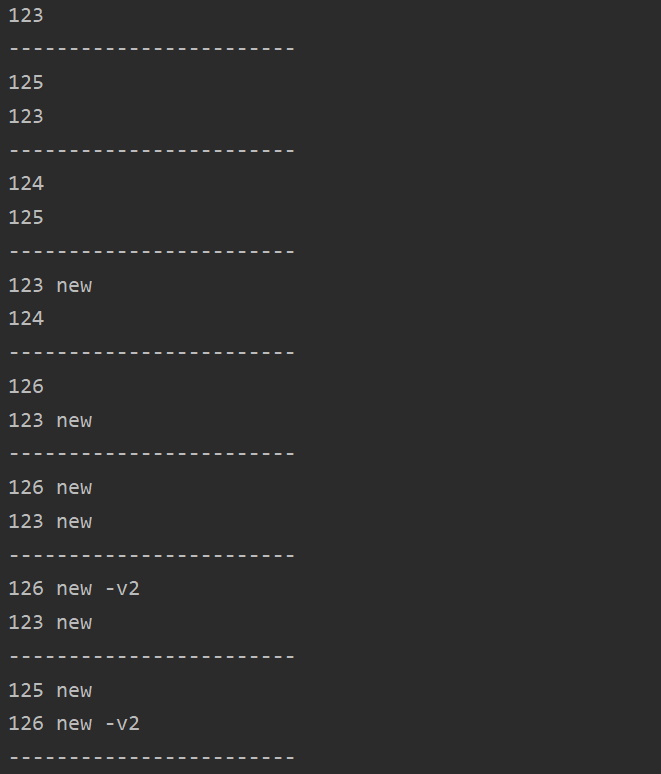
容量为8时:
2. LFU(LinkedHashSet)
可参考
LFU算法:least frequently used,最近最不经常使用算法。如果一个数据在最近一段时间很少被访问到,那么可以认为在将来它被访问的可能性也很小。因此,当空间满时,最小频率访问的数据最先被淘汰。
set(key,value):将记录(key,value)插入该结构。当缓存满时,将访问频率最低的数据置换掉。
get(key):返回key对应的value值。
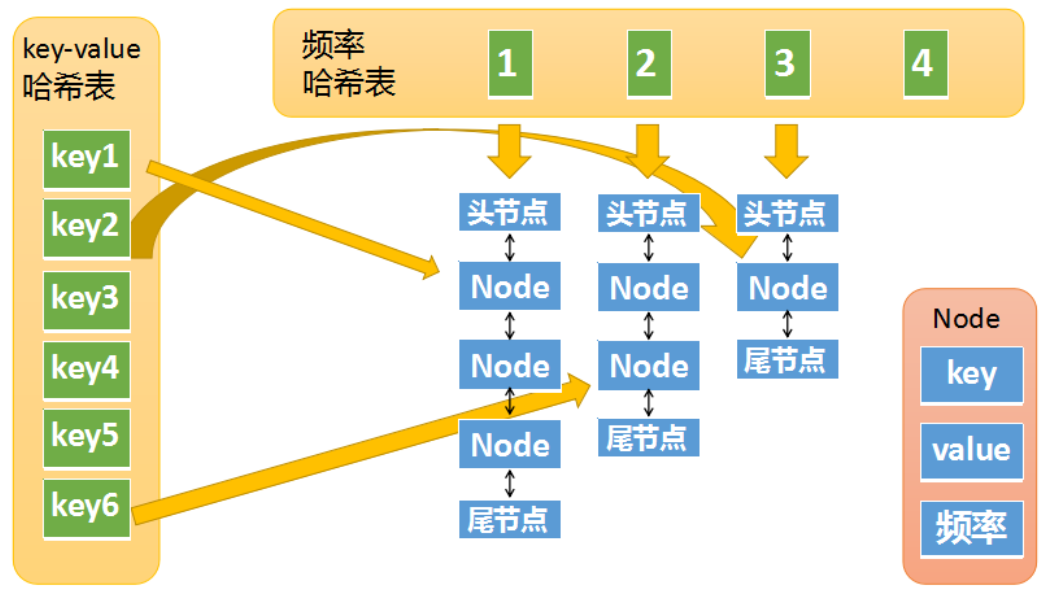
class LFUCache {
Map<Integer, Node> cache; // 存储缓存的内容
Map<Integer, LinkedHashSet<Node>> freqMap; // 存储每个频次对应的双向链表
int size;
int capacity;
int min; // 存储当前最小频次
public LFUCache(int capacity) {
cache = new HashMap<> (capacity);
freqMap = new HashMap<>();
this.capacity = capacity;
}
public int get(int key) {
Node node = cache.get(key);
if (node == null) {
return -1;
}
freqInc(node);
return node.value;
}
public void put(int key, int value) {
if (capacity == 0) {
return;
}
Node node = cache.get(key);
if (node != null) {
node.value = value;
freqInc(node);
} else {
if (size == capacity) {
Node deadNode = removeNode();
cache.remove(deadNode.key);
size--;
}
Node newNode = new Node(key, value);
cache.put(key, newNode);
addNode(newNode);
size++;
}
}
void freqInc(Node node) {
// 从原freq对应的链表里移除, 并更新min
int freq = node.freq;
LinkedHashSet<Node> set = freqMap.get(freq);
set.remove(node);
if (freq == min && set.size() == 0) {
min = freq + 1;
}
// 加入新freq对应的链表
node.freq++;
LinkedHashSet<Node> newSet = freqMap.get(freq + 1);
if (newSet == null) {
newSet = new LinkedHashSet<>();
freqMap.put(freq + 1, newSet);
}
newSet.add(node);
}
void addNode(Node node) {
LinkedHashSet<Node> set = freqMap.get(1);
if (set == null) {
set = new LinkedHashSet<>();
freqMap.put(1, set);
}
set.add(node);
min = 1;
}
Node removeNode() {
LinkedHashSet<Node> set = freqMap.get(min);
Node deadNode = set.iterator().next();
set.remove(deadNode);
return deadNode;
}
}
3. LRU与LFU的区别
贴一个leetcode上大佬的分析:
LRU (Least Recently Used)缓存机制(看时间)
在缓存满的时候,删除缓存里最久未使用的数据,然后再放入新元素;
数据的访问时间很重要,访问时间距离现在越近,就越不容易被删除;
就是喜新厌旧,淘汰在缓存里呆的时间最久的元素。在删除元素的时候,只看「时间」这一个维度。
LFU (Least Frequently Used)缓存机制(看访问次数)
在缓存满的时候,删除缓存里使用次数最少的元素,然后在缓存中放入新元素;
数据的访问次数很重要,访问次数越多,就越不容易被删除;
根据题意,「当存在平局(即两个或更多个键具有相同使用频率)时,最近最少使用的键将被去除」,即在「访问次数」相同的情况下,按照时间顺序,先删除在缓存里时间最久的数据。
核心思想:先考虑访问次数,在访问次数相同的情况下,再考虑缓存的时间。
最后
以上就是舒心酸奶最近收集整理的关于数据结构 - lru&lfu实现(Java)1. LRU 基于哈希表和双向链表的LRU算法实现2. LFU(LinkedHashSet)3. LRU与LFU的区别的全部内容,更多相关数据结构内容请搜索靠谱客的其他文章。








发表评论 取消回复